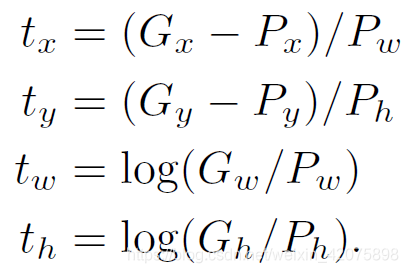建议
在阅读本文之前,请先了解AlexNet
一、论文方法论总结
1. 要解决的问题
(1)如何使用深度网络定位目标
(2)如何使用少量带标注的检测数据(detection data)训练一个可靠的模型
2. 相关工作
(1)目标定位
①将定位视为回归问题(C. Szegedy. Deep neural networks for object detection. In NIPS, 2013)
实践效果不是很好
②sliding-window detector
这种方法常常与卷积神经网络结合使用,其缺陷在于:
- 产生大量候选区域,其中大部分候选区域不包含目标
- 需要事先确定滑窗大小,泛化能力太差
(1)预训练
①无监督预训练
这种预训练方式先使用无监督的预训练,再使用有监督的训练方式对网络参数进行fine-tuning
3. 创新点
(1)在目标定位时使用recognition using regions的方法
(2)在预训练阶段,使用有监督的预训练方式。具体来讲,先使用ILSVRC这个大型数据集有监督地预训练卷积神经网络,再使用PASAL(domain-specific)这个小数据集fine tune卷积神经网络
4. 本论文检测框架
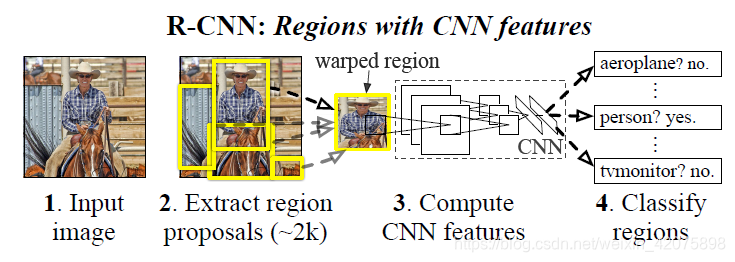
基于recognition using regions的策略。测试阶段:对输入图像产生大约2000个候选区域,再使用卷积神经网络从每个候选区域(需要对候选区域进行变形以符合卷积神经网络的输入尺寸要求)中提取一个固定长度的特征向量。将该特征向量送入已经训练好的SVM中完成目标的分类
如何使用SVM完成目标的分类:在得到了特征向量后,将该向量分别送入不同的SVM,看哪个得分更高?
(1) 候选区域生成模块
基于“控制变量以便与其它目标检测算法比较”的考虑,本文使用了selective search(J. Uijlings. Selective search for object recognition)这种生成候选区域的方法
