摘要部分
few shot很多用的都是faster R-CNN为基础,本文用的是one-stage 结构。
用了一个meta feature learner和reweighting模块。
和其他的few shot一样,先学习base数据集,再推广到novel数据集。
feature learner会从base数据集中提取meta feature, 再用这个feature去检测novel数据集。
reweighting模块把一些novel数据的example转为向量,这个向量表示meta feature的重要程度。
所以理解为这是few shot的迁移学习方法。
introduction和相关工作
样本少的时候CNN容易overfit, 推广性比较差。
本文用base数据集和少样本的novel数据集训练,达到同时能识别base和novel数据集的效果。
属于迁移学习,迁移base的knowledge到novel数据。
novel数据有一个query image和一些support images.
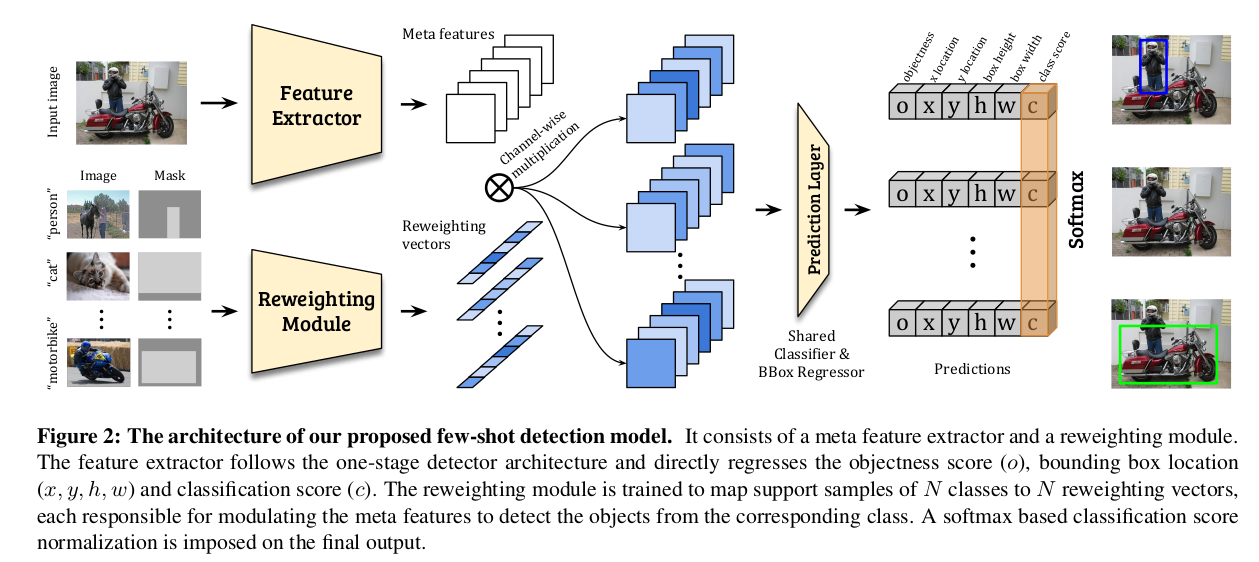
模型包括meta feature learner和re-weighting模块。
meta feature learner从query image中提取meta feature.
re-weighting模块从support image中得到global features, 然后嵌入到re-weighting系数中,
这个系数表示query image meta feature的重要程度。
这样的话,query meta feature就得到了support image的信息,调整到适合novel数据检测的程度。
调整过的meta features送给目标检测的预测模块,用来预测类别和目标框。
总结一下就是先训练得到meta feature,
如果novel数据集有N个类别,那么re-weighting模块会用到N个类别的support images,
得到N个re-weighting向量,每个向量负责检测对应的类别。
两个模块是端到端一起训练的。
paper的方法是2个训练的步骤,第1个训练用base数据,提取meta feature,
第2个训练用novel数据集微调.
当然也设计了损失函数。
之前另一篇survey提到过,迁移学习的缺点是“忘性大”,学习了base数据后,再学novel数据,base数据的检测效果就会下降。
Related Work中也提到了有关迁移学习的只评价了novel类别。而paper是同时评价base和novel的。
方法
backbone用YOLOv2, 用backbone提取meta特征,也就是把backbone作为meta feature extractor.
还有一个re-weighting模块M,设计成一个轻量级的CNN,不影响效率。
meta feature的提取通过query image, re-weighting模块用support image.
re-weighting用来改变meta feature的权重。
比如 I 是 input query image, 那么它的meta feature是一个(w, h, m)的 feature F F F(经过backbone).
所以meta feature有m个feature map.
