R-FCN: Object Detection via Region-based Fully Convolutional Networks
背景介绍
R-CNN 系列的方法,如 SPPnet、Fast R-CNN、Faster R-CNN 等方法在 Object Detection 上取得了很大的成功。这些方法的网络结构被 RoI pooling 层分成两个子网络:共享的全卷积子网,RoI-wise 的子网络。这样设计的一个主要的原因是,借鉴自那些经典的分类网络结构,如 AlexNet、VGG Nets 等,这些网络结构都是卷积子网络,再接一个 pooling层,之后再接几个全连接层。很容易将分类网络的 spatial pooling 层对应到 RoI pooling,将分类网络转化成一个用于 detection 的网络。
当前 state-of-art 的分类网络,如 ResNet、GoogleNet,都是全卷积网络。很自然地将这样的分类的全卷积网络的结构应用到 Detection 网络上。ResNet 的论文中提出了,一种使用 ResNet 作为特征引擎的 Faster R-CNN 方法,将 RoI pooling 层插在两个卷积子网络之间。RoI-wise 子网络越深,那么对于有

该文的出发点就是为了减少重复计算,尽可能地共享网络,因此对这种结构,提出了更深层次的理解:分类问题,具有平移不变性(translation invariance);检测 (Detection) 问题,在一定程度上具有平移敏感性 ( translation variance)。