Look Closer to See Better:Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition
2017CVPR 微软亚洲研究院梅涛研究员等人 Ora
背景
在图像识别领域,通常都会遇到给图片中的鸟类进行分类,包括种类的识别,属性的识别等内容。为了区分不同的鸟,除了从整体来对图片把握之外,更加关注的是一个局部的信息,也就是鸟的样子,包括头部,身体,脚,颜色等内容。至于周边信息,例如花花草草之类的,则显得没有那么重要,它们只能作为一些参照物。因为不同的鸟类会停留在树木上,草地上,关注树木和草地的信息对鸟类的识别并不能够起到至关重要的作用。所以,在图像识别领域引入注意力机制就是一个非常关键的技术,让深度学习模型更加关注某个局部的信息。
与一般的识别不同,细粒度图像识别(fine-grained image recognition)是应该能够进行局部定位(localizing),并且能在其从属(subordinate)类别中表征很小的视觉差异的,从而使各种应用受益,比如专家级的图像识别、图像标注等等。
举个例子
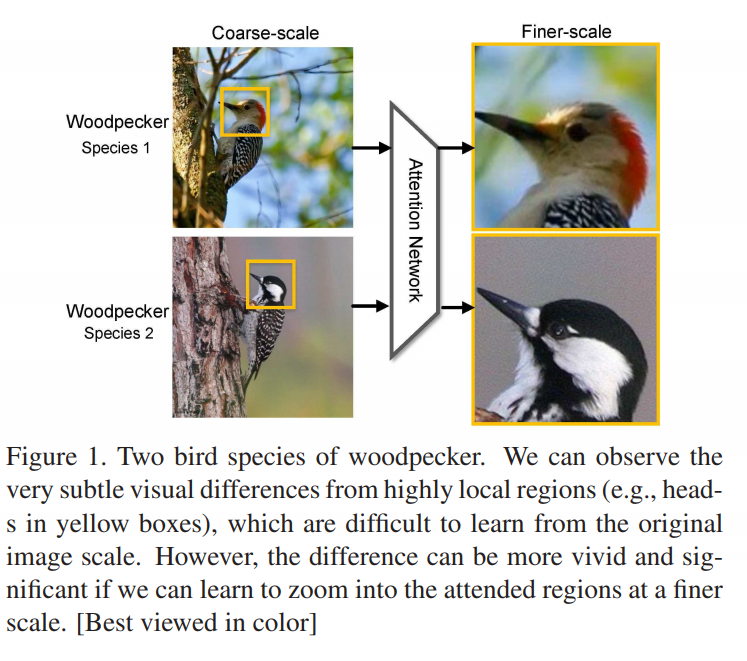
方法思路介绍
在这篇文章里面,作者们提出了一个基于 CNN 的注意力机制,叫做循环注意力卷积神经网络 (recurrent attention convolutional neural network RA-CNN),用互相强化的方式对判别区域注意力(discriminative region attention)和基于区域的特征表征(region-based feature representation)进行递归学习。在每一尺度规模上进行的学习都包含一个分类子网络(classification sub-network)和一个注意力建议子网络(attention proposal sub-network——APN)。APN 从完整图像开始,通过把先期预测作为参考,由粗到细迭代地生成区域注意力,同时精调器尺度网络(finer scale network)以循环的方式从先前的尺度规格输入一个放大的注意区域(amplified attended region)。RA-CNN 通过尺度内分类损失(intra-scale classification loss)和尺度间排序损失(inter-scale ranking loss)进行优化,以相互学习精准的区域注意力和细粒度表征。RA-CNN 并不需要边界框或边界部分的标注,而且可以进行端到端的训练。
模型介绍
总体模型:RA-CNN
从深度学习的网络结构来看,RA-CNN 的输入是整幅图片(Full Image),输出的时候就是分类的概率。该模型递归地分析局部信息,把 Attention 机制加入到整个网络结构中,从局部的信息中提取必要的特征,即为(Attention Proposal Sub-Network),让整个网络结构不仅关注整体信息,还关注局部信息。同时,在 RA-CNN 中的子网络中存在分类结构即为(classification sub-network),也就是说从不同区域的图片里面,都能够得到一个对鸟类种类划分的概率。
