目录
4.2 Category-aligned Embedding
1. 题目

论文提出了detection hub,检测中心,目的是统一目标检测数据集,方法是利用语言嵌入实现query adaptation。论文作者来自于三个机构:复旦大学计算机学院互联网信息处理上海重点实验室,上海智能视觉计算协同创新中心,以及微软。
2. 介绍


各个数据集的类别分布有较大的差异: (1)相交的部分:类别名称不同,但是语义相似,embedding较为接近 (2)相交之外特有的部分:类别不一致/歧义,一个类别在另外一个数据集中被当作背景。
3. 相关工作

3.1 Sparse RCNN

1. 给定 N 个提议框,Sparse R-CNN 首先利用 RoIAlign 操作为每个框提取特征
2. 在动态实例交互之前,将自注意力模块应用于对象特征集,以推理对象之间的关系。
3. proposal bbox 丢失了物体的形状与尺寸信息,所以引入和其个数相等的proposal features,其通过线性映射得到卷积核参数,与object feature进行交互
4. 标签分配:二分图一对一标签分配,使得推理时无需nms,以实现端到端
5. 对于迭代结构,新生成的对象框和对象特征将作为迭代过程下一阶段的提议框和提议特征。即级联结构
6. 学习到的提议框是训练集中潜在对象位置的统计数据,可以看作是对图像中最有可能包含对象的区域的初始猜测,而不管输入如何(与RPN不同)
3.2 YOLO9000
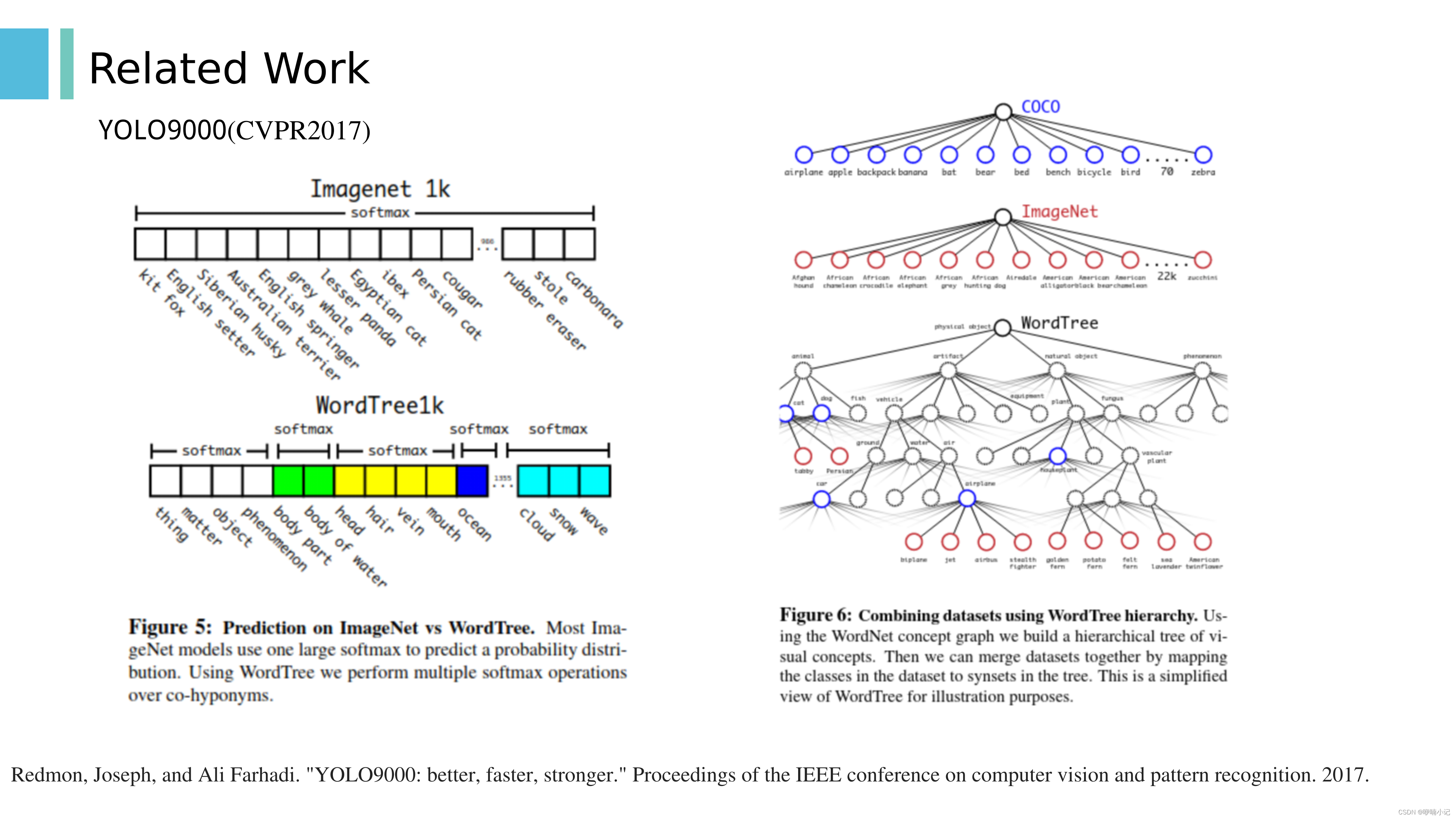
1. Stronger:分类和检测数据进行联合训练
2. 在训练的过程中,对于目标检测数据,使用完整的YOLO v2 loss反向传播;对于图像分类数据,只用整个结构中分类部分的loss反向传播。具体讲,只需找到预测当前图像类别的概率得分最高的边界框,然后仅在其预测树上计算损失即可。
3. 统一标签空间是利用wordnet建立层级标签树。wordnet是一个语义词汇库,是一种有向图结构,作者利用ImageNET和coco中的类别从wordnet中抽出一颗层级标签树。
4. 分类头保持不变,只是在进行softmax时,仅对同一层的类别进行softmax
3.3 Detecting 11K Classes

