Video Salient Object Detection via Fully Convolutional Networks
(IEEE Transactions on Image Processing, 2017)
本文提出了深度学习模型来有效检测视频中的显著性区域。它解决了两个重要的问题:1)深度视频显著模型训练缺乏足够多的像素注释视频;2)快速视频显著性训练和检测。
提出的深度视频显著性网络包含两个模型来分别获取空间和时间显著性信息。动态显著性模型直接包含基于静态显著性模型的显著性测量,直接产生空间时间显著性推断没有光流计算时间损失。
提出全新数据增强技术从存在解释图像数据集模拟视频训练数据,能使网络学习多种多样的显著性信息和阻止由于有限数量的训练视频引起的过拟合。利用合成视频数据(150K视频序列)和真实视频,提出深度视频显著性模型成功学习包括空间和时间线索,因此产生准确空间时间显著性测量。我们提高了最新技术在密集注释视频分割数据集(MAE 0.07)并且提高速度(所有步骤2fps)。
Saliency models can be broadly classified into two categories: human eye fixation prediction or salient object detection.
对数据集介绍:
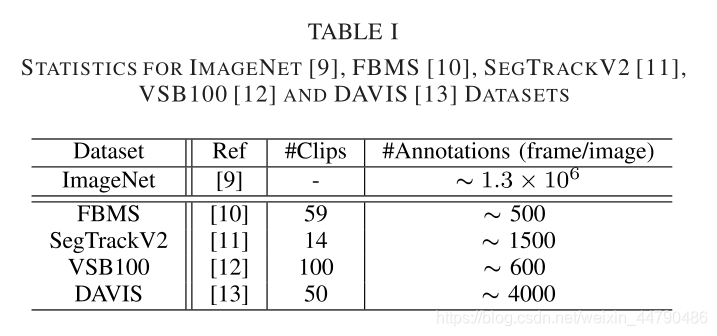
视频显著性检测的一个瓶颈——time efficiency
贡献:1)We investigate convolutional neural networks for end-to-end training and pixel-wise saliency prediction in dynamic scenes. As far as we know, this is the first work for applying deep learning to video salient object detection.
( 利用cnn来解决食品显著性目标检测问题)
2)We propose a novel training scheme based on synthetically generated video data, which explicitly leverages existing rich image datasets; both static and dynamic saliency information are encoded into a unified deep learning model.
(提出全新训练框架基于合成生成视频数据,直接利用存在的丰富的图像数据集,把静态和动态显著性信息编码成统一的深度学习模型)
3)Our methods are computationally efficient, much faster than traditional video saliency models and other deep networks in dynamic scenes.
(高效、快速)