从下图来看,一开始,整幅图片从上方输入,然后判断出一个分类概率;
然后中间层输出一个坐标值和尺寸大小,其中坐标值表示的是子图的中心点,尺寸大小表示子图的尺寸。
这种基础上,下一幅子图就是从坐标值和尺寸大小得到的图片,第二个网络就是在这种基础上构建的;再迭代持续放大图片,从而不停地聚焦在图片中的某些关键位置。
不同尺寸的图片都能够输出不同的分类概率,再将其分类概率进行必要的融合,最终的到对整幅图片的鸟类识别概率。
RA-CNN 的特点是进行一个端到端的优化,并不需要提前标注 box,区域等信息就能够进行鸟类的识别和图像种类的划分。
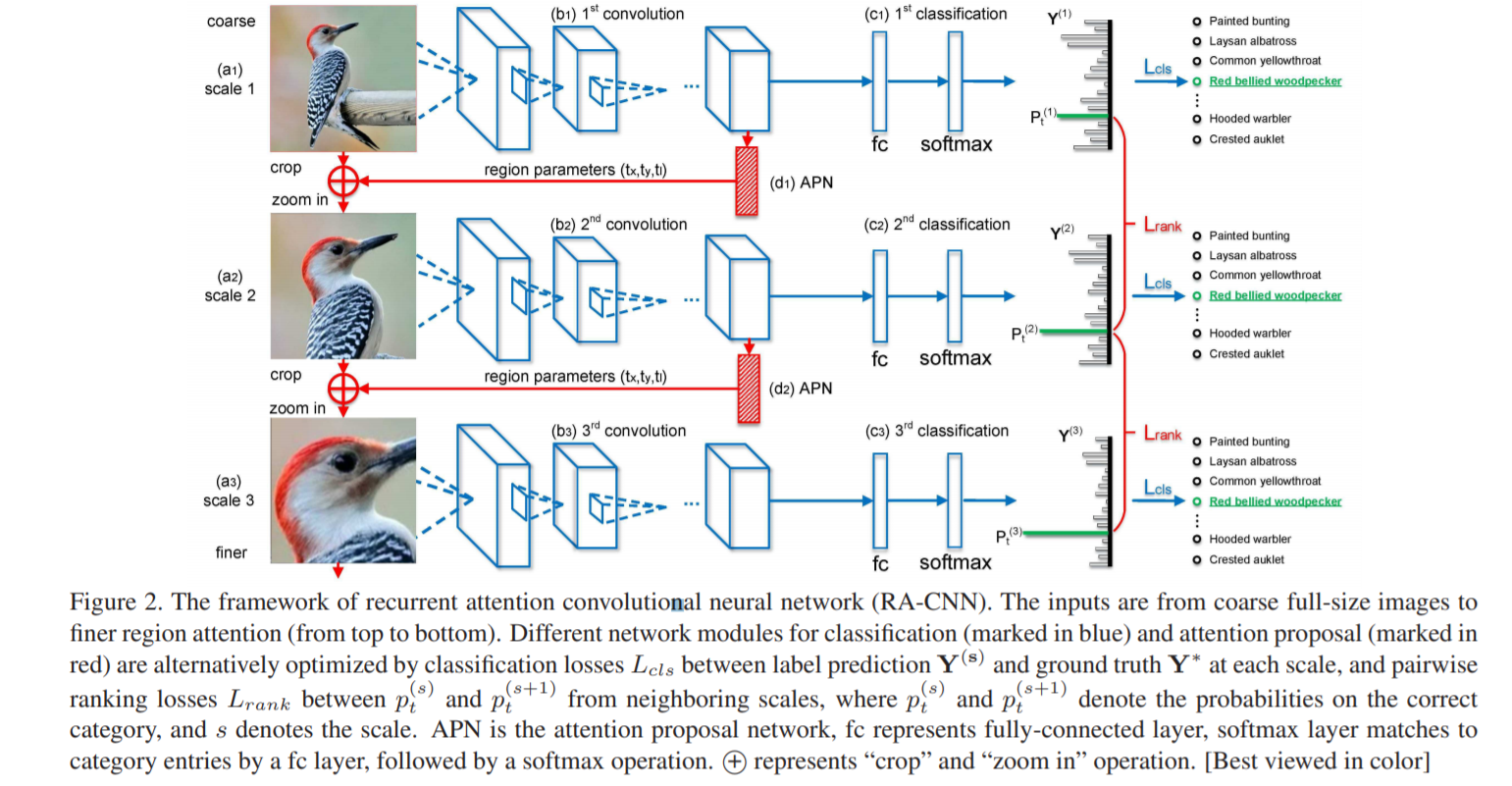
分类子网络:classification sub-network
不同的网络分类模块(蓝色部分)通过同一尺度的标注预测 Y ( s ) Y(s) Y(s) 和真实 Y ∗ Y∗ Y∗ 之间的分类损失 L c l s L_{cls} Lcls 进行优化。fc 代表全连接层,softmax 层通过 fc 层与类别条目(category entry)匹配,然后进行 softmax 操作。
RA-CNN中每一行都包含一个分类子网络:
p ( X ) = f ( W c ∗ X ) \mathbf{p}(\mathbf{X})=f\left(\mathbf{W}_{c} * \mathbf{X}\right) p(X)=f(Wc∗X)
W c W_c Wc表示整体参数, ∗ * ∗表示一系列卷积、池化和激活操作, f ( ⋅ ) f(\cdot) f(⋅)表示全连接层将关联特征映射到可与类别条目匹配的特征向量,并包含一个
softmax层进一步将特征向量转换为概率 p p p。

多尺度分类结果的结合
将多个尺度特征结合起来,在计算分类结果。
最后会把不同尺度的特征融合(独立归一化后拼接在一起)之后,在加上全连接层进行类别的判断,不使用
SVM的原因是希望可以达到端到端的训练效果。

注意力提议子网络:Attention Proposal Sub-Network(APN)

图片说明:区域注意力学习的相关说明。顶行指明了特定尺度下的两个典型区域输入,底行指明了反向传播到输入层的导数。黑色箭头显示了 t x t_x tx、 t y t_y ty 和 t l t_l tl 的优化方向,与人类的感知是一致的。
这个 APN 结构是从整个图片(full-image)出发,迭代式地生成子区域,并且对这些子区域进行必要的预测,并将子区域所得到的预测结果进行必要的整合,从而得到整张图片的分类预测概率。
输入图像从上到下按粗糙的完整大小的图像到精炼后的区域注意力图像排列。其中 p (s) t 和 p (s+1) t 表示预测在正确类别的概率,s 代表尺度。APN 是注意力建议网络。总体模型中的 ⨁ \bigoplus ⨁ 代表剪裁(crop)和放大(zoom in)」。
