LLE:Locally Linear Embedding
首先引入一下这个想法:
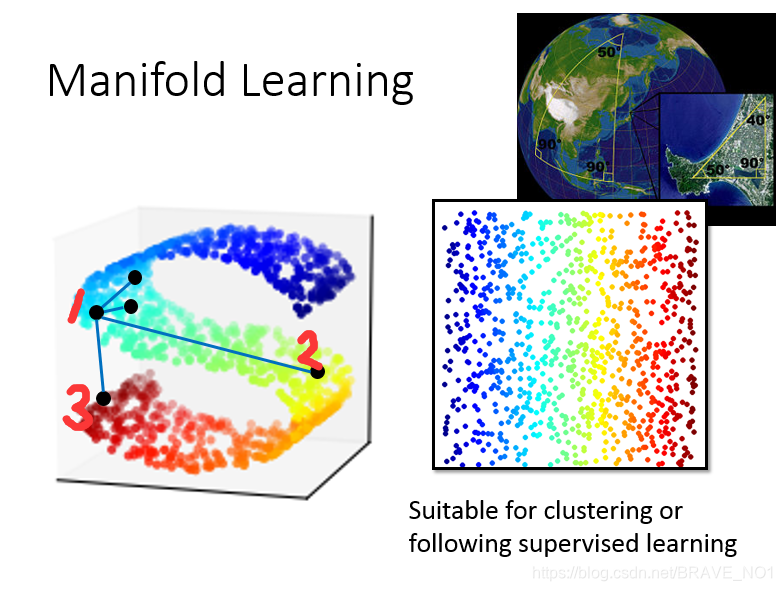
在图中可以看出,在原来的数据中,1与2是距离比较近的,因为你要到达3需要经过2,而降维后我们会导致表示结果中(1和3)比(1和2)近,因此我们需要解决这个问题:采取记录原始”权重“的办法。
- step1:学习原始数据中
之间的关系。

- 然后保持权重
不变,来评估降维后的结果。
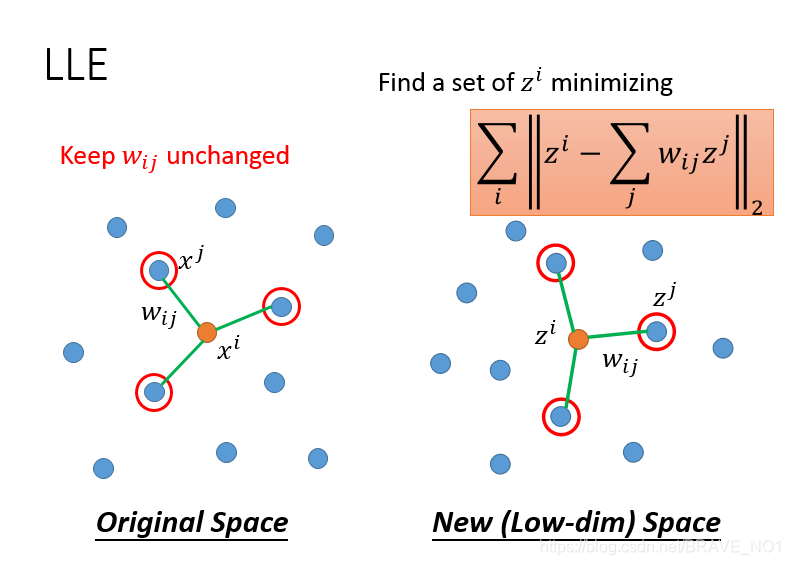
总结:中国有句名句:在天愿做比翼鸟,在地愿为连理枝。在天= ,而比翼鸟则为他们之前的关系。我们降维后,则在地= ,而他们的关系也应该是 ,也就是与比翼鸟类似的连理枝。除此之外,还有LE(Laplacian Eigenmaps),它与半监督中基于图的方法十分类似,基于图学习 ,然后再与LLE类似,基于 ,评估z。
T-SNE(T-distributed Stochastic Neighnor Embedding)
基本思想:只考虑原来距离相近的降维后要距离很近,原来远一点的点降维后距离会更远。
- step1:计算
相似度。计算
相似度。并且用概率的方式表达,这样一来就不存在由于数据大小差距过大而需要数据缩放的问题。

- step2:使用KL散度计算降维前后的变化loss。(这里可以使用梯度下降进行求解)
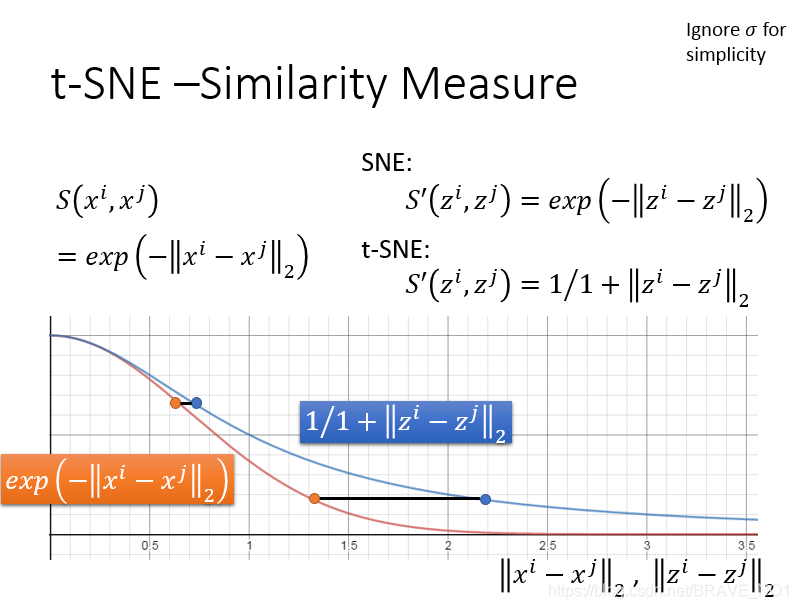
SNE与t-SNE就在于降维数据的相似度求解函数的差别。通过新的相似度函数,原来近的点更近,远的点更远,效果更好。
auto-encoder
encoder:把输入的图片降维变成"code".
decoder:把输出的"code"重建变成图片。
其实就是一个多个Bottleneck的非线性PCA。