对于类别 i, support image和bounding box分别为 I i I_i Ii和 M i M_i Mi,
re-weighting模块的输入为( I i I_i Ii, M i M_i Mi),会得到一个与class相关的系数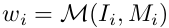
这个系数与 F F F在channel上相乘(实现用1x1 depth-wise卷积),就得到与类别 i 相关的feature F i F_i Fi,
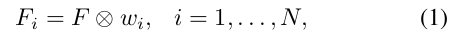
把 F i F_i Fi送进预测模块P,得到objectness score o, 目标框(x,y,h,w)和类别score c i c_i ci, 每个anchor适用。
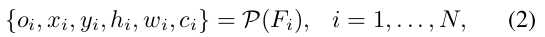
和之前小样本检测一样,把COCO,PASCAL等公共数据集作为base数据集,
把base数据集分成多个小样本检测任务,每个任务由support image和query image组成,
其中,support image是N个类别,query image是其中一个类别。
query image用来做evaluation.
损失函数:
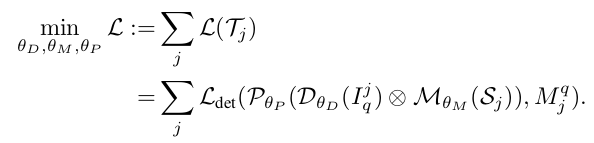
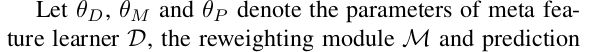
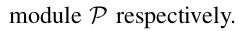
可以理解为query image经过backbong得到meta feature, 然后经过re-weighting得到 着重强调类别 j 的特征,
再经过prediction模块得到bounding box,和query image的box计算损失。
训练分为2步。
第一步用base训练,上面的D,M,P三个模块一起训练。
第2步是小样本微调。用base和novel数据一起训练。
novel数据集中的类别只有k个标注的目标框,为了避免class imbalance,
所以在每个base类别中也取k个box。
训练过程和第一步一样,但是训练epoch数减少,因为样本数量不多。
训练过程中,re-weighting系数由(support image, box)决定,每个epoch它们是随机采样的。
完成第2步的训练后,就不再需要support image, 可以直接检测。
re-weighting系数是取k-shot samples预测出来的系数的平均,
得到这个系数向量之后,re-weighting模块可以在推理中移除,所以几乎没有增加新的参数。
就相当于在prediction之前把特征channel-wise乘一个re-weighting向量。
总的结构图如下:
损失函数
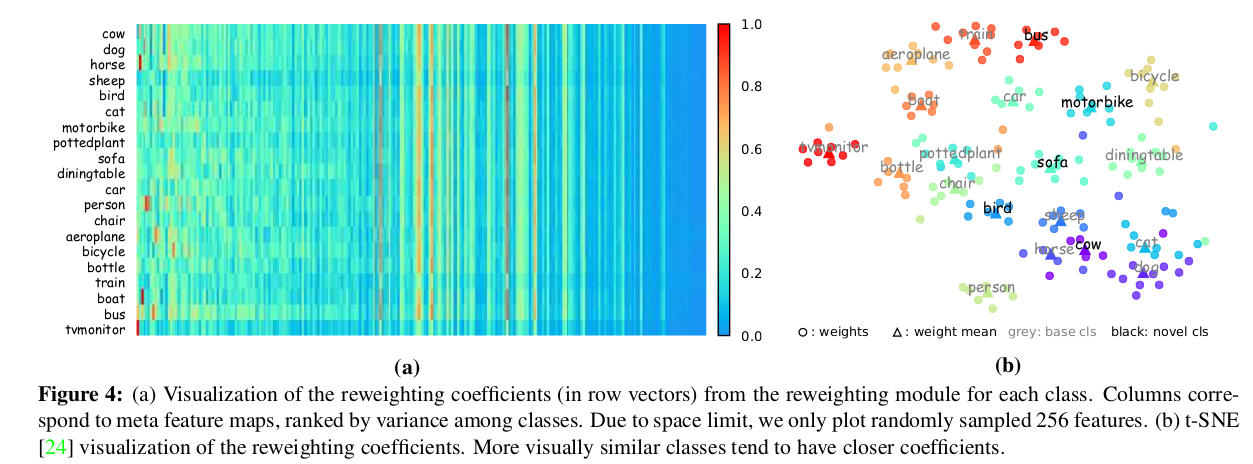
按照之前的描述,在推理过程中,应该是按类别预测的(每个类别一个re-weighting系数)。
所以很容易想到BCE损失函数,是target class就是1,否则为0.