1. 这篇文章的出发点:已有的目标检测数据集要么完全标注但是规模较小,如PASCAL VOC和MS COCO,要么规模较大,但是仅部分类别的物体有框的标注。 比如ImageNet数据集, ImageNet有 11K 类别,总共有 12M 个训练图像。然而,只有3K个类别和少于1M的训练图像有边界框注释,剩下的是图像级标注,每个图像有多个分类标签。 3k个类别是较粗粒度的类别,剩下大部分图像级标注的类别是细粒度的。
2. 通过本文的方法,可以实现:只需要为所有细粒度类别收集一小组粗粒度类别的边界框标注和图像级的标注,即可,这可以显著减少注释成本
3. 方法概览:
(1)主要结构如图一所示,包括全监督检测模块,弱监督检测模块以及相关组件(相关组件的作用是为了两个检测模块之间的信息传递)
(2)图一:backbone和RPN是共享,其中RPN模块仅使用有框标注的粗粒度类别的数据进行训练
(3)问题的关键是如何将proposal box级别的分数聚合到图像级分数中,以及如何选择最有可能包含目标对象的proposal bbox
(4)图二:全局池化:使用 max、average 或加权平均池来聚合图像级分数,并使用归一化 softmax 损失
(5)图二:注意力池:它将知识从全监督的流中转移,并有助于创建准确的proposal
