“Two-Stream Convolutional Networks for Action Recognition in Videos”(2014NIPS)
Two Stream方法最初在这篇文章中被提出,基本原理为对视频序列中每两帧计算密集光流,得到密集光流的序列(即temporal信息)。然后对于视频图像(spatial)和密集光流(temporal)分别训练CNN模型,两个分支的网络分别对动作的类别进行判断,最后直接对两个网络的class score进行fusion(包括直接平均和svm两种方法),得到最终的分类结果。两个分支使用了相同的2D CNN网络结构。与3D卷积希望自动提取时空信息不同光,这里直接显示的输入了运动信息,说明3D卷积提取时间信息的能力还比较差。
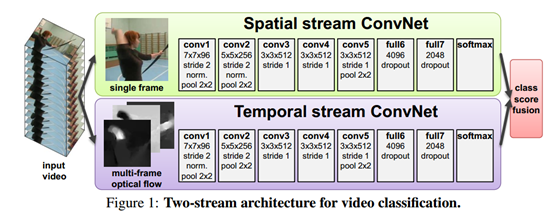
Q1:提取光流只使用的原视频中一小段连续的帧,这样做会不会损失掉关键信息?
Q2:对于两个流的卷积网络都是各自训练,然后直接把得到的结果联合,完全独立地得到时间和空间特征会不会忽略了时空之间的联系?(2016CVPR有一篇论文好像是针对这一点的改进,还没看。”Convolutional Two-Stream Network Fusion for Video Action Recognition“(2016CVPR))
”Temporal Segment Networks: Towards Good Practices for Deep Action Recognition”(2016ECCV)
这篇文章主要是对Two-tream结构的改进,
1、 之前的做法是连续密集采样,这样采集的信息可能冗余,也可能损失有用的信息,也不能得到整个视频完整的时序特征。TSN在时间流采用稀疏采样从而在不增加太多计算量的情况下能够得到一个比较完正的整个视频的时序特征。
具体做法:
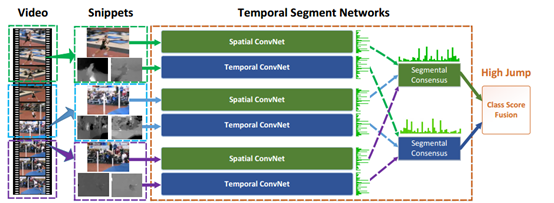
把原视频分成k段,从每段从随机的截取一小段,相当于k个原始two-tream网络,但是这k个网络共享参数,实际上也就是一个网络,然后把得到的k个特征向量取平均值。
Q:虽然因为snippet计算时共享参数,每个小段都会对W的更新贡献梯度,但是只能整个视频都会对分类有影响,但是没有证据能说明这样做能融合得到时序信息,这更像是增加了采样的密度而已。
2、另一个改进就是数据规模过小导致太复杂的深度网络过拟合的问题。
1)cross-modality pre-trainning:把光流矩阵放缩到【0-255】的范围,网络采用imageNet上预训练的参数,把第一个卷积层的3通道的卷积核取平均变成单通道,然后重复k次,k为堆叠的时序信息通道数。
2)正则约束:采用BN层来防止变量偏移,加速收敛。但是因为数据量小,初始阶段可能造成错误的分布函数的估计,所以作者提出冻结除了第一层以外的BN层的平均数和标准差。此外,采用dropout层防止过拟合,空间流0.8,时间流0.7
3)数据增强:原two-tream采用随机裁剪和水平反转。这里直接在4个角落和中心裁剪,防止中心部分在随机裁剪中出现的可能性比较大的问题,原数据大小被放缩成256340.
裁剪的宽高从4个之中随机选取,然后被放缩到224224。
2、 此外,还研究了RGB difference 、optical flow 、warped optical flow哪个能比较好的提取时序信息并被网络学习。 RGB difference能够体现变化显著的区域,warped optical flow能够修正相机移动的影响。
"Learning spatiotemporal features with 3d convolutional networks"
提出了3D卷积的概念

UCF101-85.2% 可以看出其在UCF101上的效果距离two stream方法还有不小差距。我认为这主要是网络结构造成的,C3D中的网络结构为自己设计的简单结构

“A Closer Look at Spatiotemporal Convolutions for Action Recognition“CVPR2018对结构做了改进,还没看。
另外一个很大的原因就是数据集不够大,因为根据后面更大的数据集Kinetic的测试情况来看,在小数据集UCF101上C3D和two-tream的差距比较大,但是在该数据集上,差距在迅速的缩小。