但是用BCE容易出现一片区域预测出多个类别的情况。NMS并不能过滤掉多余的目标框,因为NMS只能过滤同类别的高度重叠的目标框,不同类别的是不过滤的。
作者用softmax校正了class score

根据log函数的性质, c i c_i ci越小, l o g ( c i ) log(c_i) log(ci)负值越小,损失就越大,反之损失越小。
直接BCE的问题在于它必须同时预测一个positive和negative. 而类别又不止两类。
其他损失函数部分和YOLOv2类似,但是 L o b j L_{obj} Lobj处考虑到正样本和负样本的平衡,有些负样本的损失不计算。
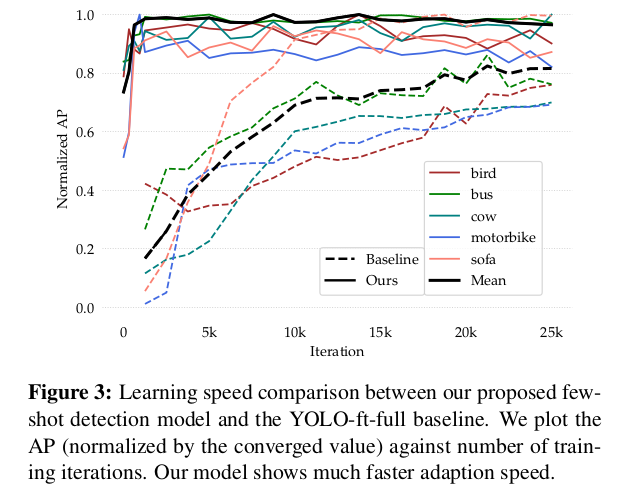
整体的损失函数为
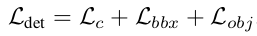
re-weighting模块的input格式
re-weighting模块的input应该是图片中的ROI区域,
一个图片可能有多个类别的目标,所以在RGB通道上再加一个通道Mask, ROI区域内值为1,其他区域为0.
如果同一类目标有多个object, 那么只取一个。
实验
选择VOC07,12,20个类别, train/val用于训练,5个类别作为novel, 15个作为base数据。
COCO数据集中,选择和VOC重合的20类作为novel, 剩下的60类作为base.
几个对比版本:
YOLO-joint: base和novel一起训练,训练epoch和paper方法一致
YOLO-ft:先用base训练,再用novel微调,epoch数和paper方法一致
YOLO-ft-full: 把YOLO-ft训练至完全收敛
LSTD(YOLO): 把Low-Shot Transfer Detector(LSTD)的background depression(BD)和transfer knowledge(TK)实现到YOLO上,训练epoch数和paper一致
LSTD(YOLO)-full: LSTD(YOLO)训练到收敛
VOC数据集的mAP
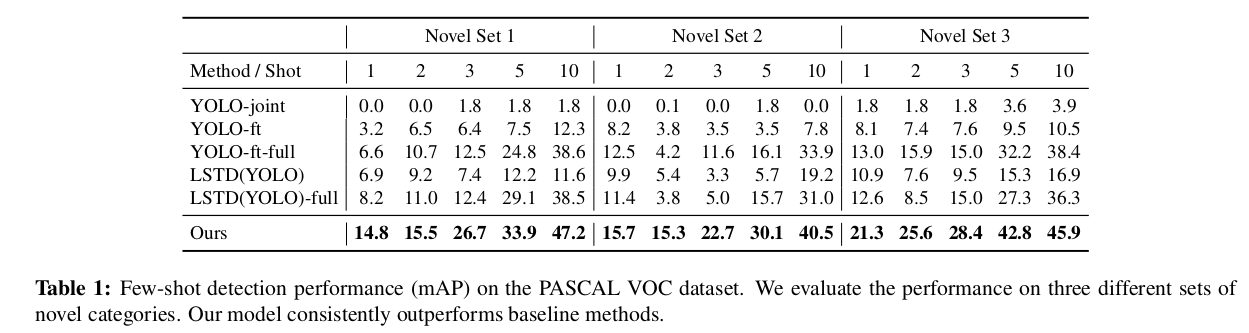
COCO数据集上的mAP
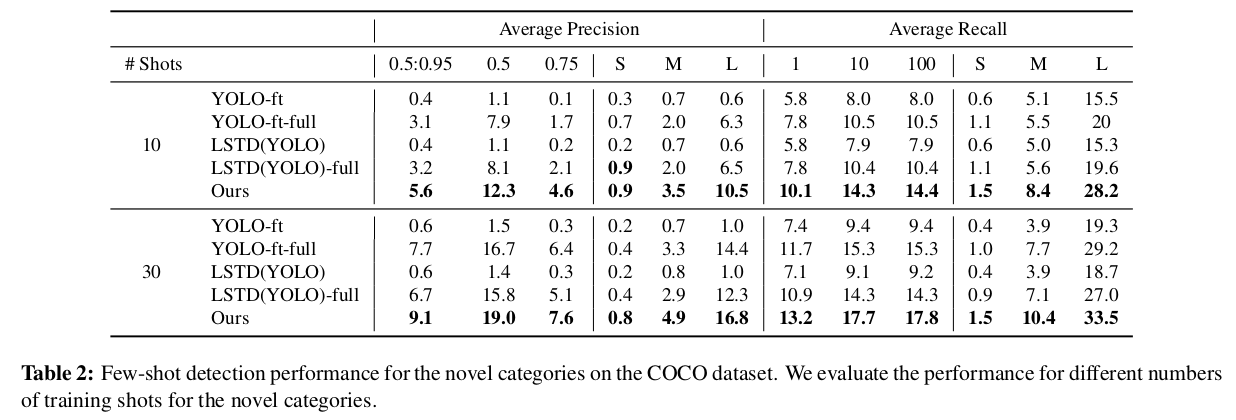
收敛速度对比
re-weighting系数可视化