(6)图三:输入维度是(Cf +1)×P,Cf + 1 是粗粒度检测类加上背景的数量,P 是proposal的数量,中间的模块自己讲,输出的维度是Cw ×P,和图二中弱监督分支输出对应元素相乘
(7)图二:弱监督模块是两个分类损失的加和
3.4 UODB
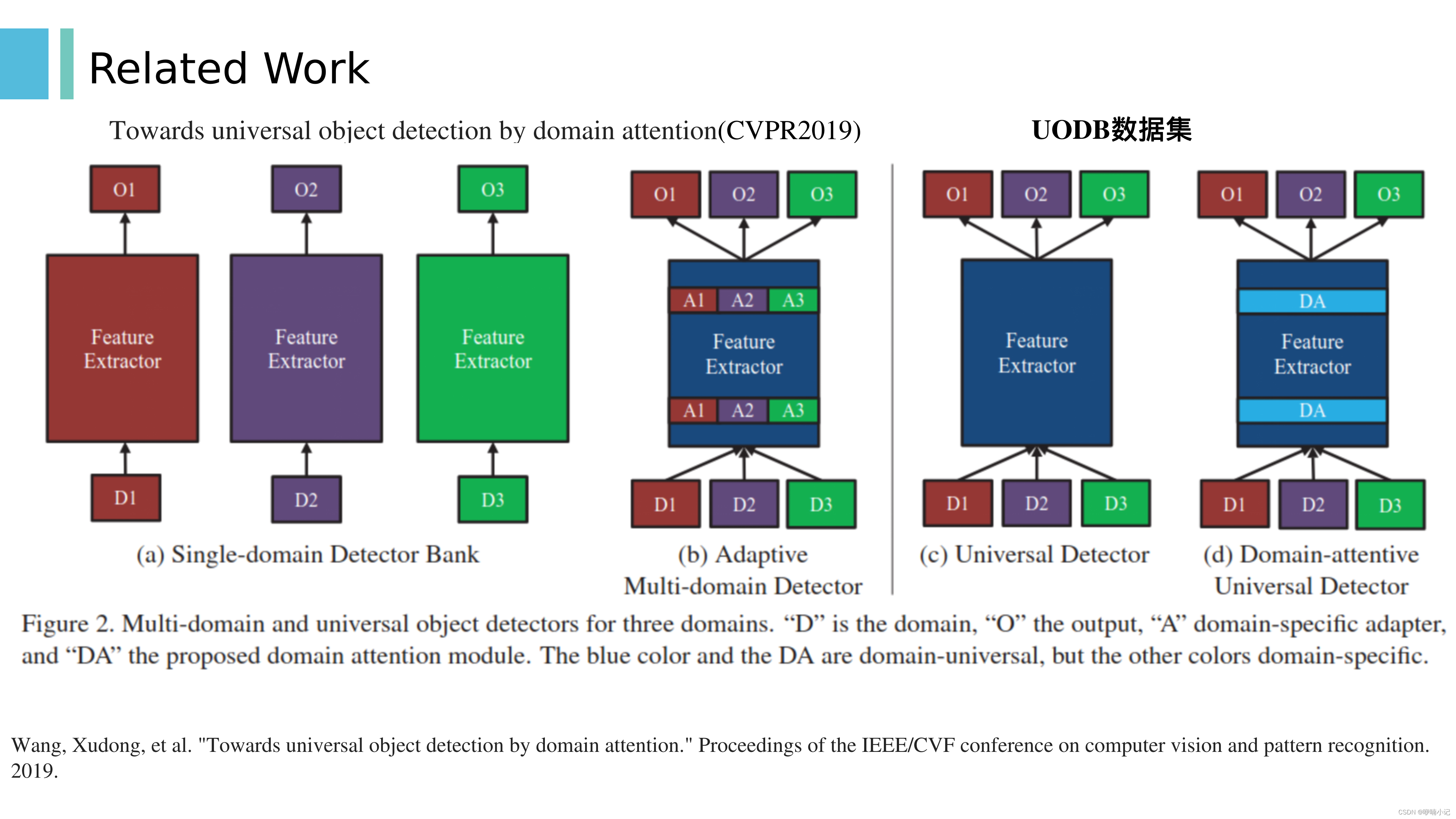
1. 这篇文章,基于域注意实现通用目标检测
2. 建立了一个新的通用目标检测bench mark: UODB,由11个目标检测数据集构成
3. 对于图(c),这是参数共享方面最有效的解决方案,但单个模型很难覆盖许多域,因此提出了图(d)结构 【图(b)是基于硬开关,而不是软的加权】
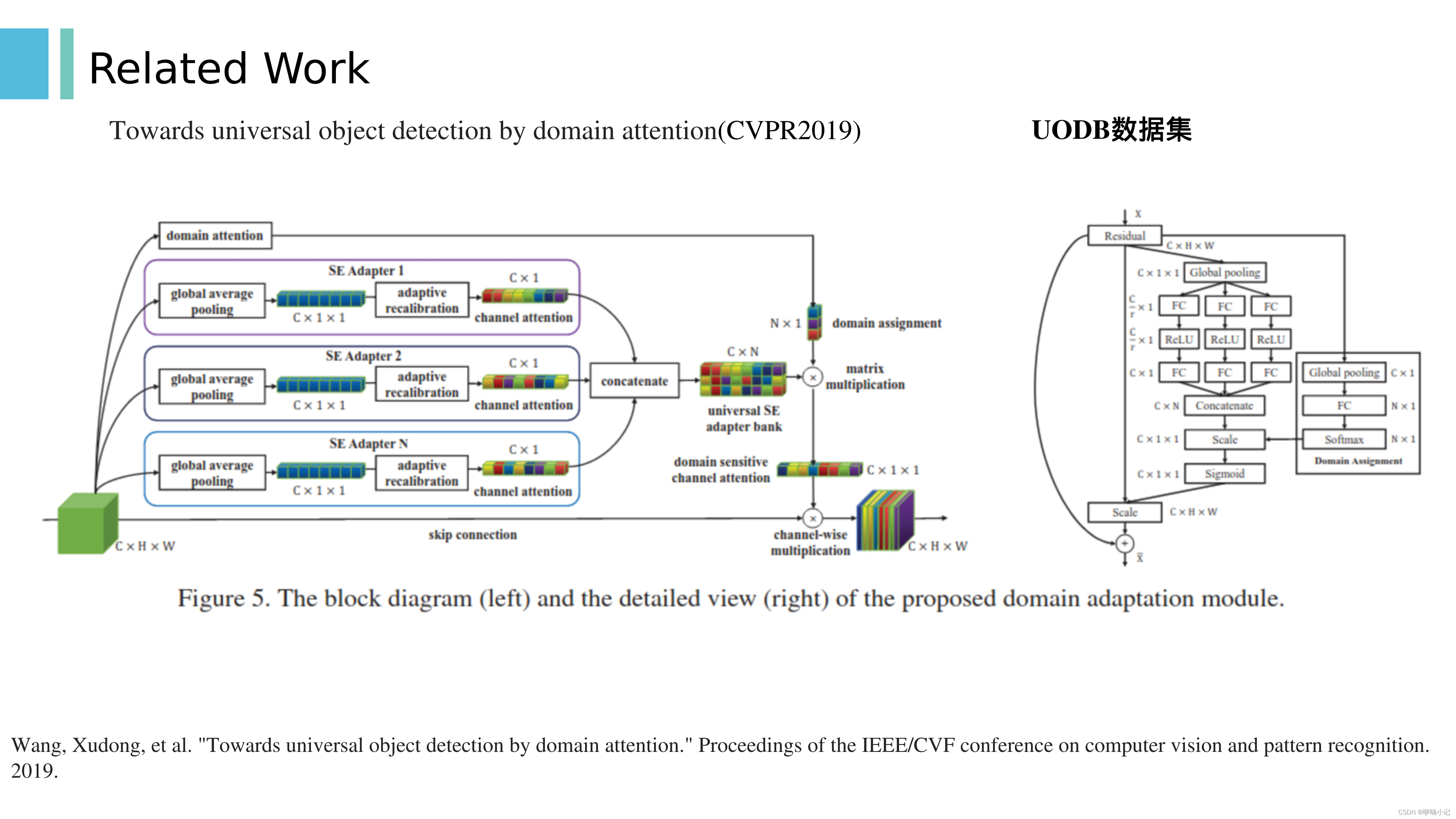
4. 本文的两个贡献:SE Adapter 和 domain attention. 其中SE模块为FC+ReLU+FC组合而成
5. 对于backbone中的某一个特征图,通过N个并列的SE Adapter模块后拼接在一起,由domain-attention模块预测各个SE Adapter模块输出的权重。其中N的个数不必与数据集的个数一致。
6. 具体结构如右图所示。
3.5 unified label space

