一、R-FCN
1、概述
本文作者Jifeng Dai,Yi Li,Kaiming He,Jian Sun。本文主要是在特征的通道维度上分块后,每一块取空间上某一部分组合成新的feature map来解决分类需空间不变性和检测任务需空间敏感性的矛盾。
R-FCN是在faster RCNN基础上来改进的,主要是针对了fast/faster rcnn的在rpn中提取出的候选区都需要进行subnetwork【即会对每一个选出来的候选区都放到头部(faster rcnn中的fast rcnn网络部分)跑一遍】,这样会导致检测速度慢,速度慢就是因为ROI层后面的结构对不同的proposal是不共享的。本文就提出方法来想办法将ROI后面的结构往前挪。提出了position-sensitive score maps来处理图像分类时的translation-invariance和目标识别时的translation-variance。
2、网络结构
- 原本对于faster-rcnn-Resnet-101,Resnet-101有5个阶段,将第四阶段conv4_x的输出feature map作为RPN阶段的输入,用来提取出proposal regions,且使用第五阶段conv5_x网络部分作为分类和回归的子网络。
- 对于R-FCN来说,是不将conv5_x作为子网络,因此,在conv4_x的feature map直接经过conv5_x。具体子网络结构如下图所示。
- 在conv5_x之后,输出的feature map维度为2048【即w*k*2048】。R-FCN使用1*1卷积将其变为w*h*1024。
- 对于rfcn_cls和rfcn_bbox:使用1*1卷积输出k*k*(class_num+background_1)维的score map【即w*h*(k*k*(c+1))】。最后经过positionsensitive ROI pooling(psroipooling)输出。如图中例:有20类别,加上背景为21,期待roi输出规格为k=7,那么rfcn_cls输出维度为7*7*(c+1)=1029。rfcn_bbox=7*7*8【此处的8有解释:here】
- psroipoolinged_cls_rois:这是R-FCN的一个主要创新实现,从w*h*(k*k*(c+1))的score map中提取出k*k*(c+1)的output。细节就是:对于结果中的维度c+1(包含back ground),每一个维度代表一个类别map,那么在这c+1中每一个k*k*1都是从上一层k*k*(c+1)中取得。比如,如figure1,如果k=3(paper中是k=7),对于第i(
)类的3*3*1求解,对每个类别的w*h*(k^2)的score map的对应区域做变换。如图中色彩绘制。最后经过一个ave pooling来做一个平均化处理。
- psroipooled_loc_rois:对于loc来说,是一样的方法,使用position sensitive策略,只是维度为k*k*8【即w*h*(k*k*8),8在上面有解释】。
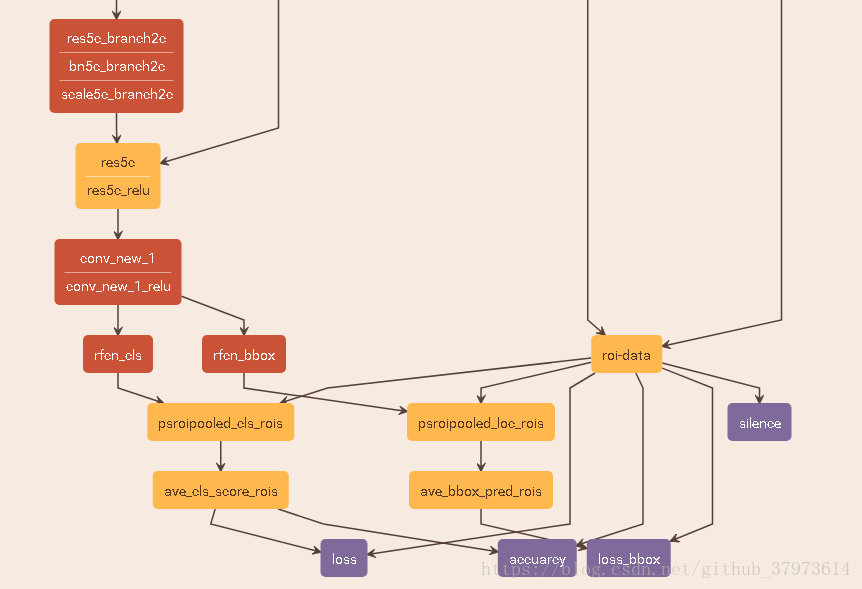
以下是R-FCN的整体网络结构图

三种网络的对比图。

下面这幅图中的计算就表达了整个position-sensitive方法的过程:

