论文 Matching Article Pairs with Graphical Decomposition and Convolutions 详细流程
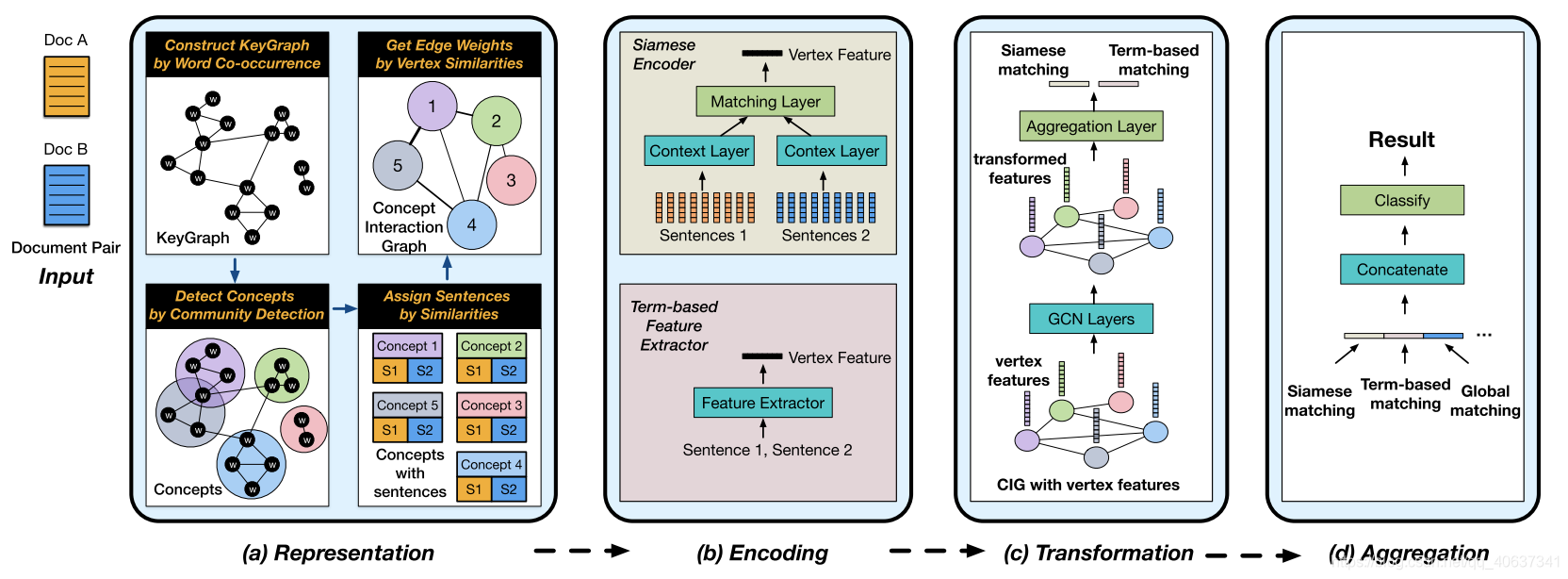
一、CIG
1.KeyGraph construction:(通过TextRank方法)提取出document中的keyword,构建KeyGraph,每个keyword为一个vertex,若两个keyword在同一个sentence中一同出现过,则这两个节点之间有边。
2.concept detection:(可选)用community detection算法将若干个相关性很高的keyword组成一个concept,即community detection可以将keygraph的所有节点split分组成多个communities,一个community中的若干个keyword为一个concept,注意每个keyword可能出现在多个concept中。(若不用步骤2,则每一个keyword为一个concept)
目前为止,得到concepts。
3.sentence attachment:将document中的每个sentence分配到对应的concept中(归类)。计算出每个sentence与每个concept的TF-IDF余弦相似值,找到与每个sentence最相似的concept。
目前为止,每个concept(每个节点)附带有若干个sentence。(对于两个document的公共concept,sentence来自不同的document)
4.构造好每个concept以及concept附带的sentences后,进行每个concept即每个节点它们的边的构建。
edge construction:边构建的标准是每个concept节点附有的sentences之间的TF-IDF文本相似性。
目前为止,CIN已经构建完成,图的每个节点为一个concept,节点之间的边代表concept之间的相似性相关性,每个concept附有sentences。
二、 Encoding Local Matching Vectors(learning multi-viewed matching features for each concept vertex)
每个节点学习一个matching vector用作feature(用来表示该节点附带的来自不同document的两个sentence sets的语义相似性)。
(以下将节点v附带的两个来自不同的document的sentence sets称作SAv和SBv)
有两种方法:
1.siamese Encoder:
输入为两段序列,分别为SAv的word embeddings以及SBv的word embedding。先分别经过一个context layer,得到CAv和CBv,目的是要分别获取SAv和SBv的上下文信息。
再经过一个aggregation layer(matching layer),得到节点的feature的一部分mv。
2.Term-based Similarities:
用五种评分指标计算SAv和SBv的相似性相关性,这五个指标得到的score连接在一起得到节点的feature的另一部分mv’。
每个节点的feature为这两个方法得到的两个matching vector即mv和mv‘它们的concatenation。
注意:步骤二十分关键,将两个document的匹配转变成每个节点附有的两个sentence sets之间的匹配(比较它们是否相似相关)。
目前为止,每个节点都得到了一个matching feature,用作图上节点的特征,这个matching feature表示了SAv和SBv有多匹配有多相关,匹配程度(或者相似性)。
三、structurally transforming local matching features by graph convolutional layers
接着开始transforming,也就是用GCN,GCN的最后一层,得到每个节点新的representation(local matching features)。
GCN的作用:Each GCN layer updates the hidden vector of each vertex by integrating the vectors from its neighboring vertices. Thus, the GCN layers learn to graphically aggregate local matching features into a final result.(要想清楚节点的边的权重是依靠什么来得到的,以及GCN的input的节点的matching feature代表什么)ps:代表节点附带的两个句子集SAv和SBv的匹配程度(或者也可以说是相似性),用一个vector来表示。
四、aggregating local matching features to get the final result
将得到的每个节点的representation(local matching features)合并成一个全局的系统的(图层次的)matching vector,合并的方式是取平均。
目前为止,得到了一个全局的matching feature。
我们还需要增加全局matching feature的信息,将两个document(以document的层次)直接扔进BERT或者直接计算Term-based Similarities再得到另外的global matching feature,将其接入到作者模型得到的matching feature上,最后得到一个新的全局matching feature,最后扔入一个普通分类模型例如MLP,得到分类结果。
conclusion
They already learn to aggregate local comparisons into a global semantic reationship, additionally engineered global features cannot help.
“分而治之”,用图分解、再卷积聚合。
