论文下载地址:https://arxiv.org/pdf/1904.04232.pdf
源码链接:https://github.com/wyharveychen/CloserLookFewShot



运行环境:Windows10
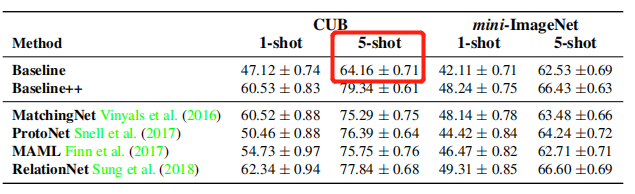
只复现源码默认的。即在CUB数据集上训练的baseline。
主要参数:
parser = argparse.ArgumentParser(description= 'few-shot script %s' %(script))
parser.add_argument('--dataset' , default='CUB', help='CUB/miniImagenet/cross/omniglot/cross_char')
parser.add_argument('--model' , default='Conv4', help='model: Conv{4|6} / ResNet{10|18|34|50|101}') # 50 and 101 are not used in the paper
parser.add_argument('--method' , default='baseline', help='baseline/baseline++/protonet/matchingnet/relationnet{_softmax}/maml{_approx}') #relationnet_softmax replace L2 norm with softmax to expedite training, maml_approx use first-order approximation in the gradient for efficiency
parser.add_argument('--train_n_way' , default=5, type=int, help='class num to classify for training') #baseline and baseline++ would ignore this parameter
parser.add_argument('--test_n_way' , default=5, type=int, help='class num to classify for testing (validation) ') #baseline and baseline++ only use this parameter in finetuning
parser.add_argument('--n_shot' , default=5, type=int, help='number of labeled data in each class, same as n_support') #baseline and baseline++ only use this parameter in finetuning
parser.add_argument('--train_aug' , action='store_true', help='perform data augmentation or not during training ') #still required for save_features.py and test.py to find the model path correctly
parser.add_argument('--num_classes' , default=200, type=int, help='total number of classes in softmax, only used in baseline') #make it larger than the maximum label value in base class
parser.add_argument('--save_freq' , default=50, type=int, help='Save frequency')
parser.add_argument('--start_epoch' , default=0, type=int,help ='Starting epoch')
parser.add_argument('--stop_epoch' , default=-1, type=int, help ='Stopping epoch') #for meta-learning methods, each epoch contains 100 episodes. The default epoch number is dataset dependent. See train.py
parser.add_argument('--resume' , action='store_true', help='continue from previous trained model with largest epoch')
parser.add_argument('--warmup' , action='store_true', help='continue from baseline, neglected if resume is true') #never used in the paper
image_size = 224
optimization = 'Adam'
遇到的问题及解决办法:
1、CUB数据集
没有数据集,需要下载数据集。
源码给的下载链接:http://www.vision.caltech.edu/visipedia-data/CUB-200-2011/CUB_200_2011.tgz
需要访问外网,当时没有找资源,就花15块钱买了一个vpn,之后可以访问该网站了,但是,提示说访问人过多或者文件太大,不给下载。15块钱打水漂了。
然后找资源,
百度网盘下载链接:https://pan.baidu.com/s/1OL3s7XmzoaYmbBocYJjYyQ
提取码:7jeb
2、代码修改
"""把反斜杠改为斜杠"""
data_path = join(cwd,'CUB_200_2011\images')
"""读json文件出现的问题,加入斜杠转义字符,让原来的斜杠存在真实意义"""
with open(data_file, encoding='utf-8') as f:
s = ""
for i in f:
s += i
s = s.replace('\\', '\\\\')
self.meta = json.loads(s)
"""
本地没有cuda,需要修改model.cuda(), 凡 **.cuda() 的都需要改成 **.to(device)
当然修改方式多种多样,本人秉持能就行的态度,这个没太大必要深究
修改如下:
"""
device = ('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
"""
baselinetrain.py 中的 for i, (x, y) in enumerate(train_loader) 不能迭代
修改方法:把datamgr.py中的SimpleDataManager类中get_data_loader函数的data_loader_params参数的内核工作数改为0
即:num_workers = 0
"""


最后测试集结果(和论文结果有误差,可能是训练测试数据划分等原因造成):