一 摘要
这些近年来的建立在从ImageNet分类的任务中成功学到的强大的深层特征,因此,物体检测领域取得了显著地进步。最近的研究集中在物体检测系统主要有三个方向。
- 第一个方向依赖于改变这些网络的基础架构。中心思想是使用更深层次的网络不仅可以导致分类改进,而且可以导致目标检测性能提高。最近在这方面的一些工作包括ResNet,Inception-ResNet和ResNetXt 。
- 第二个研究领域是使用上下文推理(充分利用各个卷积层的特征),推理代理任务和其他自顶向下机制来改善目标检测的表示。例如,使用分割作为上下文目标检测器的一种方法,并向初始层提供反馈。使用跳过网络架构,并结合上下文推理使用来自多层表示的特征。其他方法包括使用自上而下的功能来整合上下文和更细的细节,这导致改进的检测。
- 改进检测系统的第三个方向是更好地利用数据本身。经常认为,进来成功的目标检测器是更好的视觉表示和大规模数据用于学习的可用性的产物。因此,第三类方法尝试探索如何更好地利用数据来提高性能。一个例子是将硬实例挖掘纳入到基于训练区域的ConvNets的有效和高效的设置中。发现训练难点的其他例子包括。

一般情况下,像分类一样,遮挡和目标变形也遵循长尾理论。一些遮挡和变形非常罕见,几乎不发生;但是我们想要学习对一个这样的变形具有不变性的模型。在本文中,我们提出了一个替代解决方案。我们建议学习一个对抗网络,生成具有遮挡和变形的样本。对抗器的目标是生成让目标检测器难以进行分类的样本。在我们的框架中,原始检测器和对抗器都是以联合的方式学习的。我们的实验结果表明,与Fast-RCNN网络相比,VOC07上的mAP升幅为2.3%,VOC2012数据集有2.6%mAP提升
二 目标检测的对抗学习
我们的目标是学习对不同条件(如遮挡,变形和照明)都具有鲁棒性的目标检测器。因为,即使在大规模数据集中,也不可能覆盖所有潜在的遮挡和变形。我们采取替代方法,通过遮挡和变形的空间来让对抗网络生成让目标象检测器难以识别的样本。
在数学上,让我们假设原始目标检测器网络被表示为F(X),其中X是一个候选区域。检测器给出两个输出,Fc其表示类别概率输出,F l表示预测的边界框位置。让我们假设X的真值类是C,空间位置是L.我们的原始检测器损失函数可以写成,
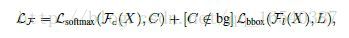
其中第一项是SoftMax损失,第二项是基于预测的边界框位置和真值框位置(仅前景类)的损失。
让我们假设对抗网络被表示为A(X),考虑到在图像I上计算的特征X,生成新的对抗样本。检测器的损失函数保持不变,因为小批次现在包括较少的原始和一些对抗性样本。
然而,对抗网络必须学习预测会让检测器误测的特征。我们通过以下损失函数训练这个对抗网络,

因此,如果对抗网络生成的特征对于检测器来说很容易进行分类,则对于对抗网络而言,它们将获得高损失。另一方面,如果在对抗特征生成之后,对于检测器是难以分类的,则对于检测器而言,我们获得高损失,并且对于对抗网络的损失较低。
三 算法细节