前面提到的 将 RoI pooling 层插入到两个卷积子网路之间,就是为了打破 translation invariance,使用这种 region-specific 操作也就是为了尽可能的捕捉检测的 translation variance特性。
该论文巧妙地同时考虑这两种相互矛盾的特性,设计了一个用于 Detection 的共享的全卷积网络结构。
论文概要
为了将 translation variance 引入到全卷积网络中,论文中设计了一种特殊的卷积层作为全卷积网络的输出,该卷积层输出 position-sensitive 的 score map,每个 score map 引入了位置的信息,如 物体的顶部。在网络的最后一层,再接一个 position-sensitive RoI pooling 层,完成对物体的检测。在整个网络框架中,所有可学习的层,都是卷积层,同时把空间位置信息引入特征学习中,使得整个网络可以进行 end-to-end 的学习。
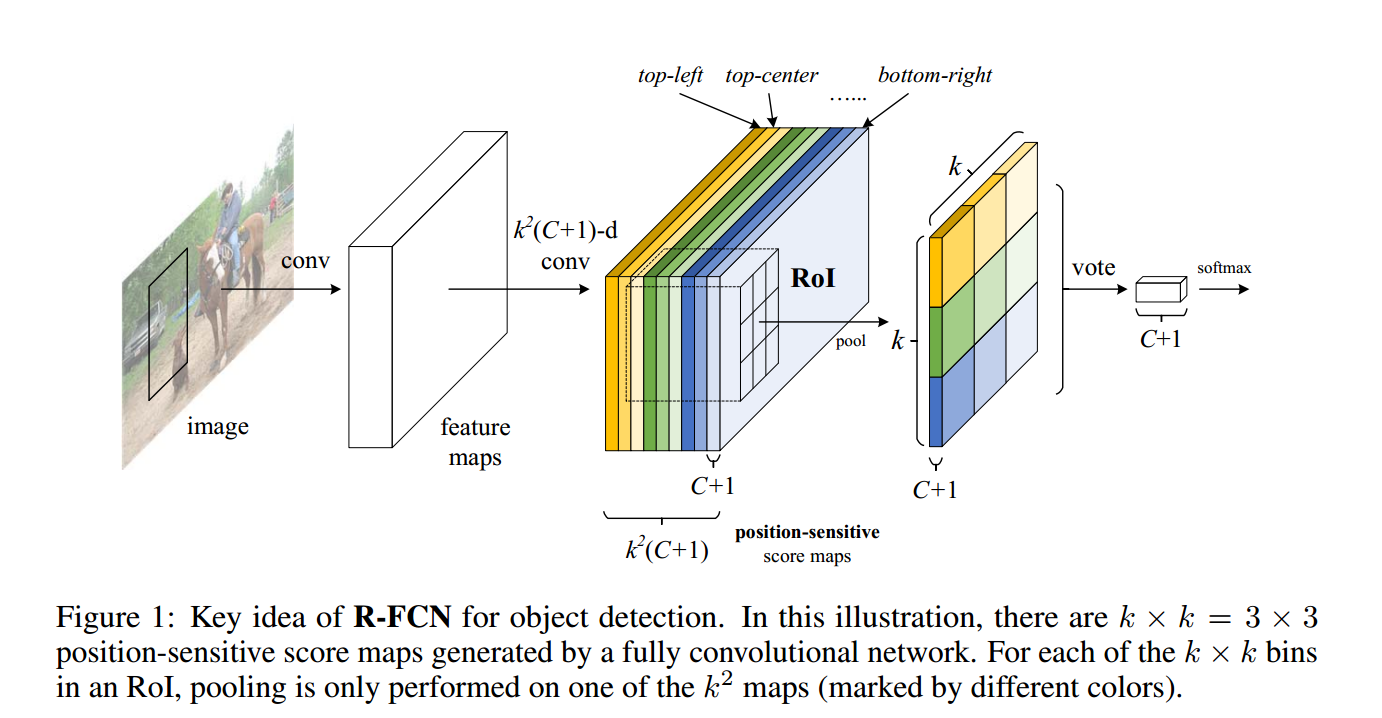
该论文也采用 R-CNN 方法经典检测步骤:生成 region proposal, region 分类。使用 RPN 来生成 proposal,类似于 Faster R-CNN,R-FCN 和 RPN 是特征共享的。在给定 Proposal Region(RoIs) 之后,R-FCN 将 RoIs 分类成目标物体或者背景。在 R-FCN 的网络中,所有可学习的网络都是卷积层,都是在全图上进行操作的,最后一个卷积层为每个类别(包括背景)生成