注意力建议(总体结构图的红色部分)通过相邻尺度的 p t ( s ) p ^{(s)} _t pt(s) 和 p t ( s + 1 ) p ^{(s+1)}_t pt(s+1) 之间的成对排序损失 L r a n k L_{rank} Lrank(pairwise ranking loss)进行优化。 p t ( s ) p ^{(s)} _t pt(s) 代表正确分类的可能性, s s s代表不同尺度。
RA-CNN中每一行都包含一个APN网络,任务是为下一个更细尺度预测一个注意力区域的含有三个参数正方形边框坐标。
[ t x , t y , t l ] = g ( W c ∗ X ) \left[t_{x}, t_{y}, t_{l}\right]=g\left(\mathbf{W}_{c} * \mathbf{X}\right) [tx,ty,tl]=g(Wc∗X)
t x t_x tx, t y t_y ty表示正方形中心的 ( x , y ) (x,y) (x,y)像素点位置, t l t_l tl表示正方形边长的一半。 通过一个方脉冲函数实现裁剪操作使之可以反向传播,通过注意区域定位到左上坐标和右下坐标。
t o p l e f t = > t x = t x − t l , t y = t y − t l b o t t o m r i g h t = > t x = t x + t l , t y = t y + t l topleft =>t_x=t_x-t_l,t_y=t_y-t_l\\ bottomright=>t_x=t_x+t_l,t_y=t_y+t_l\\ topleft=>tx=tx−tl,ty=ty−tlbottomright=>tx=tx+tl,ty=ty+tl
计算注意力区域掩模表达式的计算局部注意力和放大策略(Attention Localization and Amplification)指的是:从上面的方法中拿到坐标值和尺寸,然后把图像进行必要的放大。为了提炼局部的信息,其实就需要在整张图片 X X X的基础上加上一个面具(Mask)。所谓面具,指的是在原始图片的基础上进行点乘 0 或者 1 的操作,把一些数据丢失掉,把一些数据留下。在图片领域,就是把周边的信息丢掉,把鸟的信息留下。但是,有的时候,如果直接进行 0 或者 1 的硬编码,会显得网络结构不够连续或者光滑,因此就有其他的替代函数。
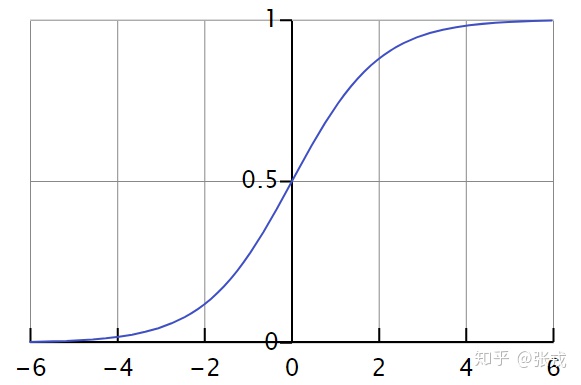
在激活函数里面,逻辑回归函数(Logistic Regression)是很常见的。其实通过逻辑回归函数,我们可以构造出近似的阶梯函数或者面具函数。
对于逻辑回归函数 σ ( x ) = 1 / ( 1 + e − k x ) \sigma(x)=1 /\left(1+e^{-k x}\right) σ(x)=1/(1+e−kx)而言,当 k k k足够大的时候,
当 x ≥ 0 x\geq 0 x≥0, σ ( x ) ≈ 1 \sigma(x) \approx 1 σ(x)≈1
当 x < 0 x < 0 x<0, σ ( x ) ≈ 0 \sigma(x) \approx 0 σ(x)≈0