我们首先简要介绍基本检测器Fast-RCNN。其次是描述对抗生成网络的空间。在本文中,我们重点介绍生成不同类型的遮挡和变形。
1.Fast R-CNN
我们基于Fast-RCNN框架进行目标检测。Fast RCNN由两部分组成:
用于特征提取的卷积网络;
具有RoI池化层和几个完全连接的层的RoI网络,其输出目标类别概率和边界框。
2.对抗网络设计
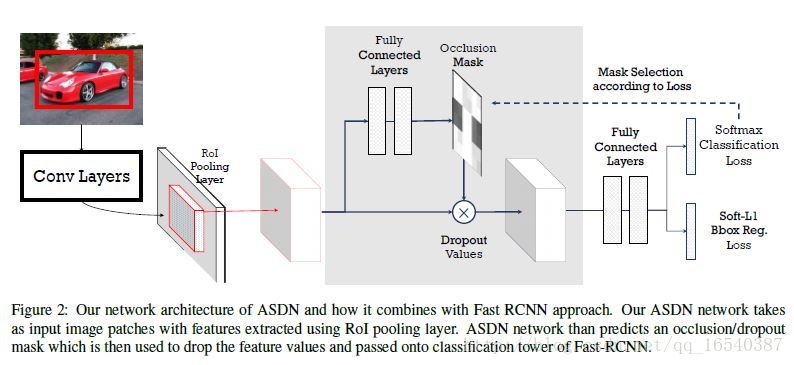
我们通过对抗网络生成遮挡和形变两种特征来提高Fast-RCNN检测器检测不变性的能力。我们提出对抗空间丢弃网络(ASDN)来生成遮挡特征,它学习如何封闭给定的目标,使得FRCN难以对其进行分类。并且,我们提出了对抗空间变换网络(ASTN)来生成形变特征,它学习如何旋转物体的“部件”,使其难以被检测器识别。网络ASDN和ASTN在训练期间与FRCN一起同时学习。联合训练能防止检测器对固定生成的特征产生过拟合。
2.1 产生遮挡的对抗空间丢弃网络(ASDN)
我们利用对抗空间丢弃网络(ASDN)来生成基于前景目标深层特征上的遮挡。在标准的Fast-RCNN中,我们利用在RoI-pooling层之后获得每个前景目标候选区域的卷积特征。我们使用这些基于区域的特征作为对抗网络的输入。对于一个目标的特征,ASDN将尝试生成一个掩码,指示要丢弃的特征的哪些部分(分配零),以便检测器无法识别目标。
- 网络架构。我们使用标准的Fast-RCNN(FRCN)架构,对抗网络与FRCN共享卷积层和RoI池化层,然后使用其自己独立的完全连接的层。
- 模型预训练。我们首先训练我们的Fast-RCNN检测器,不用ASDN进行10K次迭代。由于检测器现在已经具有对数据集中目标的感知,我们在固定检测器所有层的前提下训练ASDN模型来生成遮挡。
初始化ASDN网络。
1.对于给定大小的特征图X,应用d/3xd/3的滑动窗口。
2.对于每个滑动窗口,将该位置被覆盖的所有通道的值丢弃掉,并为候选区域生成一个新的特征向量。然后将该特征向量传递到分类层以计算损失。
4.基于所有d/3×d/3滑动窗口的损失值,我们选择损失最大的那个滑动窗口,该窗口然后被用来生成单个d×d掩码(窗口位置为1,其他像素为0)。
5.我们为n个正的候选区域生成这些空间掩码,并为我们的对抗丢弃网络获得n对训练样本{(X1,M1),…,(Xn,Mn})。
6.ASDN应该学会生成可以使检测器网络具有高损失的掩码,在训练ASDN时应用二进制交叉熵损失,
其中Aij(Xp)表示对于输入特征图Xp的(i,j)位置中ASDN网络的输出。我们训练ASDN使用这个损失函数进行10K次迭代。我们得到网络开始认识到哪一部分目标对于分类是重要的。在我们的实验中,我们使用掩码遮挡部分特征,使分类变得更加困难。
阈值采样。ASDN网络生成的输出不是二进制掩码,而是连续的热图。相对于使用直接阈值,我们使用重要性抽样来选择顶部1/3像素进行掩码生成。更具体地说,给定一个热图,我们首先选择具有最高概率的顶部1/2像素,并随机选择其中的1/3像素来分配值1,其余的2/3像素被设置为0。