(2) 特征提取模块
使用ImageNet框架的caffe实现,从每个候选区域中提取出一个4096维的特征向量。在使用卷积神经网络对候选区域提取特征前,需要先对候选区域进行变形以符合卷积神经网络对输入图像尺寸的要求。该论文选用的方法是,对候选区域的bounding box,再向外拓展16个像素,再将其变换成规定大小的尺寸(不考虑候选区域的长宽比)
5. 训练过程
(1) 预训练
使用ILSVRC2012数据集及其图像级别的标签预训练AlexNet神经网络
(2) Domain-specific fine-tuning
- 将AlexNet网络输出层更换成随机初始化后的输出层(输出N+1维的特征向量,N为目标类别数,1为背景)
- 将与ground-truth的IoU超过0.5的候选区域视为正例,其它视为负例
- 随机梯度下降算法(SGD)的学习率设置为0.001
- 每轮迭代使用一个batch,每个batch中共有128个候选区域,包括32个正例,96个负例(负例样本数量显著多于正例样本数量,为了提高模型的泛化性能,设置batch中正例、负例的比例如上)
二、论文实验总结
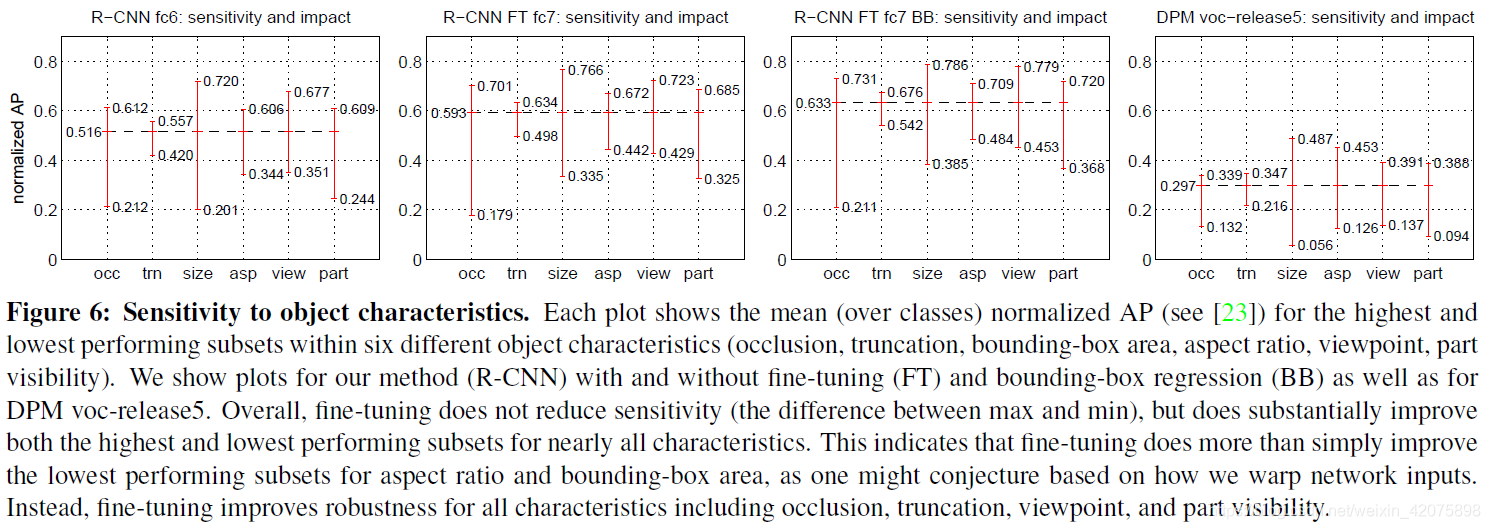
1. 可视化实验
论文作者想要知道卷积神经网络的神经元究竟学到了些什么,为此,作者提出了一种简单直接的可视化思路:
- 对每一个输入图像(变形后的候选区域),在进行第三次池化操作后(第5层卷积层后的池化层),都会得到一组feature map,其尺寸为6x6x256
- feature map中的每个unit,是从输入图像一定范围内提取到的特征。对第三层feature map的中心的unit,对应的原始图像(227x227)中的大小为195x195,边缘的unit对应的原始图像的覆盖范围会相对小一些
- 作者选取了6个位置的unit,将不同输入图像在该位置处的激励进行排序,选取了激励最大的16个图像,如下图所示

如上图所示,相同位置的unit确实学到了具有相同模式的特征
