论文地址:3D human pose estimation in video with temporal convolutions and semi-supervised training
代码地址:VideoPose3D
论文总结
本文方法名为VideoPose3D,使用2D关键点序列( x i , y i x_i, y_i xi,yi)预测某个时间点的3D关键点,大致就是使用一段2D坐标序列(而不是作用在2D heatmap上)动作去拟合某个带深度的点。在训练的时候,本文也提出一种简单但有效的半监督方法去利用没有未标注的视频数据。半监督方法,大致就是先预测未标记的2D视频,再估计3D姿态,通过后映射将3D关键点映射到输入的2D关键点。
如果只进行坐标预测,那么预测的3D坐标将会一直固定在屏幕中心。如果需要任务进行变化,则需要预测另外的根节点轨迹。根节点轨迹回归和3D关节点回顾会互相影响,所以没有共享网络。
论文介绍
概念介绍
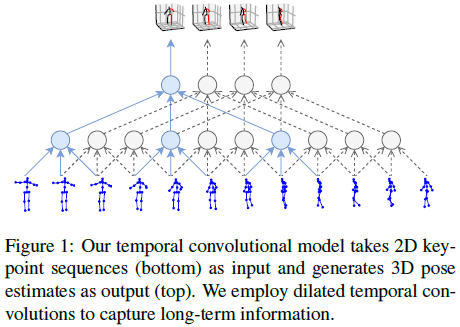
将3D检测变成2D+3D,虽然减少了检测任务的难度,但本质也是模糊的,有歧义的。因为多个3D点在图像中会对应1个2D点。模型结构的粗略图如下图所示,使用空洞时序卷积获得长期信息。最后,采用监督学习的模型和采用半监督学习的模型,都要优于那些使用额外数据的当时最先进的模型。
论文中,提出了一个重要的观点:在two-step的3D检测方法中,难点在于预测精准的2D pose,而从ground-truth中预测3D是相对简单的。所以,作者提出了训练一个cpn-ResNet50来预测2D pose,而不是直接使用ground truth,使得训练和现实中训练的泛化误差大大减少,进而提高了实际的使用能力。
在相关工作里面,另一个观点:2D输入序列和3D输出序列一样长,会让2D有确定性的转换,是更自然的选择。
模型设计
VideoPose3D 的模型结果如下图所示:对于J个关节点的 ( x , y ) (x,y) (x,y)对,应用时域卷积,卷积核大小W,通道C。然后加 B 个 ResNet-Style 的 blocks。每个blocks,先加一个1D conv,kernel_size为 W W W,空洞卷积因子 D = W B D=W^B D=WB,再加一个 1 ∗ 1 1*1 1∗1conv/BN/ReLU/Dropout。最后一个输出层预测所有帧的3D点,以利用过去和未来数据的时域信息。每个block的第一个卷积核大小 W W W和空洞因子 D D D应该设置到能覆盖所有输入帧的感受野大小。

在实时场景中,使用因果卷积,模型结构如下图所示:只使用过去的帧序列,不适用未来帧。

在图像卷积中,一般以zero-padding是的Input和output大小相同。但是有实验显示,使用边界帧填充输入序列,结果会更好。
半监督方法
利用半监督可以提高准确率。作者用encoder,将2D关节点坐标预测到3D,然后再用decoder将3D pose映射回2D坐标,这样就可以使用没有3D坐标标记的数据进行训练,利用2D坐标与decoder映射回来的2D坐标进行惩罚训练。
作者提出监督和半监督一起使用的方法。前半部分是监督学习,后半部分是半监督学习,看3D映射回2D与输入是否一致。训练方法如下图所示。