1. 这篇文章的核心观点是使用伪标签解决标签空间歧义问题,标签空间歧义即一个数据集中的某个类别在另外一个数据集中可能被当作背景类
2. 本文使用FasterRCNN作为基准检测器
3.
(1)第一步,独立训练N个特定于数据集的目标检测器(N等于数据集的个数)
(2)第二步,对于某个数据集,使用除它的特定的目标检测器之外的所有目标检测器对其进行推理,得到其在其标签空间之外的伪标签
(3)利用伪标签进行训练,训练时,每个mini-batch中只含有来自同一个数据集的样本。 伪标签存在噪声:因为各个数据集之间存在域分布的差异,并且检测器本身也会存在误差。因此在标签分配时,为每个anchor分配多个伪GT,以此对抗伪GT的不确定性以及平均潜在的噪声。 对于每一个没有和原本的gt匹配成功的anchor,和它的IOU大于一定阈值的伪gt被初步选中,再判断该anchor在这些伪gt的类别上的得分是否大于一定阈值,两步筛选后剩下的都是其gt,若一个伪gt都没有剩下,那么该anchor就是真的背景。
4. 作者为什么可以使用伪标签呢?那是因为作者为几个测试集的合体,收集了缺失的类别的标注。这和本文是不一样的,本文不为测试集重新制作缺失的标注。
3.6 Unidet