3、结果

作者展示了一些结果,但是无论是效果上还是速度上都没有很大的提升【our method achieves accuracy competitive wth the Faster RCNN counterpart, but is much faster during both training and inference】。借鉴于此的想法,旷世科技借鉴了这个想法(light head rcnn)
二、light head RCNN(In Defense of Two-Stage Object Detector)【参考:here】
1、这篇论文是旷视科技和清华大学的联合作品。论文针对two-stage的目标检测框架中,回归坐标和分类的子网络进行优化,主要结合Faster RCNN和RFCN两个网络的优点,同时提出自己的改进,最终在Accuracy和Speed上都取得了state-of-the-art的表现。
一般来说Two-stage的检测框架,第一步是产生足够多的候选框,作者称之为Body,第二步是针对候选框进行识别,作者称之为head,iu想大脑做出判断。一般head的参数都比较多,如faster RCNN,有两个全连接层接在Resnet的conv5_x后面, 并且,ROIPooling后的特征非常大,所以第一个全连接层非常耗内存,且影响速度。并且,Region Proposal都要经过两个全连接层,计算量非常大。而在RFCN中,虽然少了两个全连接层,但是需要构建一个Classesxpxp大小的Score Map,仍然需要很大的内存和计算量。故本文提出来:
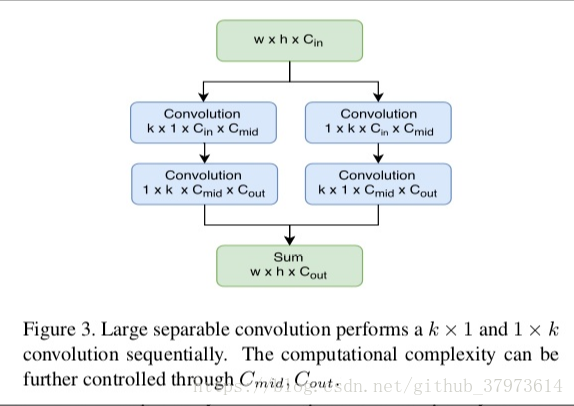
- 使用Large-Kernel Separable Convolution来产生一个“Thin”的Score Map,Score Map只有axpxp通道。【论文中使用的是a=10】
- 在ROI Pooling/PSROIpool后接上全连接层【因为原来的R-FCN的Score Map是classesxpxp通道,正好对应了Classes的预测,现在没有这么多通道了,没办法使用原来的方法了,所以接上一个全连接层也是为了后面可以接上Faster RCNN的回归和分类】
2、Approach
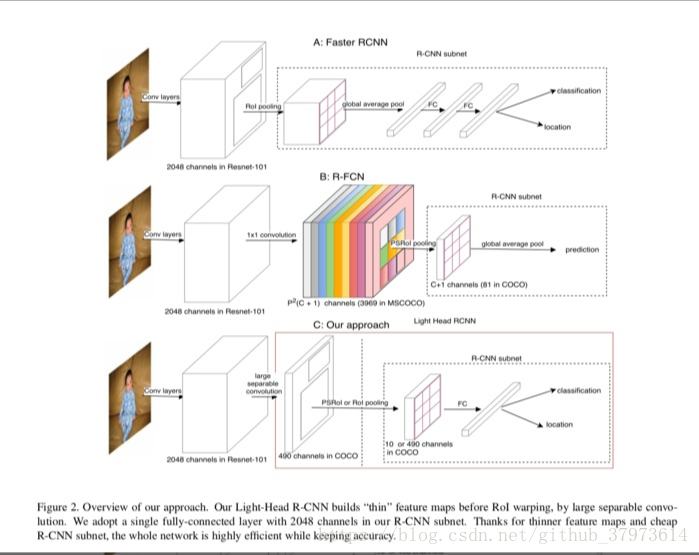
从Accuracy的角度来看,Faster RCNN为了减少第一层全连接的计算量,引入了Global average pooling,虽然对于ROI的分类有好处,但是损失了空间信息,对目标回归不好。而R-FCN直接对position-sensitive pooling后的结果进行pooling,没有ROI-wise层,所以效果没有faster RCNN好。
从速度来看,Faster RCNN的每个roi都需要经过R-CNN子网络(R-CNN subnet),所以计算量是非常大的。R-FCN虽然R-CNN subnet很小,但是它需要生成一个非常大的Score Map,整个网络依然很消耗时间和内存。
- 文章使用了“L”来表示一个大的主体网络,用“S”来表示一个小的主体网络。对于“L"网络,文章使用ResNet101作为基础的特征提取网络,使用Xception作为“S”。
- 作者使用了large separable convolution,接在基础的C5上。如下所示,k=15,对于S网络,Cmid=64,对于L网络,Cmid=256,Cout=10xpxp。
- 在R-CNN subnet部分,作者使用了一个2048通道的全连接层,没有使用dropout。
- RPN使用C4层【conv4_x】的特征。ratio取{1:2, 1:1,2:1},并且有5个scales{32, 64, 128, 256, 512}。NMS的阈值为0.7
4、experiment
- 作者在COCO数据集上做实验,训练集115k,测试集5k。
- Baselines:
- 图片resize成最短边800,最长边1200,5个anchor size。
- 对位置回归的loss比分类的小,所以训练时,对回归的loss进行double
- 训练时,将box的loss排序,将loss表较大的前256个作为反向传播的loss。并且训练时每张图像用了2000个ROIs,测试时用1000个Rois。这样mmAP【we use mmAP to indicate results of mAP@[0.5:0.95]】提高三个点。
- 接下来就是一些对比实验,可以参看论文。
5、一些细节:
OHEM[online hard example mining]:这个有在实验中可选择的用到。