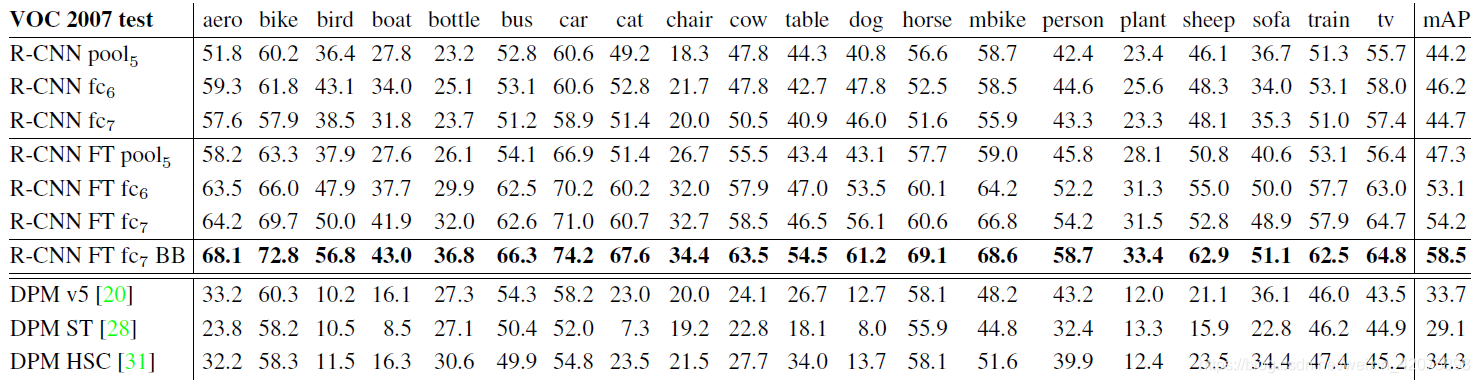
2. 全连接层、fine tune有效性验证
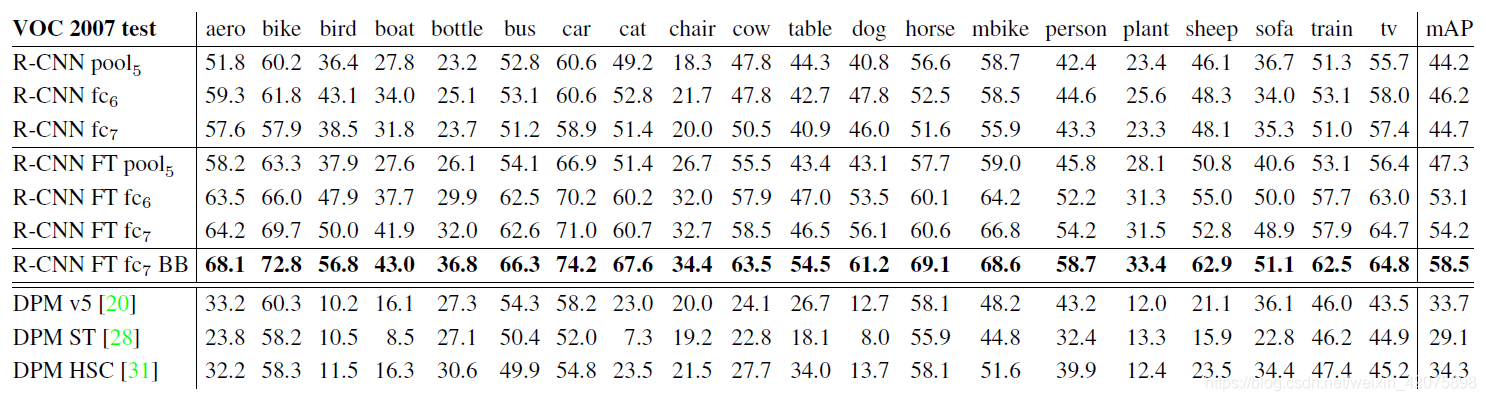
从表中前三行可以得出结论:
- 在不进行fine-tune的情况下,fc7学到的特征的泛化性能比fc6的差,这意味着fc7没有作用,可以被移除,模型的参数可以减少1680万个
- 即使使用pool5后的结果作为输出层,其结果不比使用后两层作为输出差很多,这意味着,卷积神经网络的表征能力主要来源于卷积操作,而不是全连接网络
从表中第4行到第6行可以得出结论:
- 对比前三行,fine tune确实可以极大提高模型性能
- fine tune对全连接层的提升更明显,这表明,池化操作得到的特征更加一般化,对全连接层的参数进行学习可以更有效的学习具化特征
3. 误检测分析
作者使用的误检测分析工具是:
Y.Jia. Diagnosing error in object detectors(论文题目)
作者对四类误检测结果进行了分析:
- loc(poor localization),检测结果分类正确,但是与ground truth的IoU在0.1至0.5之间
- sim(confusion with a similar category),与相似类别混淆
- Oth(confusion with a dissimilar object category),与不相似的类别混淆
- BG(background),将背景错误分类成正例
分析结果如下:
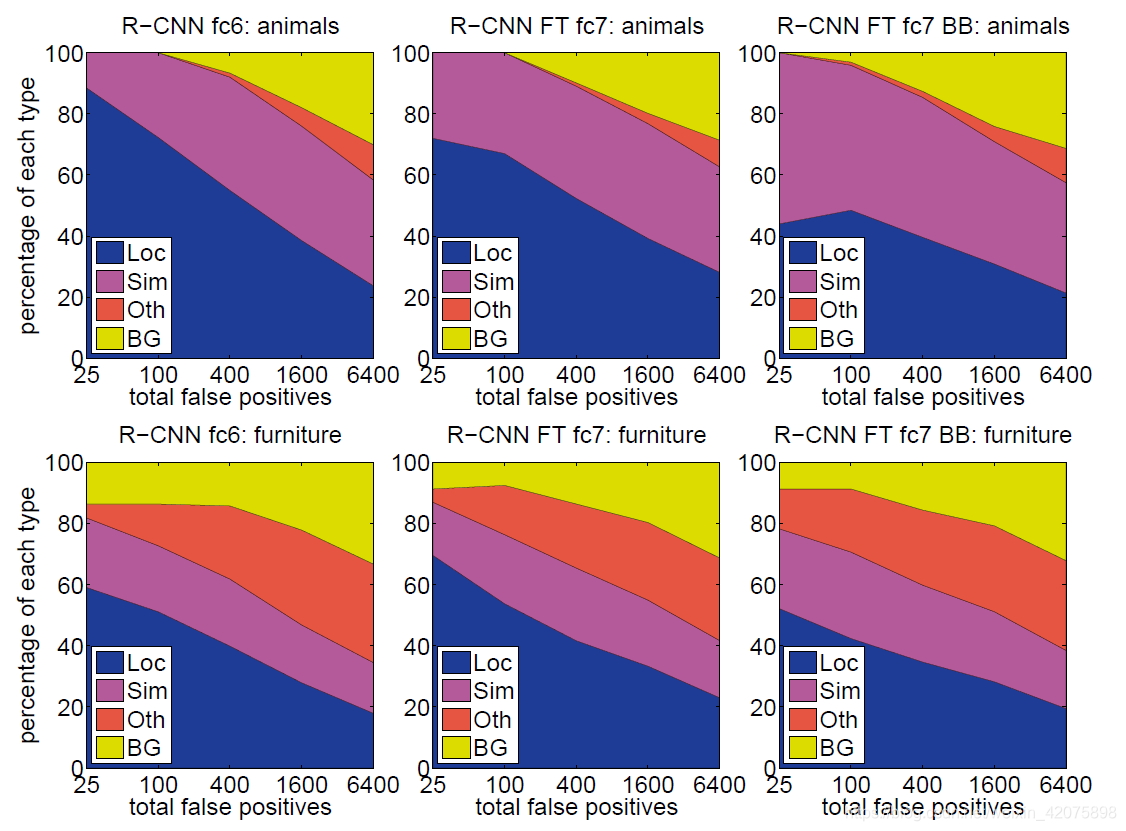
从图中可以得到如下结论: - 误检测结果主要是定位不准,而不是与背景或其它类别目标混淆,这表明,由卷积神经网络得到的特征对不同类别的表征能力还是不错的
- 从另一方面,定位不准的原因可能是:①proposal+evaluate方法的天然缺陷②预训练时使用了image-level的标签
4. bounding-box regression有效性分析