1. 研究的问题是如何自动地将数据集特定的输出集成到一个共同的语义类别空间中
2. 重点在于自动的映射,而不去手动地合并各个数据集的类别空间
3. 训练时如图(b)所示,在推理时如图(c)所示,要自动学习一个从数据集特定的输出头到共同语义类别空间的映射矩阵,其中,映射矩阵中的值只能取0或1 .
4. 大概思想是Dk映射到D后,再利用映射矩阵的转置,映射回Dk’,计算二者的差异,见右上角公式,优化方法使用整数线性规划。
3.7 Word2Vec
1. 要实现的目标是将one-hot编码转换为实数域下的固定长度的编码。(one-hot编码的长度就不固定,维度随着词汇表的增多而增多,越来越稀疏,对模型的训练是负面的影响,再者one-hot无法衡量词汇之间的距离)
2. 实数域的embedding可以通过加减,点乘等操作,可以衡量语义的远近,且固定长度,不会随词汇表的变化而变化
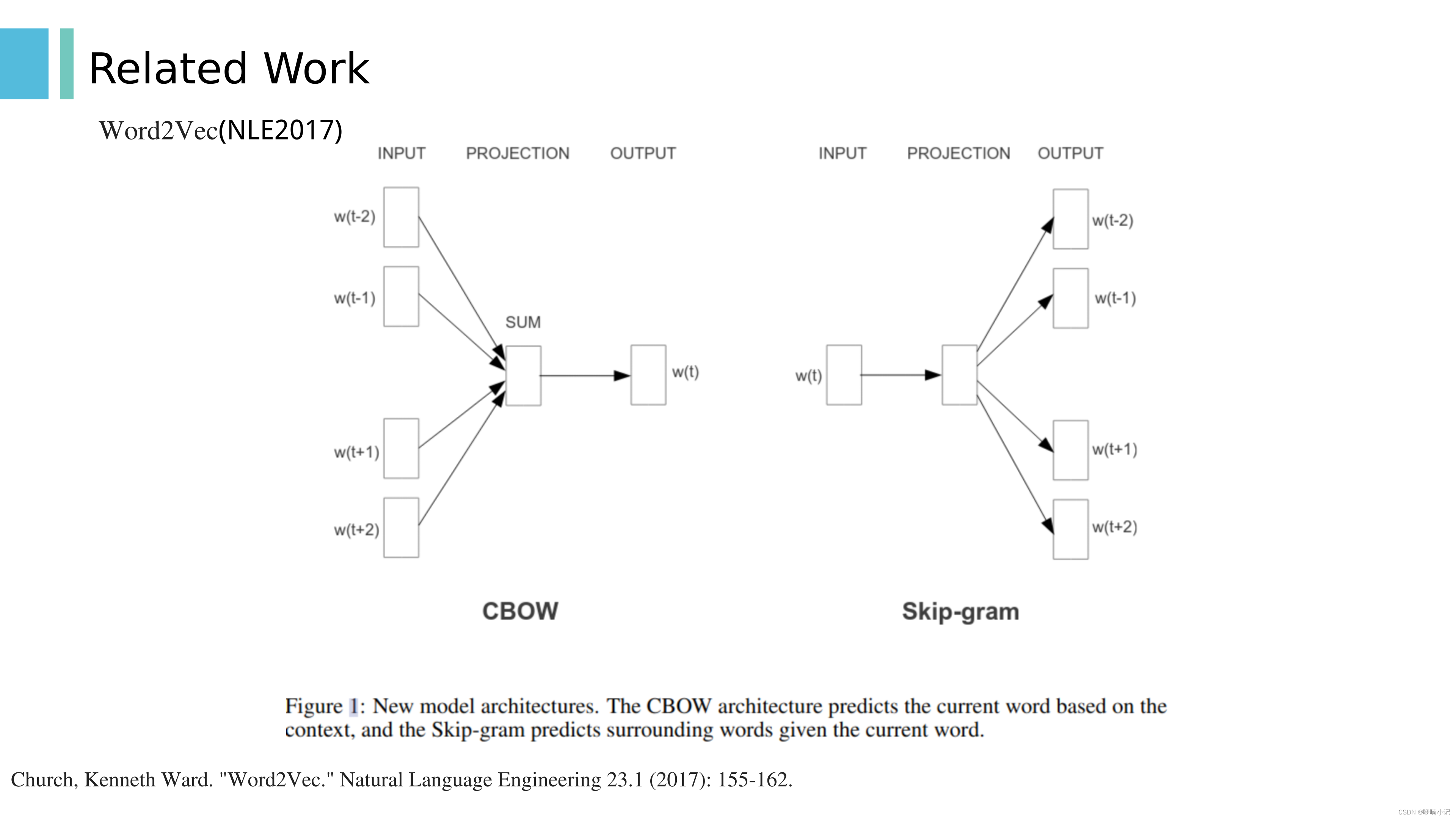