C3D的最大优势在于其速度,但从网络来说,C3D的处理速度与two-tream相差无几,但是two-tream中需要提取光流,这是一个比较耗时的工作。
“Revisiting the Effectiveness of Off-the-shelf Temporal Modeling Approaches for Large-scale Video Classification”
这篇论文的主要思想是用卷积网络提取特征,然后把特征送入设计的分类器中分类,而不是直接进行端到端的训练。文中主要提到了2中分类器:
1、 Multi-Group Shifting Attention Network
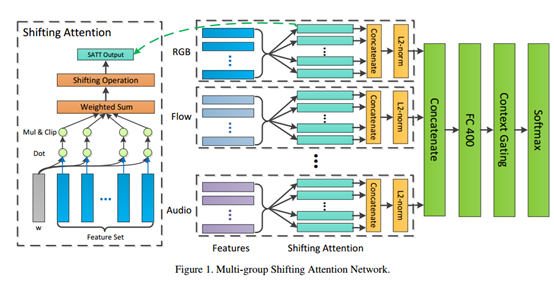
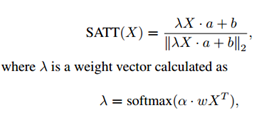
这些操作就是类似提取特征中的关键信息,去除噪声。
2、 Temporal Xception Network
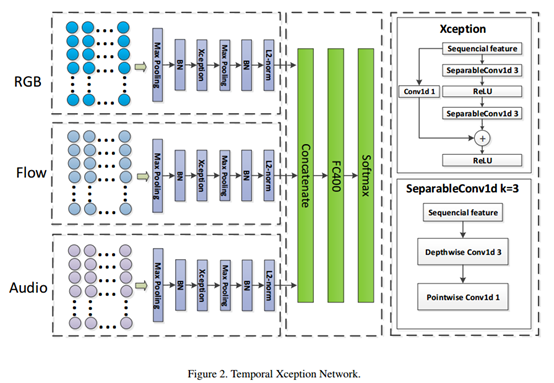
这里的操作我没看太懂,论文没有细节描述。不知道这里的序列化特征是怎么得到的。
这里提出的一个思想就是,空间卷积和时序卷积完全分开。
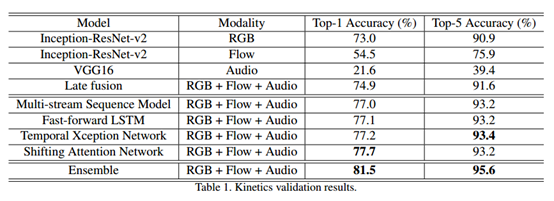
最终论文也没有对比实验,不知道论文中设计的这里分类器对比传统的SVM之类的分类器效果有没有提升,提升了多少。
Non-local Neural Networks
卷积层的堆叠可以增大感受野,但是如果看特定层的卷积核在原图上的感受野,它毕竟是有限的。这是local运算不能避免的。然而有些任务,它们可能需要原图上更多的信息,比如attention。如果在某些层能够引入全局的信息,就能很好地解决local操作无法看清全局的情况,为后面的层带去更丰富的信息。
为了能够当作一个组件接入到以前的神经网络中,作者设计的non-local操作的输出跟原图大小一致,具体来说,是下面这个公式:

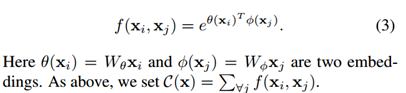
上面的公式中,输入是x,输出是y,i和j分别代表输入的某个空间位置,x_i是一个向量,维数跟x的channel数一样,f是一个计算任意两点相似关系的函数,g是一个映射函数,将一个点映射成一个向量,可以看成是计算一个点的特征。也就是说,为了计算输出层的一个点,需要将输入的每个点都考虑一遍。
一个non-local block的输出如下:
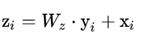
将整个non-local化为矩阵乘法运算+卷积运算

总结:视频分类中很重要的就是利用好时序信息,主流方法主要有2类,一种是显示的提取时序信息(optical flow),另一种是自动学习提取时序信息(3D conv),还有一种用RNN处理时序的,但是这方面的效果不太好,论文也不多。two-tream方面的工作主要还是在想办法解决缺少处理long-term时序信息的问题。3Dconv 主要是精心设计网络结构去解决自动学习捕获时序信息的能力,同时减少网络参数。最近的一些文章在试图在常规的2Dconv网络中增加模块去解决2Dconv不能很好利用时序信息的问题(基本上都是把以前提出的很好的传统方法稍作改造,做成一个模块插入到2Dconv网络中)。