A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection
摘要
我们如何学习一个对遮挡和变形不变的物体检测器?我们目前的解决方案是使用数据驱动策略 - 收集具有不同条件下的对象实例的大规模数据集。希望最终的分类器可以使用这些例子来学习不变性。但是真的有可能看到数据集中的所有遮挡?我们认为像类别,遮挡和对象变形也遵循长尾。一些遮挡和变形非常罕见,几乎不会发生。但我们想要学习一个不会出现这种情况的模型。在本文中,我们提出了一种替代解决方案。我们建议学习一个GAN网络,该网络可以生成包含遮挡和变形的示例。对手的目标是生成对象检测器难以分类的示例。在我们的框架中,原始检测器和对手都以共同方式学习。我们的实验结果表明,与Fast-RCNN管道相比,VOC07上的2.3%mAP提升和VOC2012目标检测挑战上的2.6%mAP提升。我们也为本文发布代码1。
1. Introduction
对象检测的目标是学习汽车等概念的视觉模型,并使用此模型将这些概念定位到图像中。 这要求能够对照明,变形,遮挡和其他类内变体进行稳健建模。 处理这些不变性的标准范例是收集具有不同条件下的对象实例的大规模数据集。 例如,COCO数据集[18]在不同的遮挡和变形下有10多万辆汽车示例。 希望这些例子能捕捉视觉概念的所有可能的变化,然后分类器可以有效地为它们建立不变性的模型。 我们相信这是ConvNets在物体检测任务中如此成功的主要原因之一:他们能够使用所有这些数据来学习不变性。
但是,像对象类别一样,我们相信即使是遮挡和变形也会遵循长尾分布。 也就是说,一些遮挡和变形是非常罕见的,以至于它们在大规模数据集中发生的可能性很小。 例如,考虑图1所示的遮挡。我们注意到一些遮挡比其他遮挡更频繁地发生(例如,停车库中其他车辆的遮挡比空调更频繁)。 类似地,动物中的一些变形是常见的(例如坐姿/站立姿势),而其他变形非常罕见。
那么,我们如何学习这种罕见/不常见的遮挡和变形的不变性? 尽管收集更大的数据集是一种可能的解决方案,但由于长尾统计数据而不可能扩展。

图1:我们认为,遮挡和变形都遵循长尾分布。 一些遮挡和变形很少见。 在本文中,我们建议使用GAN网络来生成具有遮挡和变形的例子,这对于物体检测器来说很难分类。 随着对象检测器变得越来越好,我们的对抗网络也会适应。 凭借这种对抗性的学习策略,我们凭借经验显示了检测准确性的提升。
最近,在生成图像(或像素)方面进行了大量工作[4,9,26]。 了解这些罕见事件的一种可能方式是通过从尾部分布中抽样来生成逼真的图像。 然而,这不是一个可行的解决方案,因为图像生成需要训练这些罕见事件的例子。 另一种解决方案是产生所有可能的遮挡和变形,并从它们中训练物体检测器。 但是,由于变形和遮挡的空间很大,这不是一个可扩展的解决方案。 已经表明,使用所有的例子往往不是最优的解决方案[33,39],而选择较难的例子则更好。 是否有一种方法可以生成具有不同遮挡和变形的“硬”正面示例,并且不会自行生成像素?
如何训练另一个网络:一个通过在空间上阻塞某些特征映射创建硬性示例的对手,或者通过操纵特征响应来创建空间变形。 这个对手会预测像Fast-RCNN这样的检测器会很难,然后Fast-RCNN会自行调整以学习分类这些GAN的例子。 这里的关键思想是在卷积特征空间中创建GAN的例子,而不是直接生成像素,因为后者是一个更难的问题。 在我们的实验中,与标准的Fast-RCNN流水线相比,我们展示了对抗Fast-RCNN(A-Fast-RCNN)性能的实质性改进。
2. Related Work
近年来,在物体检测领域取得了重大进展。 这些最近的成功基于从ImageNet分类[3]的任务中学到的强大的深层特征[16]。 R-CNN [8]和OverFeat [30]物体检测系统在PASCAL VOC领域取得了令人印象深刻的成果[5]; 并且近年来出现了更多计算效率更高的版本,可以在COCO [18]等更大的数据集上进行有效训练。 例如,Fast-RCNN [7]共享不同区域提案中的卷积以提供加速,Faster-RCNN [28]和R-FCN [2]在框架中合并区域提案生成, 最终版本。 在Overfeat检测器的滑动窗口范例的基础上,出现了其他计算效率高的方法,如YOLO [27],SSD [19]和DenseBox [13]。 在[12]中讨论了这些方法之间的彻底比较。
