2014年R-CNN横空出世,首次将卷积神经网络带入目标检测领域。受SPPnet启发,rbg在15年发表Fast R-CNN,它的构思精巧,流程更为紧凑,大幅提高目标检测速度。在同样的最大规模网络上,Fast R-CNN和R-CNN相比,训练时间从84小时减少为9.5小时,测试时间从47秒减少为0.32秒。在PASCAL VOC 2007上的准确率相差无几,约在66%-67%之间。

Fast R-cnn
框架介绍:
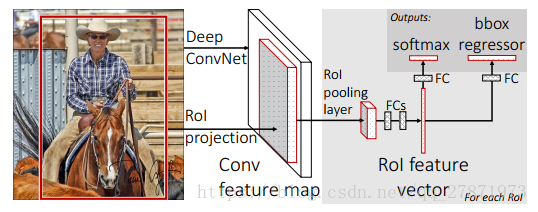
一张包含多个RoI(regions of interest)的图片(上图便于说明只显示一个RoI,灰色部分)输入一个多层的卷积网络中,获得Conv feature map,然后把图片的候选区域映射到feature map得到对应的patch(这和SPPNet的处理类似).然后把这个patch塞给ROI层(Region of interest)得到固定大小的的特征向量(feature vector)。对于每一个RoI,经过FC层后得到的feature vector最终被分享:一个进行全连接之后用来做softmax回归,用来对RoI区域做物体识别,另一个经过全连接之后用来做b-box regression做修正定位,使得定位框更加精准。
这里我们主要关注两个问题:
1.RoI层是什么,如何工作?
2.几个阶段怎么在一起的训练?
1.RoI层是什么
RoI层的作用和SPPNet中的SPP层作用类似:乘上启下。
1.承上: 接收在每个候选区域在feature map上投影出的特征patch,输出长度固定的特征向量。
2.启下: 特征向量的长度固定的原因为了对付FC层的特殊要求。
说白了就是如何把不同尺寸的侯选区域提取特征变换成为固定大小的特征向量。RoI层是特殊的SPP层,RoI层是使用单个尺度的SPP层,之所以不用多个尺度的原因是因为多尺度准确率提升不高,但计算量却成倍的翻。
2.特征提取方式
Fast R-CNN在特征提取上可以说很大程度借鉴了SPPnet,首先将图片用选择搜索算法(selective search)得到2000个候选区域(region proposals)的坐标信息。另一方面,直接将图片归一化到CNN需要的格式,整张图片送入CNN(本文选择的网络是VGG),将第五层的普通池化层替换为RoI池化层,图片然后经过5层卷积操作后,得到一张特征图(feature maps),开始得到的坐标信息通过一定的映射关系转换为对应特征图的坐标,截取对应的候选区域,经过RoI层后提取到固定长度的特征向量,送入全连接层。
3.联合候选框回归与目标分类的全连接层

在R-CNN中的流程是先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression进行候选框的微调;Fast R-CNN则是将候选框目标分类与bbox regression并列放入全连接层,形成一个multi-task模型。
cls_ score层用于分类,输出K+1维数组p,表示属于K类和背景的概率。 bbox_predict层用于调整候选区域位置,输出4*K维数组t,表示分别属于K类时,应该平移缩放的参数。

3.Fast R-CNN的训练与测试
1.训练
首先用ILSVRC 20XX数据集进行预训练,预训练是进行有监督的分类的训练。然后在PASCAL VOC样本上进行特定调优(fine tunning),调优的数据集中25%的正样本(与真实框IoU在0.5-1的候选框)、75%的负样本(与真实框IoU在0.1-0.5的候选框)。PASCAL VOC数据集中既有物体类别标签,也有物体位置标签,有20种物体;正样本仅表示前景,负样本仅表示背景;回归操作仅针对正样本进行。
在调优训练时,每一个mini-batch中首先加入N张完整图片,而后加入从N张图片中选取的R个候选框。这R个候选框可以复用N张图片前5个阶段的网络特征,文章中N=2,R=128。微调前,需要对有监督预训练后的模型进行3步转化:
-
RoI池化层取代有监督预训练后的VGG-16网络最后一层池化层;
-
两个并行层取代上述VGG-16网络的最后一层全连接层和softmax层,并行层之一是新全连接层1+原softmax层1000个分类输出修改为21个分类输出【20种类+背景】,并行层之二是新全连接层2+候选区域窗口回归层;
-
上述网络由原来单输入:一系列图像修改为双输入:一系列图像和这些图像中的一系列候选区域;

4.其他亮点
1.SVD全连接层加速网络
图像分类任务中,用于卷积层计算的时间比用于全连接层计算的时间多,而在目标检测任务中,selective search算法提取的建议框比较多【约2k】,几乎有一半的前向计算时间被花费于全连接层,就Fast R-CNN而言,RoI池化层后的全连接层需要进行约2k次【每个建议框都要计算】,因此在Fast R-CNN中可以采用SVD分解加速全连接层计算,具体实现如下:
① 物体分类和窗口回归都是通过全连接层实现的,假设全连接层输入数据为x,输出数据为y,全连接层参数为W,尺寸为u×v,那么该层全连接计算为:
y=Wx(计算复杂度为u×v)
② 若将W进行SVD分解,并用前t个特征值近似代替,即:
W=U∑VT≈U(u,1:t)⋅∑(1:t,1:t)⋅V(v,1:t)T
那么原来的前向传播分解成两步:
y=Wx=U⋅(∑⋅VT)⋅x=U⋅z
计算复杂度为u×t+v×t,若t<min(u,v),则这种分解会大大减少计算量;
在实现时,相当于把一个全连接层拆分为两个全连接层,第一个全连接层不含偏置,第二个全连接层含偏置;实验表明,SVD分解全连接层能使mAP只下降0.3%的情况下提升30%的速度,同时该方法也不必再执行额外的微调操作。

2.图片中心化采样image-centric sampling
R-CNN和SPPnet中采用RoI-centric sampling:从所有图片的所有候选区域中均匀取样,这样每个SGD的mini-batch中包含了不同图像的样本,不同图像之间不能共享卷积计算和内存,运算开销大。
Fast R-CNN中采用image-centric sampling: mini-batch采用层次采样,即先对图像采样【N个】,再在采样到的图像中对候选区域采样【每个图像中采样R/N个,一个mini-batch共计R个候选区域样本】,同一图像的候选区域卷积共享计算和内存,降低了运算开销。
image-centric sampling方式采样的候选区域来自于同一图像,相互之间存在相关性,可能会减慢训练收敛的速度,但是作者在实际实验中并没有出现这样的担忧,反而使用N=2,R=128的image-centric sampling方式比R-CNN收敛更快。
参考链接:
https://www.jianshu.com/p/fbbb21e1e390
https://blog.csdn.net/qq_27871973/article/details/81121995
https://blog.csdn.net/u011974639/article/details/78053203
