【论文阅读】A Closer Look at Spatiotemporal Convolutions for Action Recognition
这是一篇facebook的论文,它和一篇google的论文链接地址的研究内容非常相似,而且几乎是同一时刻的研究,感觉这两个公司真的冤家路窄,很有意思,但是平心而论,我感觉还是google的那篇论文写得更好一些,哈哈。
论文地址:下载地址
R(2+1)D代码(pytorch):下载地址
正文
在之前介绍的P3D中可以看到,使用2D卷积网络作用于输入视频的每一帧得到的结果也是很不错的,所以有些人可能就认为时间推理在行为识别中并不是那么重要,因为视频的帧中已经包含了行为的类别信息。所以本文就在超大的数据集kinetics上做了相关的实验,证明3DCNN确实好于2DCNN,同时虽然3DCNN好,但是看问题不能非黑即白,同时包含2D卷积核与3D卷积核的网络效果会不会更好呢?本文也做了相关的实验。同时因为之前P3D虽然提出了 因式分解卷积核 的形式,但是没有在kinetics上做相关的实验,本文同时补充了相关的实验。
实验对比网络结构
R2D和f-R2D
首先要在kinetics做2D卷积网络的对比实验,对于一段输入视频,如何使用2D卷积网络计算结果呢? 很明显有两种计算方法:
- 第一种将时间维度合并到channel维度中,比如将 的输入转变成 的输入,然后直接输入到2D卷积网络中就可以得到最后的分类结果。这种方法称为R2D。
- 第二种方法不将时间维度和channel维度合并,而是使用参数共享的2D卷积网络得到输入视频中每一帧的分类结果,最后对所有帧的结果融合得到最终的结果,这种方法称为 f-R2D 的方法。
整个R2D与 f-R2D的结构如下图所示:

R3D
然后还需要在kinetics上做3D卷积网络的对比实验,R3D是以ResNet为基础的3D卷积网络,和之前介绍的一系列(Res3D,3D-ResNets)非常相似,就不作更详细地介绍了,其具体的网络结构如下表所示:
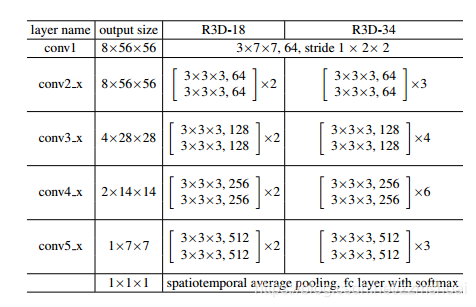
注意一下 2D downsampling 发生在conv1,而3D downsampling 发生在conv3_1, conv4_1和conv5_1即可。
MCx和rMCx
接着在kinetics上做了同时包含 2D卷积核与3D卷积核的网络的相关实验,那么一个网络中的2D卷积核和3D卷积核如何分配呢?文章提出了两种2D+3D卷积核的网络结构:
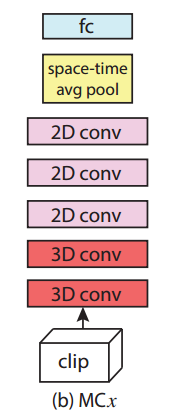
3. MCx:第一种网络结构假设在网络的底层捕获视频的局部时间运动信息是很有必要的,而在网络的顶层,对于视频的语义抽象信息,仅仅需要2D卷积即可,这种底层为3D卷积核而顶层为2D卷积核的网络称为MC网络,MCx表示表示从顶层开始,前 x 层为2D卷积核。其结构如下图所示:
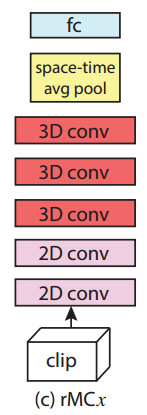
4. rMCx:第二种网络结构的假设与第一种恰恰相反,这种底层为2D卷积核而顶层为3D卷积核的网络称为 rMC网络,rMCx表示表示从顶层开始,前 x 层为3D卷积核。其结构如下图所示:
R(2+1)D 网络
最后在kinetics上做了因式分解卷积核
的相关实验,其因式分解的示意图如下图所示:
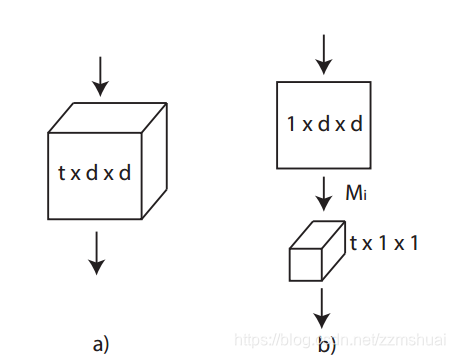
