版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/liangdong2014/article/details/86144220
- 一般来说更深的网络具有更好效果,更深的网络也面临两个问题。
- 更深的网络拥有更多的参数,更容易过拟合。
- 更深的网络对计算的要求也更高。
- 针对上述问题的一个解决方法就是使用稀疏连接(convolutional layer),而不是dense connection。
- 此外,同一类的物体在不同图片中的大小差距也比较大,如下图所示,从左到右图像需要的kernel size依次递减。

- 为了解决这个问题,作者创新性的提出了不仅仅more deeper而且可以让网络更wider。也就是最原始的Inception Module,如下图所示。
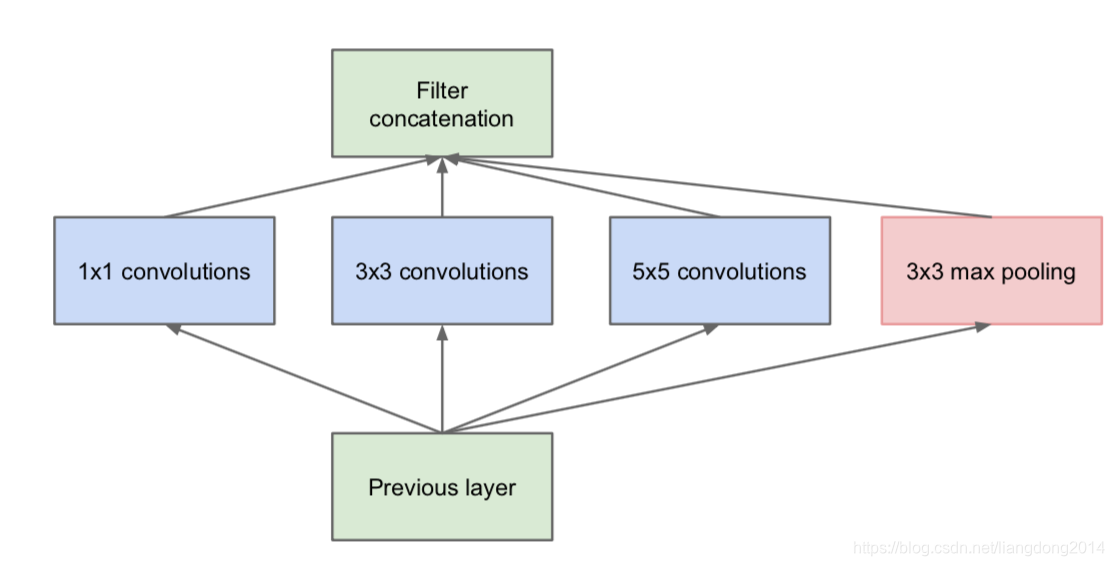
- 但是上面结构有一个致命的问题就是channel的个数会爆炸式增长,这就限制了我们网络结构不能太深,因为我们在设计网络的时候总要在channel的个数和网络的深度之间平衡。,为了解决该问题,作者使用了
的卷积来做dimension reduction。⚠️
的卷积也跟的有ReLU,这样可以提高整个模型的非线性。
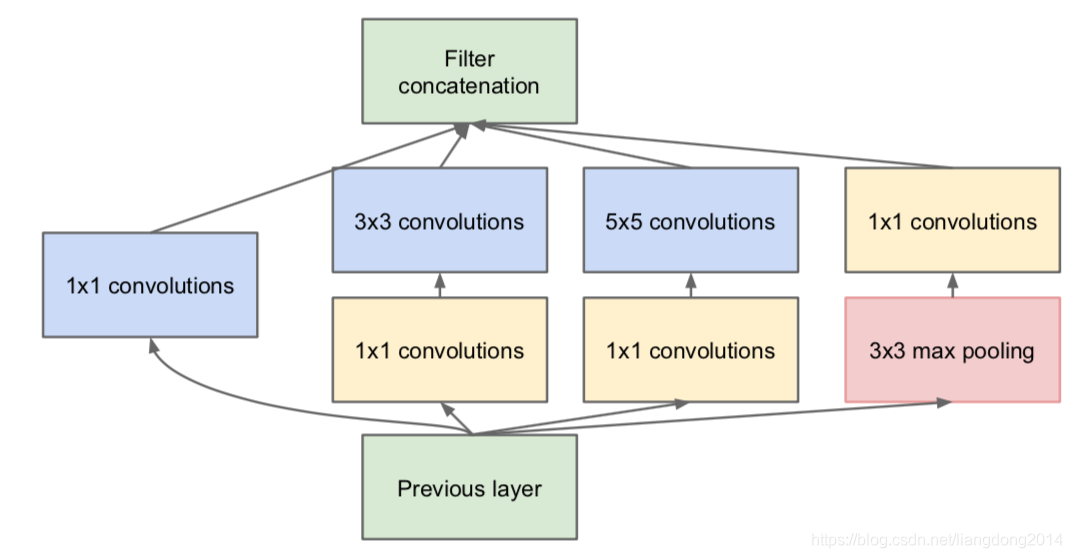
- 这里其实还有一个问题就是为什么不统一在filter concatenation后跟一个1x1的卷积,而是在module内的每个branch跟了一个1x1的卷积,个人感觉是因为这样更适合multi-scale的初衷。通过这样可以使得每个scale可以提取到适合自己的特征。
- 作者还在开始的两个convolutional layer跟了LRN Block(Local Response Normalization)。他是Alex net中使用的归一化方法,定义如下
其中N表示channel的个数,n表示adjacent的个数。x,y表示坐标。总的来说就是对每个位置的特征,计算他在相同位置先后多个特征下的归一化后的值。也是计算的特征之间的归一化。每个位置之间是独立的。 - ensemble,作者使用了multi-crop,multi-modelensemble的方式来进一步改善测试集上的效果
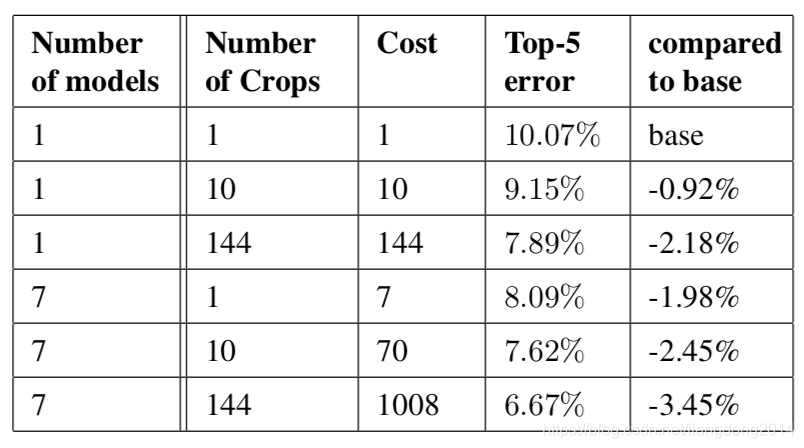
- multi-model, 作者用相同的网络结构,参数初始化方式训练来7个模型,他们之间的不同仅仅在于随机打乱来输入的顺序,以及sampleing的方法不同。
- multi-crop,作者最多crop出来144个图像。首先将最短边放缩到256, 288,320和352。然后再提取square从left,center 或者是right(或者对称的top, center或者是right)。再然后将square的四个角,中间crop出224x224或者是将square resize到224x224。所以每幅图像crop得到图像的个数是436*2=144。
- 最后ensemble的方式也是对得到的softmax probabilities计算平均值。
- 效果如下表所示,我们可以看到通过test阶段的multi-scale,效果还是有显著提升的。