该论文的方法采用 ResNet-101 的网络结构,去掉最后的 average pooling 层和全连接层,只使用其中的卷积层。ResNet-101 的最后一个卷积层的 feature map 的维度是 2048,新增加了一个卷积层,将维度降成 1024维,这样共享的卷积层也就是 101层。最后再接上生成
为了将位置信息引入到 position-sensitive 的 feature map 中,对于每个 RoI,将其分割成 k*k 个 bins,每个 bin 的大小
其中
每个类别上都可以得到 k*k 个 position-sensitive 的 score,文章直接对这些值求平均值,得到最终的 score,因为分母都相同,均为 k*k,因此这个 score 就可以写成
类似于 R-CNN、Fast R-CNN 等,R-FCN 在最后的特征层,加一层
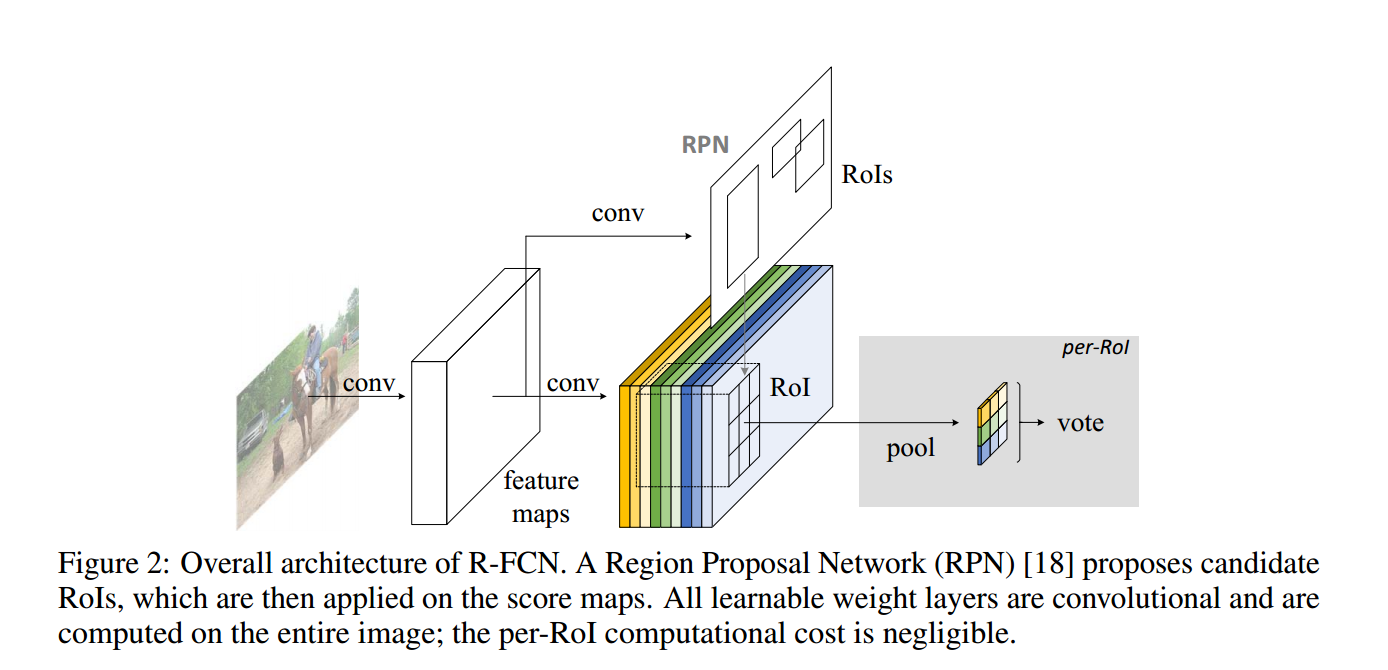
网络结构
文章采用 ResNet 101 的卷积层作为基础的卷积网络结构,再接一个卷积层用于降维,最后接一个产生
训练策略
该论文可以说是 Faster R-CNN 的改进版本,其 loss function 定义基本上是一致的:
在该网络框架下,所有可学习的层,都是卷积层,使用 Online Hard Example Mining (OHEM) ,几乎不会增加训练时间。
