引言
在结构化学习(一)中,我们讲了结构化学习需要解决三个问题。本文就探讨如何解决这三个问题。
线性模型

我们先来想下,哪个问题最难?
假如 有某种特别的形式,并且我们知道它的形式,那第三个问题就很容易解了。
所以我们先来看下这个特别的形式是怎样的。
问题1
假设我们说这个形式必须是线性的。

给定一个 对,首先我们用一组特征来描述它们。上图中的 分别代表一个特征(标量)。
然后我们说 定义成:

可以整理一下,把它们用两个向量点乘表示:

假如
写成这样,那么问题3就不是一个问题。
这样讲很抽象,我们用一个例子来说明一下。以目标检测为例。

是图像,而 是边框。我们要定义 ,把 代进去要得到一个向量。

那这个向量要怎么定义呢,可以随意定。比如用该向量里的某个维度是红色像素点在框框里面出现的百分比;绿色像素点在框框里面出现的百分比;或者是红色的在框框外的百分比;或者是框框的大小;
其实上面定义的很弱,可能无法正确识别。比较常用的是通过视觉单词(visual word),就是上图中类似正方形的小方块。
这里有人提了个问题,上面我们说的这些特征是需要人工标注呢还是通过模型自己抽取。
这里可以用模型自己抽取的,比如可以训练一个CNN,通过这个CNN输出一个向量,该向量能很好的代表边框里面的东西。

如果我们想做摘要生成。

我们也可以先自己定义一些特征,比如
里面有没有包含"import"这个单词;或者$y$里面有没有包含"definition"这个单词;或者
的长度;
也可以用DNN来抽取特征;
好了,现在第一个问题定义好了,接下来看下第二个问题。
问题2
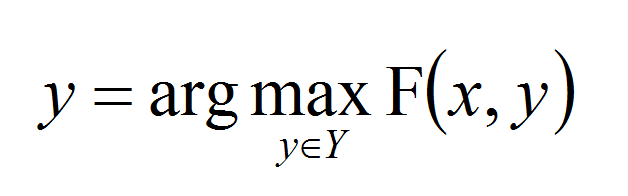
如果解上面这个问题?
我们从问题1的定义可以把 写成
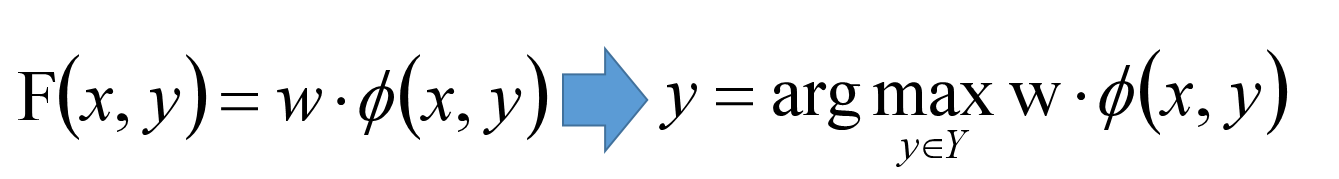
我们一样需要穷举所有的 ,看哪个 能让这个值最大。
这里我们假设已经解决了这个问题。
问题3
现在有很多带标签的训练数据

希望 的 。如上图,对所有的训练数据,我们希望正确的 要大于所有错误的 。
此时所得到的 就是我们想要的。那么要怎么做呢
假设现在要做的是目标检测,我们收集了一张图片 ,我们知道 对应的边框 的大小和位置;同样的 也一样。

假设 和 (正确的边框)所形成的特征是红色的点。这里假设特征只有2维,为了能画到平面上。其他的 和 所形成的特征是蓝色的点。

我们把这些点画出来。红色的点只有一个,而蓝色的点有很多个。

因为这里还有
,我们说
与
形成的是红色的星星,其他是蓝色的星星。注意
看以看成是独立的。

我们接下来要做的事情是,希望找到一个向量 ,然后我们上面的红色样本与蓝色样本点与这个 做内积,希望得到的结果是,红色的星星所得到的内积结果是星星中最大的;红色的点所得到的内积结果是点中最大的。

注意这里我们不能用点与星星比较,因为它们属于不用的图像。
那找 这个问题难解决吗?其实没有想象的那么难。具体怎么做呢
这里有一个算法:

翻译过来就是:
- 首先初始化
do- 每个训练样本
- 找到使得
最大的
- (问题2)
- 如果
,更新
- 找到使得
最大的
- 每个训练样本
unil不再更新
do里面是循环,直到util的条件满足。
如果我们要找的 存在,这个算法最终会停止。
我们用个例子来说明下这个算法吧。还是以上面的目标检测为例。
首先看下这些点代表什么意思
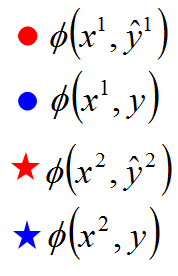
然后初始化

然后随便选取一个训练数据(现在共有2份数据),假设选的是圈圈(点)。这些点的分布是上图这样的。
然后需要根据现在的 去看哪个它所形成的特征 与 做内积后得到的值最大。但是现在因为 ,所以结果都是 ,我们此时先随机选一个 。

假设我们选的是红点下面的那个蓝点(感觉这个算法有个bug,必须限制第一次不能选择红点,否则算法直接结束了)。
此时我们选出的 与 不一样,我们需要调整 。
根据下面这个式子调整:

此时我们找到了一个 ,接下来再选一个训练数据。

此时也一样,需要穷举所有的 ,使得那个式子最大,注意此时 不是 了。

然后我们找到了最大的星星。但是还是和真正的最大的星星不是同一个,因此,继续更新
。
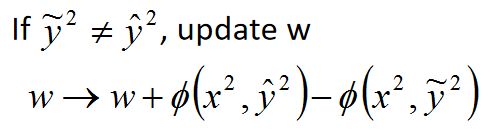
上式中的
项相减得到了一个绿色的向量。

再加上原来的 得到了一个新的 。
接下来我们回到训练数据

发现用这个新的
去计算内积,得到的
就是
,也就不需要更新
了,对这份数据来说。但是还不一定适合数据
。所以还要继续。
继续选 。

假设此时发现选出的
也是
,因此就不需要更新
了。
此时,整个算法结束。找出了想要的 。