3. 模型可以认为是具有一层隐藏层的MLP,对于CBOW来说,MLP的输入是中间目标词的上下文单词的ONE-hot向量的加和,输出层使用softmax激活,标签是中间目标词的one-hot向量。因此输出层维度和输入层维度相等
4. 当这个MLP训练好以后,并不会用这个训练好的模型处理新的任务,真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵
5. 这个MLP模型根据输入和输出的不同,分为两种,一般分为CBOW(Continuous Bag-of-Words) 与Skip-Gram。
3.8 BERT
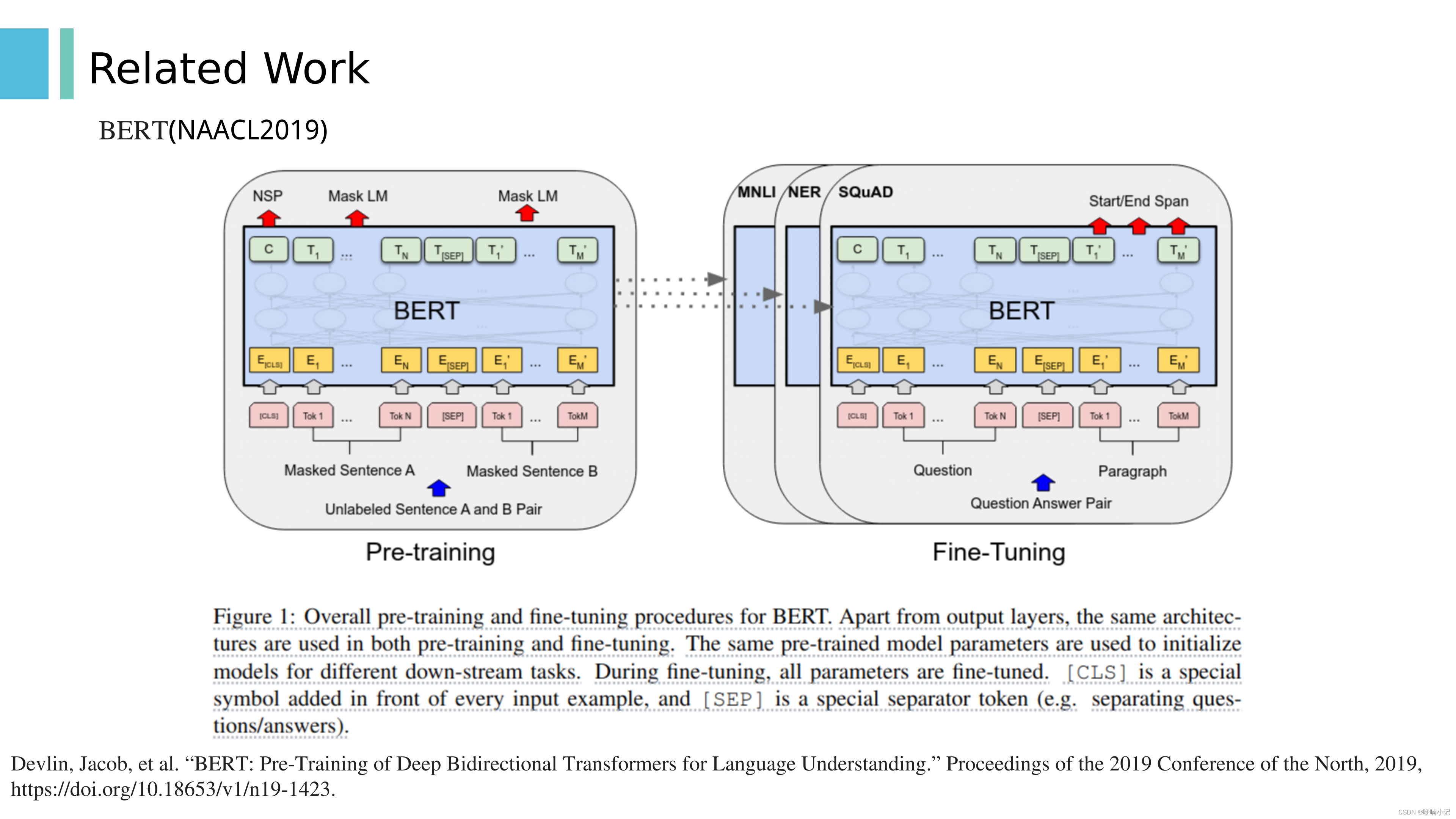
1. BERT是利用大规模文本数据预训练的模型,可用于多种下游任务
2. 预训练期间,使用掩码等方式使模型预测被mask掉的词
4 方法
4.1 概览

