2018.10.09开始看李宏毅的机器学习课,把重要的笔记记下来
-
各种模型之间的关系
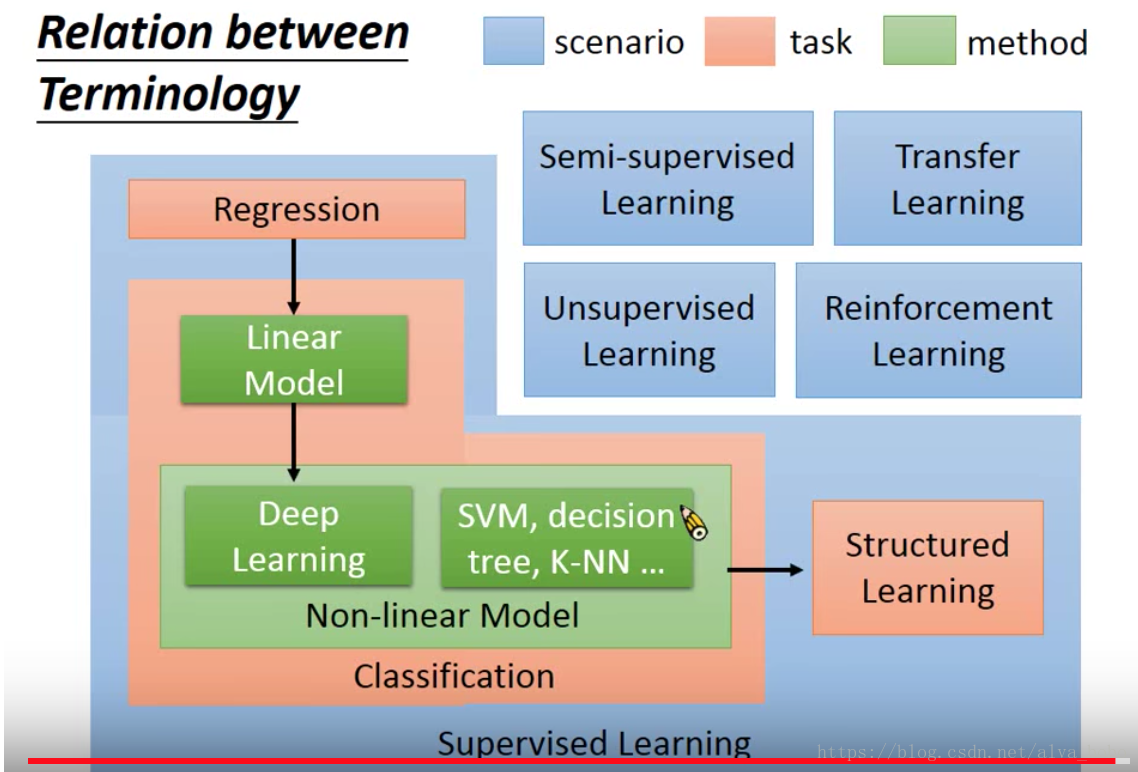
10月10日
-
为什么要使用Regulation

正则项目的:使目标函数尽可能的平滑,尽量使Wi小一点
Wi小的比较好(因为输入值有很大变化,对输出的影响相对没有那么大)
λ越大,函数越平滑
但是λ太大了,就太平滑,不能正确拟合函数了
正则项不考虑b, 因为b对函数的平滑程度没有影响
10月11日
bias VS variance

bias: 样本点平均离中心远近
variance: 样本点有多散
| variance 大 | overfitting | 增加data, 正则化 |
| bias 大 | underfitting | 修正model(增加data没用的) |
10.12
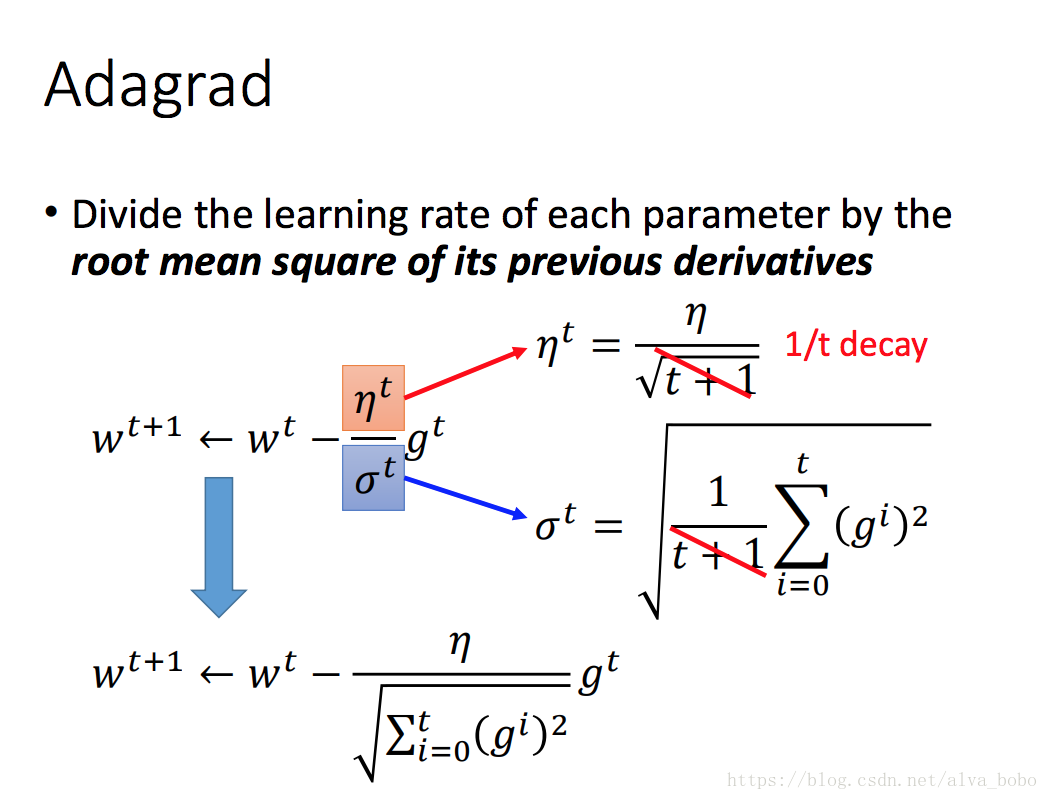
Adagrad: 考虑前面每一步的梯度,全局学习率逐参数的除以历史梯度平方和的平方根,使得每个参数的学习率不同

10 .17
Probabilistic Generative Model
找出一个分布,最有可能选出目前已有的数据