最近的研究集中在开发更好的物体检测系统的三个主要方向。
第一个方向依赖于改变这些网络的基础架构。中心思想是,使用更深的网络不仅会提升分类效果,而且提升检测效果。最近在这方面的工作包括ResNet [10],Inception-ResNet [38]和ResNetXt [43]用于物体检测。
第二个研究领域一直是使用上下文推理,推理的代理任务和其他自上而下的机制来改善对象检测的表示[1,6,17,24,32,34,45]。例如,[32]使用分割作为一种方式来上下文地提取对象检测器并向初始层提供反馈。 [1]使用skipnetwork架构,并使用来自多个表示层的特征以及上下文推理。其他方法包括使用自顶向下的特征来结合上下文和更精细的细节[17,24,34],这导致改进的检测。
改进检测系统的第三个方向是更好地利用数据本身。 人们经常认为,物体检测最近的成功是更好的视觉表现和大规模学习数据的可用性的产物。 因此,第三类方法试图探索如何更好地利用数据来提高性能。 一个例子是将硬实例挖掘整合到一个有效和高效的基于区域的ConvNet [33]训练中。 findind硬件训练示例的其他例子包括[20,35,41]。
我们的工作遵循第三个研究方向,重点在于更好地利用数据。然而,我们并不试图通过筛选数据来找到难以理解的例子,而是尝试生成难以用于Fast-RCNN检测/分类的例子。我们限制新一代正面代的空间,以便从数据集中为当前现有示例添加遮挡和变形。具体而言,我们学习对抗性网络,试图预测会导致Fast-RCNN误分类的遮挡和变形。因此,我们的工作与最近在对抗学习方面的大量工作有关[4,9,14,21,22,23,26,29,37]。例如,已经提出了技术来改善图像生成的对抗性学习[26]以及训练更好的图像生成模型[29]。 [29]还强调,生成对抗学习可以改善半监督环境下的图像分类。然而,这些作品中的实验是针对复杂程度低于对象检测数据集的数据进行的,其中图像生成结果明显较差。我们的工作也与最近关于机器人对抗训练的研究有关[25]。然而,我们并没有使用生成对抗来获得更好的监督,而是使用生成对抗来生成这些实例。
3. Adversarial Learning for Object Detection
我们的目标是学习一个对不同条件(如遮挡,变形和照明)具有鲁棒性的物体检测器。 我们假设,即使在大规模数据集中,也不可能涵盖所有潜在的遮挡和变形。 我们采取另一种方法,而不是严重依赖数据集或筛选数据来查找难题。 我们主动生成对于物体检测器难以识别的示例。 但是,我们不是在像素空间中生成数据,而是专注于生成的受限空间:遮挡和变形。
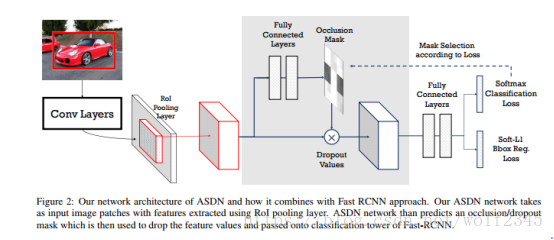
图2:我们的ASDN网络体系结构以及它如何与fast RCNN方法相结合。 我们的ASDN网络将带有使用RoIpooling层提取的特征的图像补丁作为输入。 ASDN网络比预测一个遮挡/丢弃遮罩,然后用它来丢弃特征值并传递到Fast-RCNN的分类塔。
在数学上,让我们假设原始物体检测器网络表示为F(X),其中X是目标提议之一。 检测器给出表示类输出的两个输出Fc,并且F1表示预测的边界框位置。 让我们假设X的groundtruth真值类别是C,空间位置是L.我们原来的检测器损失可以写成:
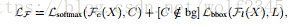
第一项是SoftMax损失,第二项是基于预测边界框位置和groundtruth框位置(仅前景类)的损失。
假设对抗网络表示为A(X),它给出了一个在图像I上计算出的特征X,从而产生一个新的对抗性例子。 检测器的损失函数保持不变,因为小批量现在包含较少的原始和一些生成对抗的例子。
然而,生成对抗网络必须学会预测检测器失效的特征。 我们通过以下损失函数训练这个生成对抗网络,

因此,如果由对抗网络产生的特征容易对检测器进行分类,则对于对抗网络来说,我们将获得高损失。 另一方面,如果在对抗性特征生成之后对于检测器来说很困难,那么对于检测器而言,我们将获得高损失,并且对于对抗网络而言损失低。
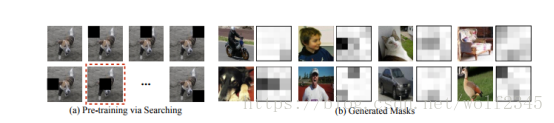
图3:(a)模型预训练:选择硬遮挡并用作地面实况训练ASDN网络的遮挡示例(b)示例