主要贡献有以下两部分:分别是Category-aligned Embedding和Dataset-aware Query。
4.2 Category-aligned Embedding

1. 对于分词方式:
(1)word base:这种分词方式,会将两个本身意思一致的词分成两个毫不同的 ID,如 cat, cats
(2)character base:分词后的每个 char 字符是毫无意义的,而且输入的长度变长不少
(3)为了平衡以上两种方法, 又提出了 subword tokenization
2. 在对齐损失中,S的维度:N*L,是region-word对齐得分矩阵,(N*d) * (L*d)T,N是object features的个数,L是language features的个数量。 tokeni,j是否属于Ti的含义是:假设一个gt的类别是sports ball,假设其经过subword分词器后被分成两个词:sports和ball,那么这一个类别就被转换成了两个token。
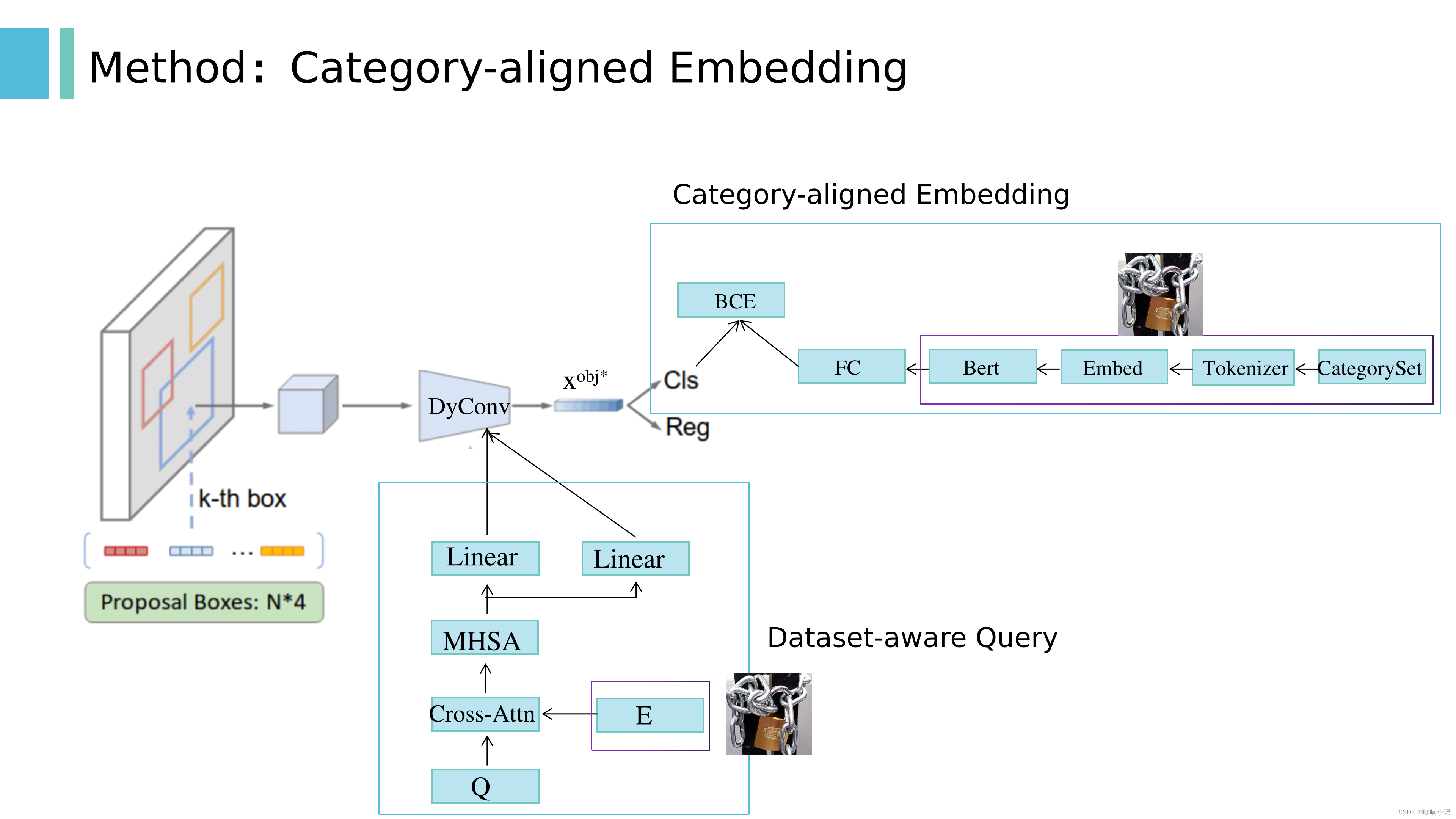
4.3 Dataset-aware Query