此时的逻辑回归函数近似于一个阶梯函数。如果假设 x 0 < x 1 x_0<x_1 x0<x1,那么 σ ( x − x 0 ) − σ ( x − x 1 ) \sigma(x-x_0)-\sigma(x-x_1) σ(x−x0)−σ(x−x1)就是光滑一点的阶梯函数,
{ 当 x < x 0 或 者 x > x 1 , σ ( x − x 0 ) − σ ( x − x 1 ) ≈ 0 当 x 0 ≤ x ≤ x 1 , σ ( x − x 0 ) − σ ( x − x 1 ) ≈ 1 \{\begin{array}{lr}当x<x_0 或者 x>x_1, \sigma(x-x_0)-\sigma(x-x_1)\approx 0\\当x_0 \leq x\leq x_1, \sigma(x-x_0)-\sigma(x-x_1)\approx 1\\ \end{array} { 当x<x0或者x>x1,σ(x−x0)−σ(x−x1)≈0当x0≤x≤x1,σ(x−x0)−σ(x−x1)≈1
因此,基于以上的分析和假设,我们可以构造如下的函数:
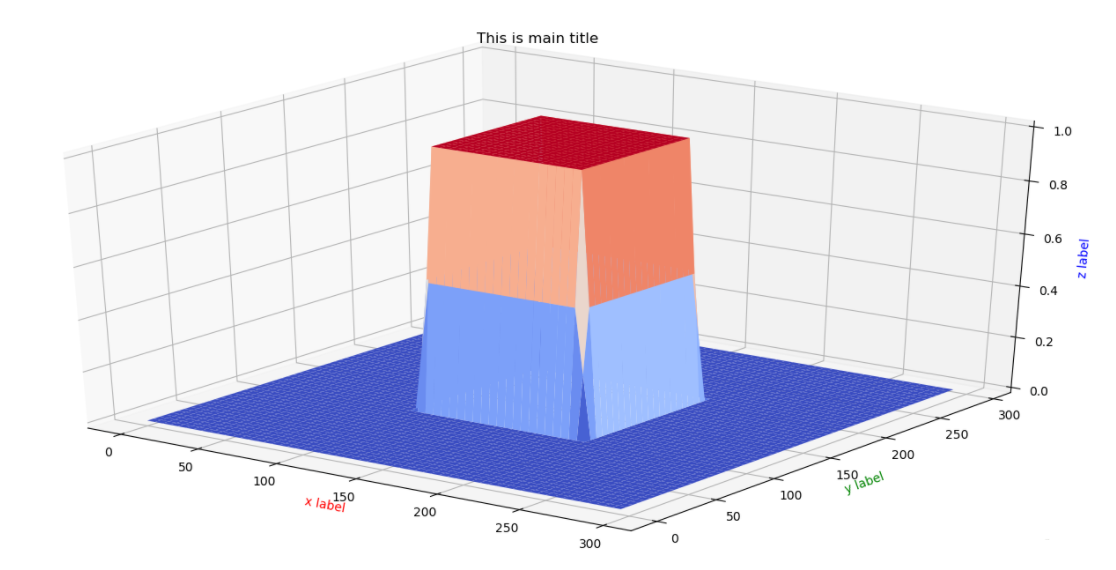
X a t t r = X ⊙ M ( t x , t y , t ℓ ) X^{a t t r}=X \odot M\left(t_{x}, t_{y}, t_{\ell}\right) Xattr=X⊙M(tx,ty,tℓ)
其中, X a t t r X^{a t t r} Xattr表示图片需要关注的区域, M ( ⋅ ) M(\cdot) M(⋅)函数就是
M ( t x , t y , t ℓ ) = [ σ ( x − t x ( t l ) ) − σ ( x − t x ( b r ) ) ] ⋅ [ σ ( y − t y ( t l ) ) − σ ( y − t y ( b r ) ) ] M\left(t_{x}, t_{y}, t_{\ell}\right) = [\sigma(x-t_{x(tl)})-\sigma(x-t_{x(br)})]\cdot[\sigma(y-t_{y(tl)})-\sigma(y-t_{y(br)})] M(tx,ty,tℓ)=[σ(x−tx(tl))−σ(x−tx(br))]⋅[σ(y−ty(tl))−σ(y−ty(br))]
这里的 σ \sigma σ函数对应了一个足够大的 k k k值。
当然,从一张完整的图片到小图片,在实际操作的时候,需要把小图片继续放大,在放大的过程中,可以考虑使用双线性插值算法来扩大。也就是说:X ( i , j ) a m p = ∑ α , β = 0 1 ∣ 1 − α − { i / λ } ∣ ⋅ ∣ 1 − β − { j / λ } ∣ ⋅ X ( m , n ) a t t X_{(i, j)}^{a m p}=\sum_{\alpha, \beta=0}^{1}|1-\alpha-\{i / \lambda\}| \cdot|1-\beta-\{j / \lambda\}| \cdot X_{(m, n)}^{a t t} X(i,j)amp=∑α,β=01∣1−α−{ i/λ}∣⋅∣1−β−{ j/λ}∣⋅X(m,n)att