4. A-Fast-RCNN: Approach Details
我们现在描述我们框架的细节。 我们首先简要介绍我们的基本检测网络Fast-RCNN。 接下来描述生成对抗生成的空间。 特别是,我们专注于在本文中产生不同类型的遮挡和变形。 最后,在第5节中,我们描述了我们的实验设置并显示示比基线显着改进的结果。
4.1. Overview of Fast-RCNN
我们建立在Fast-RCNN对象检测框架[7]上。 Fast-RCNN由两部分组成:(i)用于特征提取的卷积网络; (ii)一个RoI网络,带有一个RoIpooling层和几个全连接层,可以输出对象类和边界框。
给定输入图像后,Fast-RCNN的卷积网络将整个图像作为输入,并生成卷积特征映射作为输出。 由于操作主要是卷积和最大池化,输出特征映射的空间维度将根据输入图像大小而变化。 给定特征映射,RoIpooling层用于将对象提议[40]投影到特征空间上。 ROI-pooling裁剪和调整大小以为每个对象提议生成固定大小的特征向量。 这些特征向量然后通过全连接层。 全连接层的输出是:(i)包括背景类的每个对象类的概率; 和(ii)边界框坐标。
对于训练,SoftMax损失和回归损失分别应用于这两个输出,并且梯度通过所有层反向传播以执行端到端学习。
4.2. Adversarial Networks Design
我们考虑生成对抗网络的两种类型的特征生成与Fast-RCNN(FRCN)检测器竞争。 第一种类型是遮挡。 在这里,我们提出了对抗空间丢失网络(ASDN),该网络学习如何封闭给定的对象,使得FRCN很难分类。 我们在本文中考虑的第二种类型是变形。 在这种情况下,我们提出了生成对抗空间变换网络(ASTN),该网络学习如何旋转对象的“部分”并使其难以被检测器识别。 通过与这些网络竞争并克服障碍,FRCN学会以一种强有力的方式处理物体遮挡和变形。 请注意,建议的网络ASDN和ASTN在训练期间与FRCN一起同时学习。 联合训练可以防止过拟合。
我们没有在输入图像上创建遮挡和变形,而是发现在特征空间上操作更加高效和有效。 因此,我们设计我们的对抗网络来修改功能,以使对象更难识别。 请注意,这两个网络仅在训练期间应用以改进检测器。 我们将首先单独介绍ASDN和ASTN,然后将它们组合在一个统一的框架中。
4.2.1 Adversarial Spatial Dropout for Occlusion
我们提出了一个对抗空间丢失网络(ASDN)来为前景对象的深层特征创建遮挡。 回想一下,在标准的Fast-RCNN流水线中,我们可以在RoIpooling层之后为每个前景对象提议获取卷积特征。 我们使用这些基于地区的功能作为我们的Gan网络的输入。 鉴于某个对象的特征,ASDN将尝试生成一个掩码,指示要丢弃的特征的哪些部分(分配零),以便检测器无法识别该对象。
更具体地说,给定一个对象,我们提取大小为d×d×c的特征X,其中d是空间维度,c表示通道数目(例如,c = 256,在AlexNet中d = 6)。 鉴于此特性,我们的ASDN将预先设置一个掩模M,其中d×d值在阈值之后为0或1。 我们在图3(b)的阈值之前显示一些掩模。 我们将Mij表示为面具第i行和第j列的值。 类似地,Xijk表示特征的位置i,j处的通道k中的值。 如果Mij = 1,我们丢弃feature map X的相应空间位置中的所有信道的值,即Xijk = 0,∀k。
Network Architecture.
我们使用标准FastRCNN(FRCN)架构。 我们使用来自ImageNet的预训练初始化网络[3]。 Gan网络使用FRCN共享卷积层和RoIpooling,然后使用自己独立的完全连接的层。 请注意,由于我们正在优化两个网络以完成完全相反的任务,因此我们不使用Fast-RCNN共享ASDN中的参数。
Model Pre-training.
在我们的实验中,我们发现在使用它来改进Fast-RCNN之前,预先训练ASDN创建遮挡是很重要的。 受fast RCNN检测器[28]的驱动,我们在这里应用阶段式训练。 我们首先训练我们的fastRCNN探测器,无需ASDN进行10K迭代。 由于探测器现在对数据集中的对象有一定的了解,我们通过修复探测器中的所有层来训练ASDN模型以创建遮挡。
Initializing ASDN Network.