作者选用的回归方法为:
P.Felzenszwalb. Object detection with discriminatively trained part based models(论文题目)
对比实验结果如下:

三、补充材料
1. 关于候选区域变形方法讨论
本文给出了三种变形方法
- 在候选区域的基础上,用一个正方形重新框出目标,再将该正方形扩大或缩小至227x227。正方形的构造规则是,正方形的中心为原候选区域的中心,正方形的边长为原候选区域长和宽的最大值,下图中B列
- 扩大或缩小候选区域,使候选区域的长和宽的最大值为227,未填充满部分使用零值填充,下图中C列
- 直接将候选区域变换至227x227,不考虑原始比例,下图中D列
示意图如下:

对每个示例,上面一行的padding=0,下面一行的padding=16
经过实验验证,D方式+padding=16效果最好
2. 关于正例、负例样本、softmax的讨论
(1) 为什么在fine tune卷积神经网络和训练SVM时使用不同的正负样例评判标准
两种不同的评判标准:
- fine tune卷积神经网络时,对正负样例的评判标准是:候选区域的预测类别正确且与ground truth的IoU超过0.5为正样例;其它为负样例
- 训练SVM时,对正负样例的评判标准是:ground truth为正样例;候选区域的预测类别正确且与ground truth的IoU小于0.3为负样例
fine tune时使用第一种评价标准效果更好,可能的原因是:
- 存在很多与ground truth的IoU大于0.5小于1且预测类别正确的候选区域,这些候选区域虽然仍与ground truth有差距,但是仍然可以被用来fine tune卷积神经网络,同时也可以避免过拟合
为什么要使用SVM而不直接在卷积神经网络后训练一个softmax层:
- 实验验证,前者比后者准确率高(54.2%VS50.9%)
- 可能的原因是:①fine tune时使用第一种评判标准会带来定位不精确②在训练softmax分类器时使用的是任意的负类样本(第一类评判标准),而训练SVM时使用的subset of “hard negatives”