,其中 m = [ i / λ ] + α , n = [ j / λ ] + β m=[i / \lambda]+\alpha, n=[j / \lambda]+\beta m=[i/λ]+α,n=[j/λ]+β, λ \lambda λ表示上采样因子, [ ⋅ ] { ⋅ } [\cdot]\{\cdot\} [⋅]{ ⋅}分别表示一个实数的正数部分和小数部分。

LOSS训练
因此,在整篇论文中,损失函数(Loss Function)里面有两个重要的部分:
- 分类概率的loss
- 成对的排序loss
共同获得更加精确注意力区域和精细特征提取
L ( X ) = ∑ s = 1 3 { L c l s ( Y ( s ) , Y ∗ ) } + ∑ s = 1 2 { L r a n k ( p t ( s ) , p t ( s + 1 ) ) } L(\mathbf{X})=\sum_{s=1}^{3}\left\{L_{c l s}\left(\mathbf{Y}^{(\mathbf{s})}, \mathbf{Y}^{*}\right)\right\}+\sum_{s=1}^{2}\left\{L_{r a n k}\left(p_{t}^{(s)}, p_{t}^{(s+1)}\right)\right\} L(X)=s=1∑3{ Lcls(Y(s),Y∗)}+s=1∑2{ Lrank(pt(s),pt(s+1))}

第一个部分就是三幅图片的 分类LOSS 函数相加 ∑ s = 1 3 { L c l s ( Y ( s ) , Y ∗ ) } \sum_{s=1}^{3}\left\{L_{c l s}\left(\mathbf{Y}^{(\mathbf{s})}, \mathbf{Y}^{*}\right)\right\} ∑s=13{ Lcls(Y(s),Y∗)},也就是所谓的intra-scale classification loss, Y ( s ) Y^{(s)} Y(s)表示预测类别的概率, Y ∗ Y^* Y∗表示真实的类别。

另外一个部分就是排序的部分, ∑ s = 1 2 { L r a n k ( p t ( s ) , p t ( s + 1 ) ) } \sum_{s=1}^{2}\left\{L_{r a n k}\left(p_{t}^{(s)}, p_{t}^{(s+1)}\right)\right\} ∑s=12{
Lrank(pt(s),pt(s+1))}
L rank ( p t ( s ) , p t ( s + 1 ) ) = max { 0 , p t ( s ) − p t ( s + 1 ) + margin } L_{\text {rank}}\left(p_{t}^{(s)}, p_{t}^{(s+1)}\right)=\max \left\{0, p_{t}^{(s)}-p_{t}^{(s+1)}+\operatorname{margin}\right\} Lrank(pt(s),pt(s+1))=max{
0,pt(s)−pt(s+1)+margin}