为了初始化ASDN网络,给定具有空间布局d×d的feature map X,我们在其上应用尺寸为d/3×d/3的滑动窗口。我们通过将窗口投影回图像来表示滑动窗口过程,如图3(a)所示。对于每个滑动窗口,我们删除空间位置被窗口覆盖的所有通道中的值,并为区域提议生成新的特征向量。这个特征向量然后通过分类层来计算损失。基于所有d/3×d/3窗口的损失,我们选择损失最高的窗口。此窗口然后用于创建一个d×d掩码(窗口位置为1,其他像素为0)。我们为n个正区域提议生成这些空间模板,并为我们的Gan辍学网络获得n对训练实例{(X1,M〜1),...,(Xn,M〜n)}。这个想法是,ASDN应该学会生成可以给检测器网络带来高损失的掩模。我们将二叉交叉熵损失应用于训练ASDN,它可以表示为,

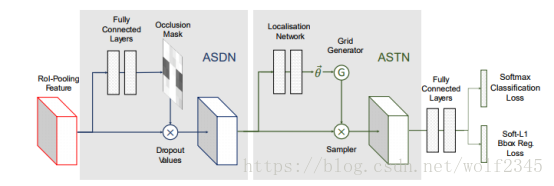
Figure 4: Network architecture for combining ASDN and ASTN network. First occlusion masks are created and then the channels are rotated to generate hard examples for training.
其中Aij(Xp)表示在给定输入特征映射Xp的位置(i,j)中的ASDN的输出。 我们用10K迭代的这个损失来训练ASDN。 我们表明,网络开始识别哪些部分的对象对于分类有重要意义,如图3(b)所示。 还要注意,我们的输出掩码与[31]中提出的注意掩码不同,他们使用注意机制来促进分类。 在我们的例子中,我们使用mask来遮挡部分以使分类更难。
采样阈值
ASDN网络生成的输出不是二进制掩码,而是连续的热图。 我们不使用直接阈值处理,而是使用重要性采样来选择顶部1/3个像素进行掩盖。 请注意,抽样过程包含训练期间样本中的随机性和多样性。 更具体地说,给定一个热图,我们首先选择具有最高概率的顶部1/2个像素,并从其中随机选择1/3个像素来分配值1,剩下的2/3个像素设置为0。
联合训练
鉴于预训练的ASDN和FastRCNN模型,我们在每次训练迭代中联合优化这两个网络。 为了训练Fast-RCNN检测器,我们首先使用ASDN在正向传播期间在RoIpooling之后的特征上生成掩模。 我们执行采样以生成二进制掩码,并使用它们删除RoIpooling图层之后的要素值。 然后,我们转发修改过的功能来计算损耗并对检测器进行端到端训练。 请注意,虽然我们的功能已修改,但标签保持不变。 通过这种方式,我们创建了“更难”和更多样化的培训探测器的例子。
为了训练ASDN,由于我们应用采样策略将热图转换为不可区分的二元掩模,因此我们不能直接回避分类损失中的梯度。 或者,我们从REINFORCE [42]方法中获得灵感。 我们计算哪些二进制掩码会导致Fast-RCNN分类分数的显着下降。 我们只使用那些硬实例掩码作为基础来直接训练Gan网络,使用方程式1中所述的相同损失。
4.2.2 用于型变的对抗网络
我们现在介绍对抗空间变换网络(ASTN)。 关键的想法是在对象特征上产生变形,并且难以使探测器识别对象。 我们的网络建立在[15]中提出的空间变换网络(STN)上。 在他们的工作中,STN被提议使特征变形以使分类更容易。 另一方面,我们的网络正在完成相反的任务。 通过与我们的ASTN,我们可以训练一个更好的探测器,它对变形很有效。
STN概述
STN网络有三个组成部分,分别是:定位网络(localisation network)、网格生成器(grid generator)和采样器(sampler)。定位网络将估计形变参数(如旋转度、平移距离和缩放因子),网格生成器和采样器将会用到这些参数来产生新的形变后的特征图。这个空间变换神经网络仍然是复杂的概念,我自己概括就是:相当于在传统的卷积层中间,装了一个“插件”,可以使得传统的卷积带有了裁剪、平移、缩放、旋转等特性。
STN对抗网络
空间变换有好几种形式(裁剪、平移、缩放、旋转等),针对本文中的形变要求,作者仅关注旋转特征,意味着ASTN只需要学习出让检测器难以判别的旋转特征就可以了。如图4所示,对抗网络长得和前面的ASDN相似,其中定位网络由3个全连接层构成,前两层是由fc6和fc7初始化来的。ASTN和Fast R-CNN还是要联合训练,如果ASTN的变换让检测器将前景误判为背景,那么这种空间变换就是最优的。作者也提到,可直接使用Fast R-CNN的softmax loss进行反向传播,因为空间变换是可微的。
实施细节
作者在试验中发现,限制旋转角度很重要,不加限制容易将物体上下颠倒,这样最难识别,也没啥意义。作者把旋转角度限制在了正负10度,而且按照特征图的维度分成4块,分别加以不同的旋转角度,这样可以增加任务复杂性,防止网络预测琐碎的变形