3. bounding-box回归
(1)基本原理
通过SVM为每个候选区域评分,再对评分最高的候选区域使用class-specific bounding-box regressor,生成一个新的候选区域
(2)公式推导
①regressor的输入
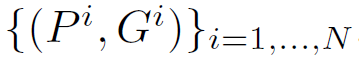
其中
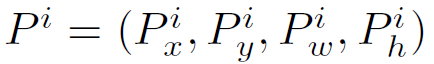 代表第i个候选区域的中心坐标以及候选区域的长和宽
代表第i个候选区域的中心坐标以及候选区域的长和宽
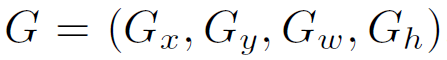 代表ground truth的中心坐标和长与宽
代表ground truth的中心坐标和长与宽
②目标
学习一个映射,将矩阵P映射至矩阵G
③公式化描述
要学习的映射实际上是四个函数:
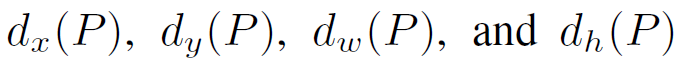
其中,前两个规定了候选区域中心的尺度不变性,后两个规定了候选区域按对数规律回归
若学到了上述四个函数,就可按下述四个公式完成回归:
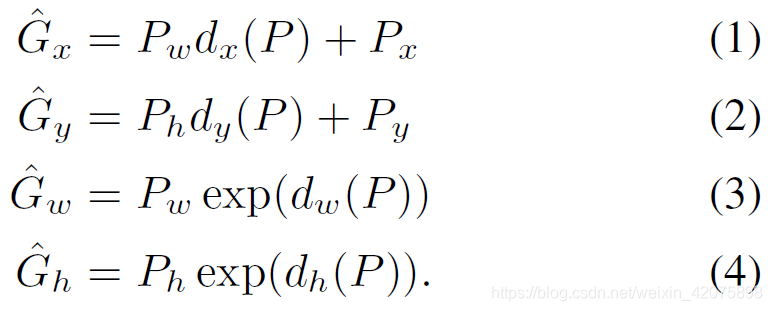
上述四个函数被建模为线性回归问题,如下:
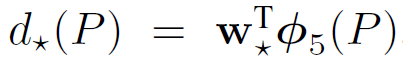
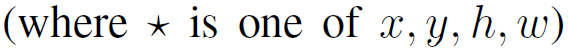
其中,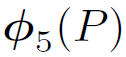 代表候选区域P在卷积神经网络第三层池化层得到的特征
代表候选区域P在卷积神经网络第三层池化层得到的特征
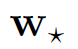 是我们要学习的参数,其优化目标函数如下
是我们要学习的参数,其优化目标函数如下
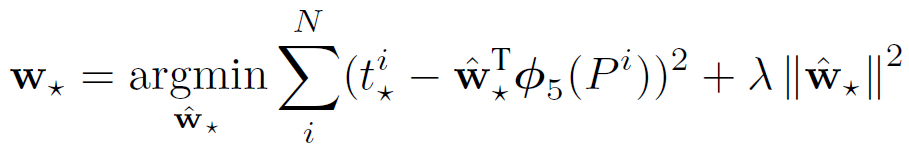
其中