其中 p t ( s ) p_{t}^{(s)} pt(s)表示在第个 s s s尺寸下所得到的类别 t t t的预测概率,并且最大值函数强制了该深度学习模型在训练中可以保证 p t ( s + 1 ) > p t ( s ) + margin p_{t}^{(s+1)}>p_{t}^{(s)}+\operatorname{margin} pt(s+1)>pt(s)+margin,也就是说,局部预测的概率值应该高于整体的概率值。
解释说明 p t ( s + 1 ) p_{t}^{(s+1)} pt(s+1) 会向着 p t ( s ) + margin p_{t}^{(s)}+\operatorname{margin} pt(s)+margin更新 m a r g i n margin margin是一个裕度,在新的尺度注意力上 p t ( s + 1 ) p_{t}^{(s+1)} pt(s+1)会有更加精准的判断可能性。

在这种 Attention 机制下,可以使用训练好的 conv5_4 或者 VGG-19 来进行特征的提取。在图像领域,location 的位置是需要通过训练而得到的,因为每张图片的鸟的位置都有所不同。进一步通过数学计算可以得到, t l t_l tl会随着网络而变得越来越小,也就是一个层次递进的关系,越来越关注到局部信息的提取。简单来看,
∂ L r a n k ∂ t x ∝ D t o p ⊙ ∂ M ( t x , t y , t l ) ∂ t x \frac{\partial L_{r a n k}}{\partial t_{x}} \propto \mathbf{D}_{t o p} \odot \frac{\partial \mathbf{M}\left(t_{x}, t_{y}, t_{l}\right)}{\partial t_{x}} ∂tx∂Lrank∝Dtop⊙∂tx∂M(tx,ty,tl)
这里的 ⊙ \odot ⊙表示元素的点乘, D t o p \mathbf{D}_{t o p} Dtop表示之前的网络所得到的导数。又因为
M ( t x , t y , t ℓ ) = [ σ ( x − t x ( t l ) ) − σ ( x − t x ( b r ) ) ] ⋅ [ σ ( y − t y ( t l ) ) − σ ( y − t y ( b r ) ) ] t x ( t l ) = t x − t l t y ( t l ) = t y − t l t x ( b r ) = t x + t l t y ( b r ) = t y + t l \begin{aligned} M(t_{x}, t_{y}, t_{\ell}) &= [\sigma(x-t_{x(tl)})-\sigma(x-t_{x(br)})]\cdot[\sigma(y-t_{y(tl)})-\sigma(y-t_{y(br)})]\\ t_{x(tl)}&=t_x-t_l\\ t_{y(tl)}&=t_y-t_l\\ t_{x(br)}&=t_x+t_l\\ t_{y(br)}&=t_y+t_l\\ \end{aligned} M(tx,ty,tℓ)tx(tl)ty(tl)tx(br)ty(br)=[σ(x−tx(tl))−σ(x−tx(br))]⋅[σ(y−ty(tl))−σ(y−ty(br))]=tx−tl=ty−tl=tx+tl=ty+tl