- 联合训练对于预训练后的ASDN和Fast-RCNN模型,我们将共同优化这两个网络。
1.对于训练Fast-RCNN检测器,在正向传播期间,我们首先在RoI池化层之后的特征上使用ASDN生成掩码。
2.我们通过采样来生成二进制掩码,并使用它们来删除在RoI-pooling层之后的特征中的值。
3.然后,我们将修改后的特征进行前向训练并计算损失,并对检测器进行端到端的训练。
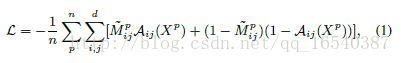

通过这种方法,我们就为训练检测器生成了“更难”和更多样化的样本。
2.2 对抗空间变换网络(ASTN)
对抗空间变换网络是在目标特征上创建变形,并使检测器的目标识别变得困难。通过与我们的ASTN网络竞争,我们可以训练一个更好的对变形具有鲁棒性的检测器。
- STN概述。空间变换网络有三个部分:定位网络,网格生成器和采样器。对于输入的特征图,定位网络将估计要变形的量(例如,旋转度,平移距离和缩放因子)。这些变量将被用作在特征图上的网格生成器和采样器的输入。输出是变形的特征图。
- 对抗STN。在对抗空间变换网络中,我们将在RoI-pooling层后给出了一个特征图作为输入,我们的ASTN将学习旋转特征图,使其更难识别。
- 实现细节。在我们的实验中,我们将旋转度限制在顺时针和逆时针10度以内。否则,旋转度太大很容易将目标上下颠倒,这在大多数情况下是最难识别的。
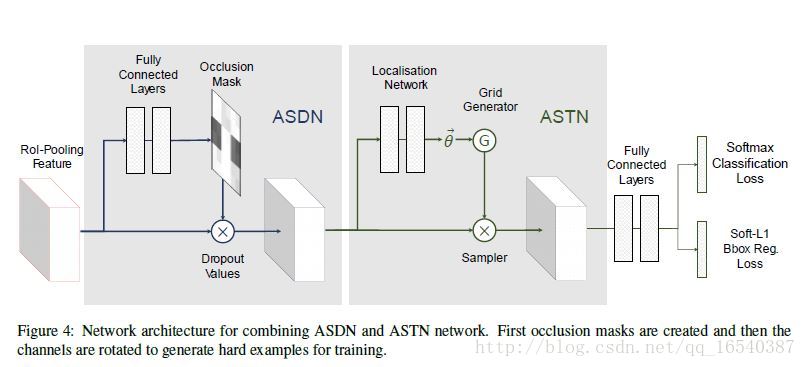
2.3 对抗融合
我们将这两个网络以顺序的方式组合到Fast-RCNN框架中。 在RoI-pooling之后提取的特征映射首先进入到我们的ASDN,ASDN会删除一些激活值。修改后的特征由ASTN进一步变形。通过同时竞争这两个网络,我们的检测器变得更加健壮。
四 实验
PASCAL VOC 2007结果
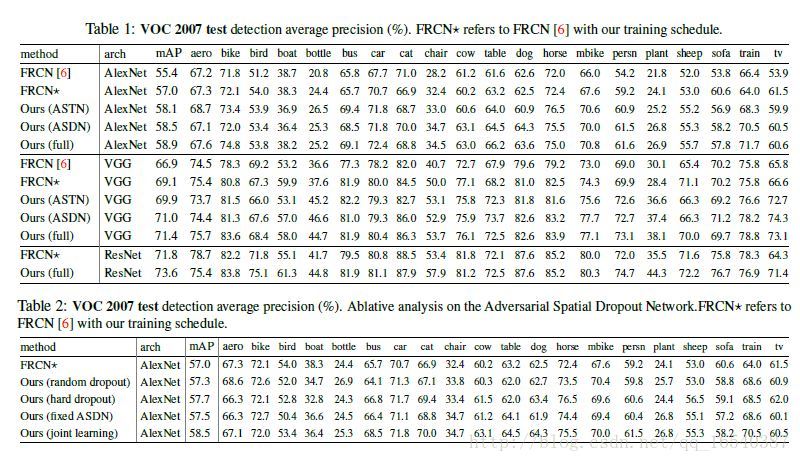
我们报告了在训练Fast-RCNN期间使用ASTN和ASDN的结果,参照表1。对于AlexNet架构[16],我们实施的基线达到57.0%的mAP。基于此设置,我们与ASTN模型的联合学习达到58.1%,与ASDN模型联合学习提高到了58.5%的表现。由于这两种方法相互补充,将ASDN和ASTN结合到我们的完整模型中,另外提高到了58.9%的mAP。
对于VGG16架构[36],我们进行了同样的实验。首先,我们的基线模型达到了69.1%的mAP,远高于[6]中报告的66.9%。基于此实施,我们的ASTN模型联合学习得到了69.9%的mAP,ASDN模型达到了71.0%的mAP。我们的ASTN和ASDN的完整模型将性能提高到71.4%。我们的最终结果在基础模型上提高了2.3%。
为了表明我们的方法也适用于非常深的CNN,我们将ResNet-101 [9]架构应用于训练Fast-RCNN。如表1最后两行所示,Fast-RCNN与ResNet-101的性能为71.8%mAP。通过对抗性训练,结果是73.6%的mAP。我们可以看到,我们的方法不断改善不同类型架构的性能。