在P3D中使用的是基于 residual bottleneck block的残差结构,本文中使用的是基本的残差结构,不包含bottleneck。同时为了使分解后的 R(2+1)D 核 和原3D卷积核的参数量大体相同,本文让上图中的Mi值等于

其中Mi表示2D卷积核的个数(输出channel),d为3D卷积核的空间尺寸(宽和高),t为3D卷积核的时间尺寸,
为3D卷积核的输入channel,
为3D卷积核的个数(输出channel),其推导过程如下:
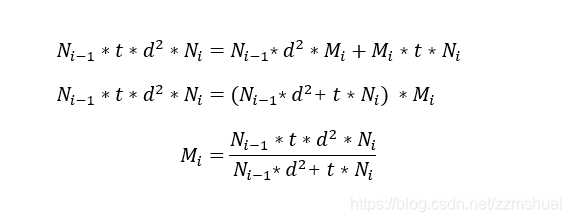
本文认为使用因式分解卷积核有以下两个优点:
5. 增加了额外的非线性映射,提高了网络的表示能力。
6. 使得网络的参数更加容易优化,在参数量相同的情况下,(2+1)D获得的训练损失和测试损失更低。网络层数越深,效果差距越明显。
实验结果
各种结构网络的实验结果对比
上述网络结构的结果如下表所示:
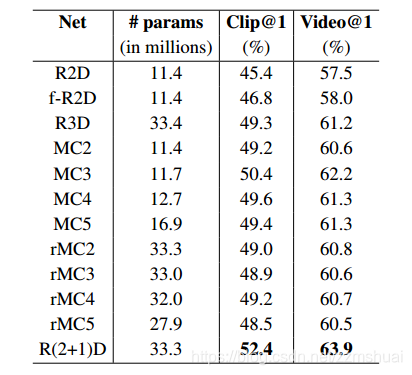
可以看到:
- 在大数据集kinetics上,R3D的结果要明显好于R2D和rR2D,捕获视频中的时间运动信息还是非常重要的。
- 因式分解R(2+1)D网络的效果是所有网络结构中最好的,
- MCx的效果要稍微好于rMCx,所以文章认为在底层对时间运动信息编码的效果要好于在顶层对时间运动信息编码,但是,谷歌的那篇论文中得到了相反的结论!两者实验的区别是本文基于Res3D网络做的实验,而谷歌那篇基于I3D做的实验,我个人感觉谷歌那篇的结论更靠谱!
各种结构网络的计算效率与准确率
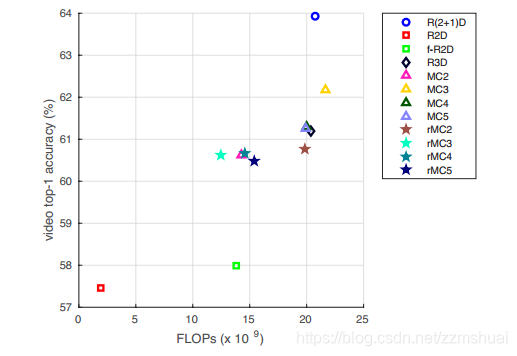
同时文章给出了上述各种网络的计算效率与其在kinetics上的准确率的关系,如下图所示:
R(2+1)D与R3D的训练误差比较
之前文章在介绍R(2+1)D时认为将3D卷积核因式分解为2D+1D的形式更有利于网络的优化,所以文章同时给出了R(2+1)D与R3D的训练损失比较,如下图所示:
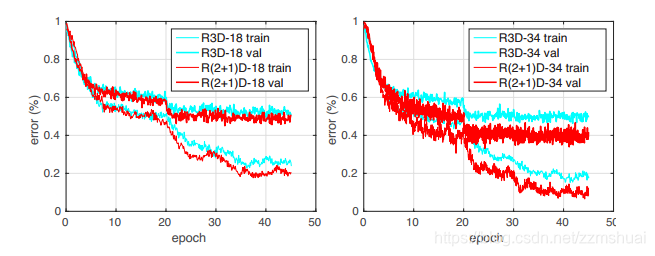
可以看到R(2+1)D有更小的训练误差,所以说R(2+1)D网络更加容易优化,并且网络的深度越深,效果越明显。
长时输入对结果的影响?
根据之前介绍的LTC的思想,对长时输入也做了实验,分别测试了 8, 16, 24, 32, 40, 和 48帧输入下的结果,如下图所示:
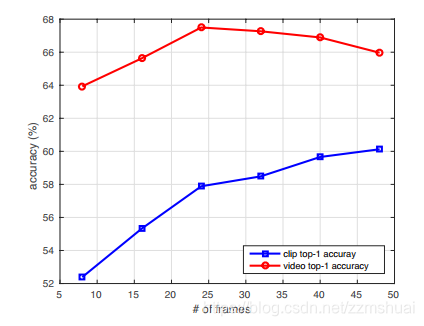
可以看到很有意思的现象是随着输入帧的增加,clip的结果更好,但是video的结果上升到一定程度会开始变差了(video的结果是该video对应的几个clip结果的平均)。所以作者思考是什么造成了clip和video之间的差异呢?为此,作者做了两个相关的实验,1.在8帧的输入上训练,在32帧的输入上测试,发现clip准确率会降低2.6%。2.使用在8帧上训练的模型在32帧输入上微调,准确率差不太多。但是这样的训练速度就快了。最后作者认为video下降的原因是,因为clip的准确率越来越高,clip融合的效果就不会再那么明显了。
输入的空间分辨率对结果的影响?
文章最后测试了输入分辨率对最终结果的影响,发现 224x224的输入与112x112的输入的结果差不多。我发现很多3D卷积网络的输入都是112x112,我的观点是3D卷积网络主要还是检测视频帧中角点的变化,所以视频中的边缘啥的不是那么重要,所以空间分辨率的要求就没有那么高。
最终的实验结果?
反正现在3D网络都是在kinetics上预训练,然后在ucf101和hmdb-51上微调,实验结果相差那么几个百分点也没啥意思,就不贴了。