转换为
M ( t x , t y , t ℓ ) = [ σ ( x − t x + t l ) − σ ( x − t x − t l ) ] ⋅ [ σ ( y − t y + t l ) − σ ( y − t y − t l ) ] M\left(t_{x}, t_{y}, t_{\ell}\right) = [\sigma(x-t_x+t_l)-\sigma(x-t_x-t_l)]\cdot[\sigma(y-t_y+t_l)-\sigma(y-t_y-t_l)] M(tx,ty,tℓ)=[σ(x−tx+tl)−σ(x−tx−tl)]⋅[σ(y−ty+tl)−σ(y−ty−tl)]
所以说(箭头表示趋近于)
∂ M ∂ t x = { < 0 x → t x ( t l ) > 0 x → t x ( b r ) = 0 otherwise \frac{\partial M}{\partial t_{x}}=\left\{\begin{array}{ll}<0 & x \rightarrow t_{x(t l)} \\>0 & x \rightarrow t_{x(b r)} \\ =0 & \text { otherwise }\end{array}\right. ∂tx∂M=⎩⎨⎧<0>0=0x→tx(tl)x→tx(br) otherwise
∂ M ∂ t y = { < 0 y → t y ( t l ) > 0 y → t y ( b r ) = 0 otherwise \frac{\partial M}{\partial t_{y}}=\left\{\begin{array}{ll}<0 & y \rightarrow t_{y(t l)} \\>0 & y \rightarrow t_{y(b r)} \\ =0 & \text { otherwise }\end{array}\right. ∂ty∂M=⎩⎨⎧<0>0=0y→ty(tl)y→ty(br) otherwise
∂ M ∂ t l = { > 0 x → t x ( t l ) or x → t x ( b r ) or y → t y ( b r ) or y → t y ( t l ) < 0 otherwise. \frac{\partial M}{\partial t_{l}}=\left\{\begin{array}{rr}>0 & x \rightarrow t_{x(t l)} \text { or } x \rightarrow t_{x(b r)} \\& \text { or } y \rightarrow t_{y(b r)} \text { or } y \rightarrow t_{y(t l)} \\<0 & \text { otherwise. } \end{array}\right. ∂tl∂M=⎩⎨⎧>0<0x→tx(tl) or x→tx(br) or y→ty(br) or y→ty(tl) otherwise.