1. 训练期间E的构成:从组合的数据集中随机采样一个batch,根据这个batch中的每张训练图像的类别和其所属的源数据集,采样类别名称,形成Category set,进而得到E。后面的消融实验有介绍
5 实验
5.1 数据集

5.2 对比实验/消融实验

1. 表一:训练1x,简单的将不同的标签空间映射到一起不work,性能下降,而基于query的联合模型在各个数据集上的性能更好。
2. 图三:在不同训练代数下,多数据集联合训练鲁棒性和稳定性:联合训练性能均高于单一训练
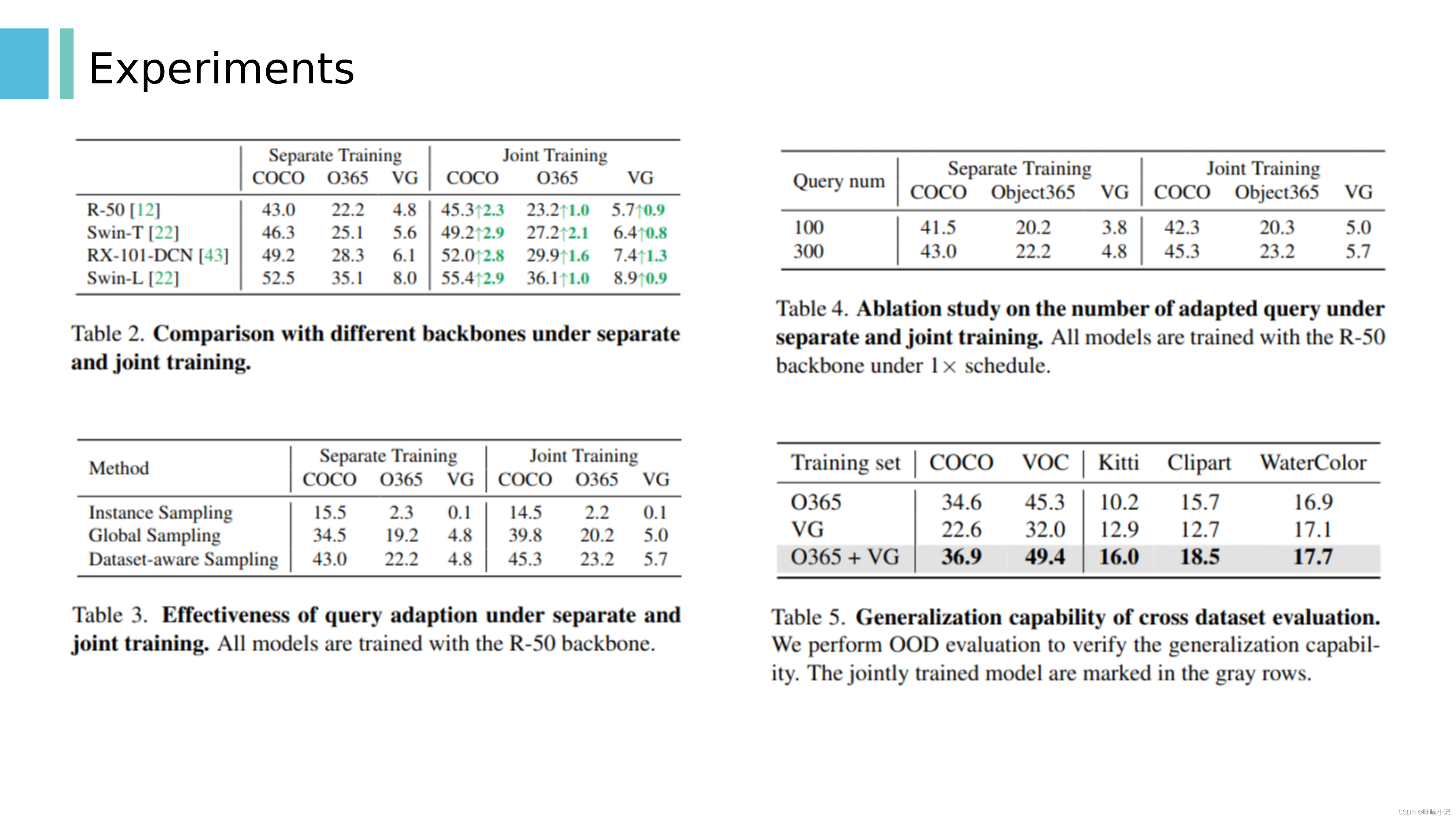
3. 表二:使用不同的backbone的鲁棒性
4. 表三:评估query adaption方法的有效性,“实例采样”意味着只考虑属于每个训练图像的类别。这限制了类别嵌入对图像级的使用,其中来自不同图像的类别彼此不交互;“全局采样”意味着我们考虑所有数据集的类别。这允许不同数据集中的所有类别相互交互
5. 表四:使用不同数量的adapted queries的消融实验,数量越多的query会带来更多的性能增益
6. 表五:跨数据集评估的泛化能力

7. 表6:对模型组件的评估:从sparse RCNN到模型基线的演变
8. 表7:和一些基于query的SOTA模型的对比实验,均使用resnet50作为backbone,在coco验证集上进行评估

9. 表八:在极端变化的数据集上的有效性,即在面提到的UODB数据集上评估
10. 表九:和最近的利用多数据集的方法进行对比,本文在Object365和Visual-Genome上实现了新SOTA。(Swin Large backbone;2x schedule;multi-scale training. During evaluation, we evaluate our best model with multi-scale testing,别的方法没有使用多尺度测试)
5.3 可视化

图四:可视化部分:第一个奇数行显示预测的类别名称。偶数行显示哪个数据集有助于最终预测。 (在预测/推理时,应该是使用所有数据集的所有类别名称的embedding输入到模型当中)