如果没有全局位置,预测的3D对象将总以固定比例在屏幕中心投影。轨迹回归和3D回归会互相影响,所以没有共享网络。轨迹的损失函数,如下面公式所示: E = 1 y z ∥ f ( x ) − y ∥ E=\frac1{y_z}\|f(x)-y\| E=yz1∥f(x)−y∥表现为加权的MPJPE。
远的目标轨迹的回归,对我们的任务不是特别重要。因为对象远的时候,轨迹相对集中。
半监督学习,为了让网络不仅仅是赋值输入。所以作者添加了软约束,去近似未标记batch目标的骨头长度和已标记batch目标的骨长。这对自监督很重要。所以添加了bone length L2 loss。
网络细节
2D pose
本文采用的2D pose是CPN + Mask RCNN,其中Mask RCNN以ResNet101作为backbone。
Mask RCNN和CPN在COCO数据集上先进行预训练,然后再在Human3.6M的2D映射上进行finetune,以更加适应数据集(也有相对应的消融学习,用COCO学习的CPN直接在Human3.6M数据集上进行3D预测的训练)。
因为human3.6M的2D keypoint和COCO不同,所以在Human3.6M上进行finetune的时候,需要重新初始化最后一层,再加一层deconv回归heatmaps,以学习新的keypoint。
3D pose
一般情况下,是不进行全局轨迹的预测的,除非使用半监督学习。
在初步试验的训练中,作者发现大量预测相邻帧要比不利用时域信息要差(随机样本的batch)。因此,作者选择从不同视频中剪切出响应的片段混合起来训练。
实验细节上,发现可通过stride的conv替代dilation conv,以优化单帧。在推理时,可对整个序列进行处理,并复用其他3D帧的中间状态,从而提高推理速度。在训练时,发现BN参数如果以默认值训练,会导致测试误差波动大( ± 1 \pm1 ±1mm)。所以,设置了BN层的参数衰减策略:刚开始初始化 β = 0.1 \beta=0.1 β=0.1,指数衰减到 β = 0.001 \beta=0.001 β=0.001。最后,在测试时,增加了flip操作。
实验结果
时序dilation conv模型
下表展示了与其他先进模型的对比。本文模型在所有的标准下,都具有当时最低的平均误差,且不依赖于其他数据。需要注意的是,模型清晰地利用了时序信息,所以在MPJPE上比单帧实验要低5mm。但单帧的模型也比其他的要好。还需注意的是,这个表中的模型,是通过finetune后的CPN的2D序列训练得到的,而不是使用ground_truth。

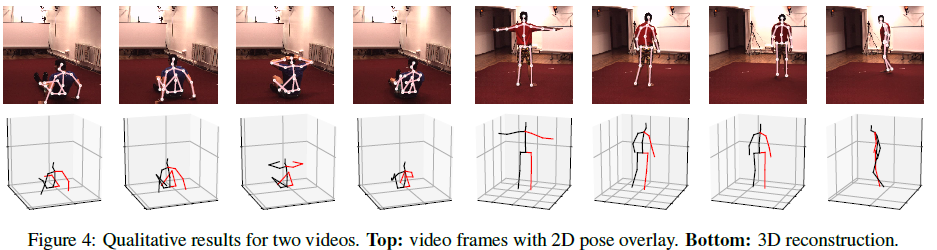
上面的时序dilation conv使用了过去和未来帧的信息,如果需要在实时的场景中进行3D预测,需要使用casual conv,这将预测最后一帧的3D pose。dilation conv时序模型的部分展示结果如下图所示。
有趣的是,使用Mask RCNN和ground-truth bounding box的性能相似,表示着检测结果在这单人场景里面几乎完美。
下表展示了2D点预测出来的序列对3D pose的影响,其中展示各种2D来源的结果。CPN & Mask RCNN展示结果的改进,可能是更高的heatmap 分辨率,更强的特征合并,或更离散的预训练数据集。

绝对位置误差,不能度量预测的平滑性。而平滑性对于视频而言很重要。为了评估这点,使用关节速度误差(MPJVE),其对应MPJPE的3D序列的一阶导数。表二表示,时序模型减少了MPJVE单帧基线平均降低76%,从而大大平滑了3D pose。

下表展示了在HumanEva-I数据集上训练的结果。

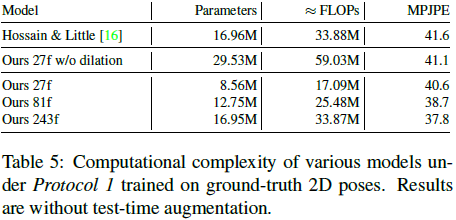
下表比较了CNN和LSTM的复杂性,也比较了使用不同长度的2D序列进行3D pose估计的结果。