因此, t l t_l tl在迭代的过程中会越来越小,也就是说关注的区域会越来越集中。
结合Fig.3分析这几个参数在实际更新时候的示例

整个网络的训练采用交替的训练策略,步骤如下:
- 初始化:直接从
ImageNet训练的VGG的参数初始化卷积网络; - 预训练APN:在卷积网络的最后一个卷积层里选取响应最大的区域作为
APN的输出区域,其中该输出区域的大小初始化为原始图像的一半。这样有了区域 [ t x , t y , t l ] [t_x,t_y,t_l] [tx,ty,tl],我们就可以预训练图中的2个APN网络 ( d 1 , d 2 ) (d_1,d_2) (d1,d2); - 交替训练:固定
APN的参数,训练卷积网络;固定卷积网络的参数,训练APN;直到两者的loss不再变化。注意,在参数 t l t_l tl的更新中,作者加入了约束,即当前尺度的 t l t_l tl大小不得小于上一尺度的 1 / 3 1/3 1/3,以保证截取区域的结构完整性。其中,截取操作采用了具有连续性质的 boxcar 函数,成对排序损失 l r a n k l_{rank} lrank对参数 [ t x , t y , t l ] [t_x,t_y,t_l] [tx,ty,tl]的求导是很容易的;有了 l r a n k l_{rank} lrank对参数 [ t x , t y , t l ] [t_x,t_y,t_l] [tx,ty,tl]的梯度,再往回传,即就是更新APN网络中2个全连接层的权重参数。
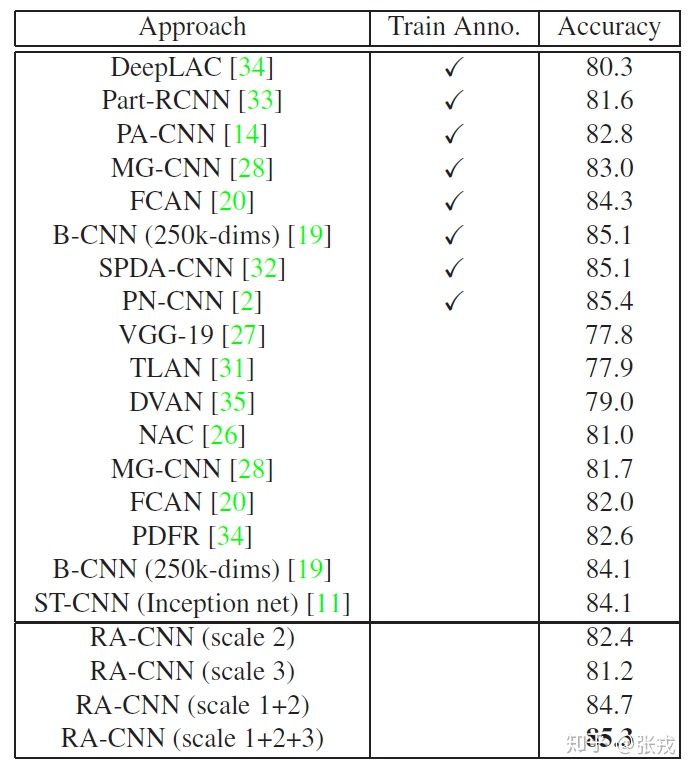
该论文采用通过尺度内分类损失(intra-scale classification loss)和尺度间排序损失(inter-scale ranking loss)进行优化,以相互学习精准的区域注意力和细粒度表征。最后的实验结果表面RA-CNN 并不需要边界框或边界部分的标注,即可达到和采用类似bounding box标注的算法效果,并且可以进行端到端的训练。
实验效果
参考文献
【计算机视觉】深入理解Attention机制_Slow down, Keep learning and Enjoy life-CSDN博客_attention机制
学界 | 微软亚洲研究院CVPR 2017 Oral论文:逐层集中Attention的卷积模型