网络只使用一种 scale 的图像训练,图像最短的边宽度为 600 像素,每张图像使用 128 个 RoI 用于反向传播。冲量设置成 0.9,权值衰减设置成 0.0005。在 VOC 上 Fine-tuning 过程中,初始学习率设置成 0.001,训练 20k 个mini-batches,学习率为 0.0001,10k 个 mini-batchs。
R-FCN 和 RPN 共享网络参数,训练方式和 Faster R-CNN 的训练策略和步骤基本一样。
使用了 atrous trick。
实验结果
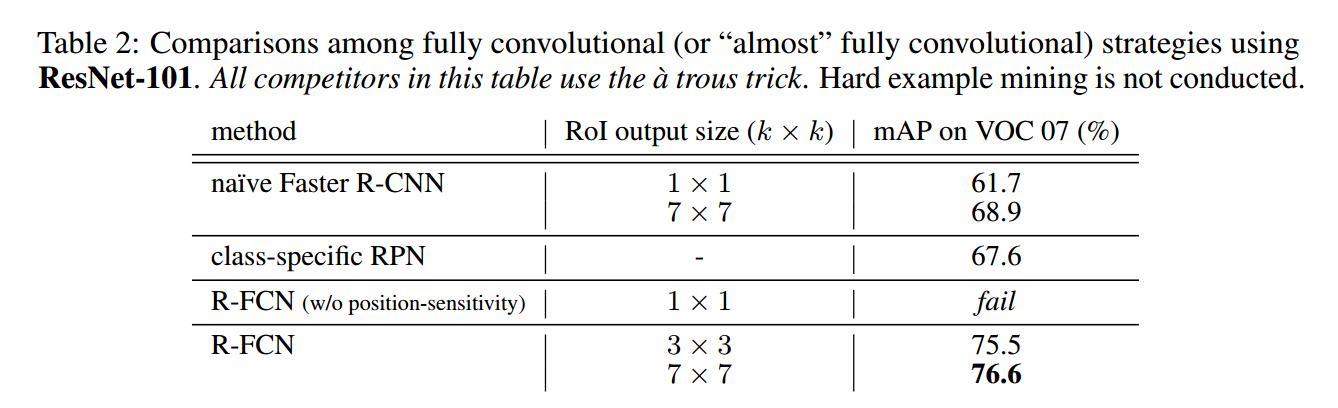
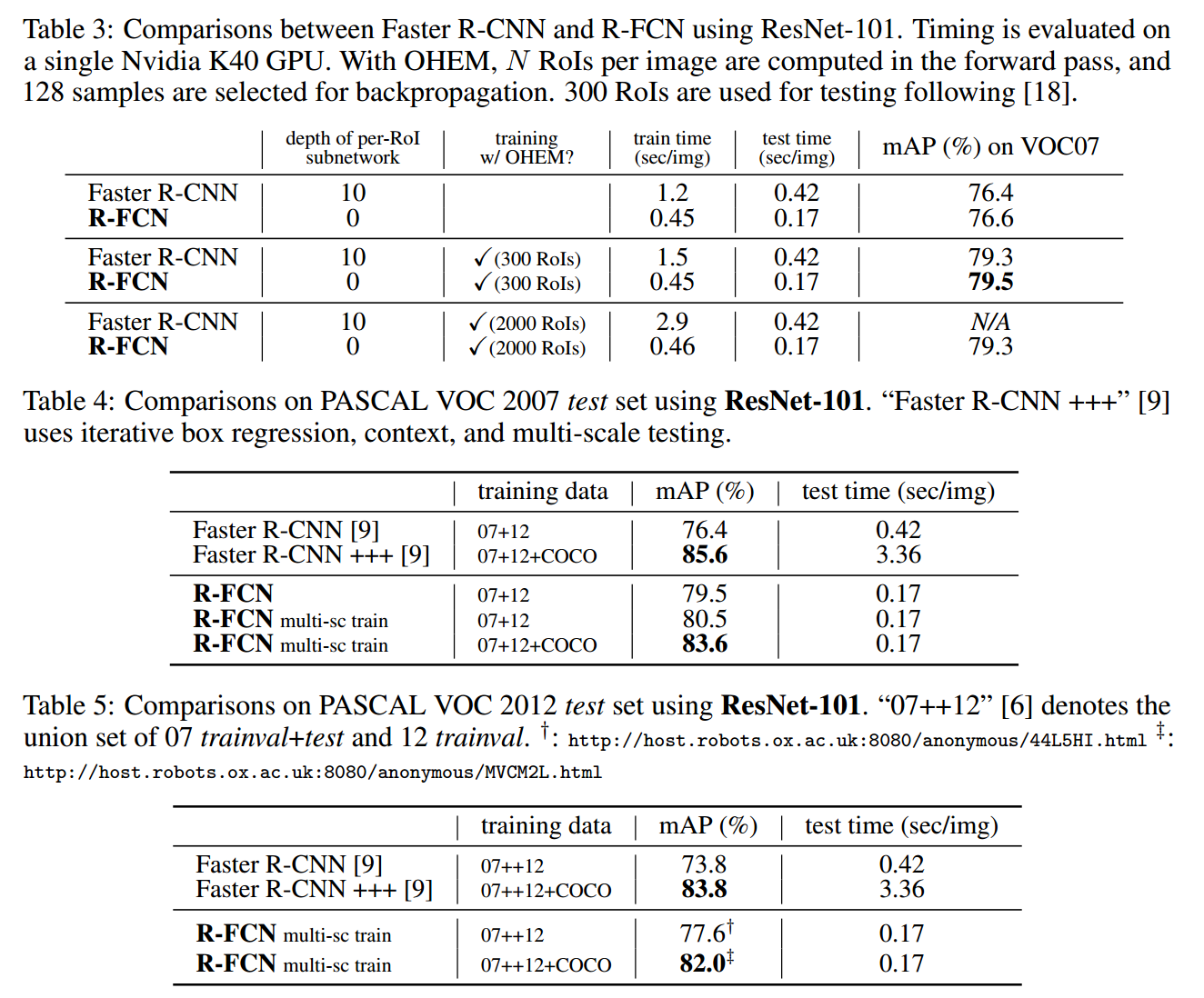
最后总结
该论文也可以归为 R-CNN 系列,其充分利用当前分类最好的网络 ResNet,无论是在准确度还是和速度上都相比 Faster R-CNN 都有很大的提高。R-FCN 使用 position-sensitive score map 将 localization 的 translation variant 的从网络结构中抽离出来,能够充分利用 ResNet 的强大分类能力。
R-FCN 使用全卷积网络,其共享的卷积直接作用于全图,使用 OHEM 不会给训练带来额外的时间消耗,同时使用 atrous trick 使得性能有一定的提升。在 Pascal VOC 2007 上的效果,已经到到了 83.6%。
回望过去,最近一年多以来,在通用物体检测上确实取得了非常了不起的成就。