相关专题: 李宏毅2020机器学习资料汇总
文章目录
4. CNN
Convolutional Neural Network(P17)
首先,李宏毅老师介绍了为什么要用CNN来处理图像。
Q:明明 DNN 也可以处理图像,那么为什么要用 CNN 呢?
A:普通的 DNN 用的是全连接层,参数数量特别多。因此,可以根据图像特征,将DNN 简化为CNN,基于以下几个观察(特性):
- 一些模式(pattern)远比整张图像小得多,一个神经元只需要发现这些模式,而不需要看整张图像。如:人脸识别中,一些负责识别眼睛,一些负责识别鼻子,一些负责识别嘴巴等等。将一些小区域与少量参数相关联。
- 同样的模式可能出现在图像的不同区域。如:人脸识别中,鼻子在图上的位置可能不同,可能在正中间,可能偏上,也可能偏下。用同一组的参数做几乎同样的事情。
- 对图片做下采样,不会改变图中的物体。下采样让图像变小,减少参数。
卷积层针对特性1和特性2,最大池化(Max Pooling)层针对特性3。
AlphaGO下围棋也用到了CNN,因为围棋棋盘也满足1和2这两个特性。
李宏毅老师先整体介绍了 CNN 的流程,然后分别介绍卷积操作和最大池化操作。
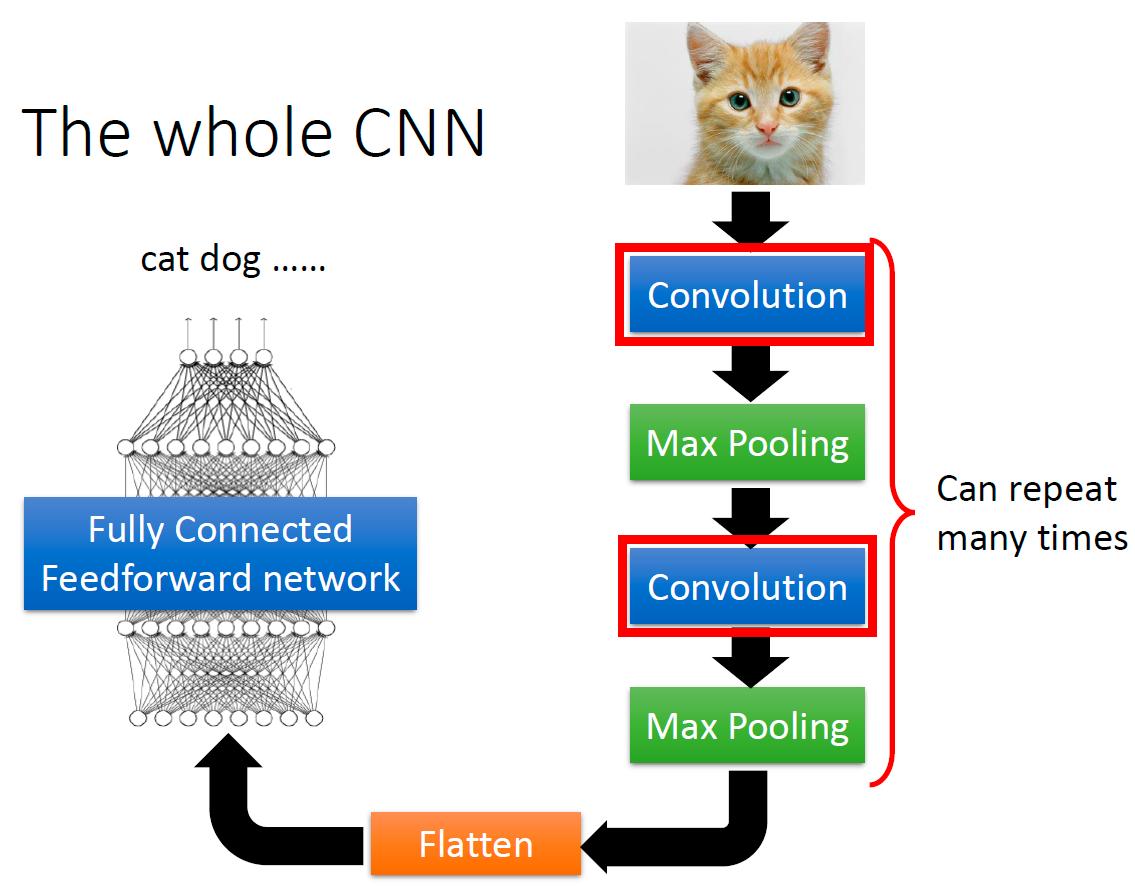
整体的 CNN 如下所示:
一张图像多次经过卷积层+池化层,然后展平,通过一个全连接的前向传播神经网络(分类器)来进行分类。
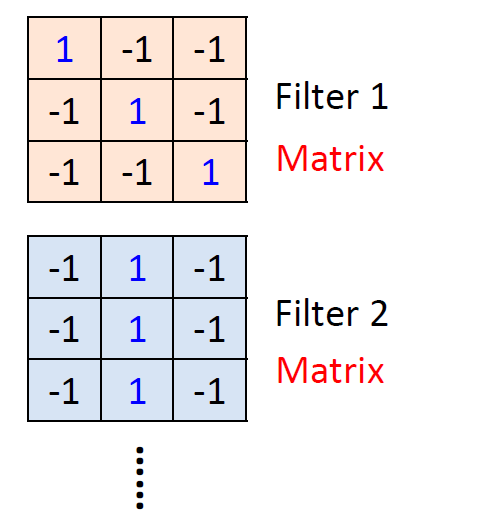
卷积(convolution)操作中有一些过滤器(filter),也被称为卷积核,相当于神经网络中的神经元,需要被学习。
过滤器就是一些矩阵,它负责提取图像中的特征,进行特征映射(feature map)
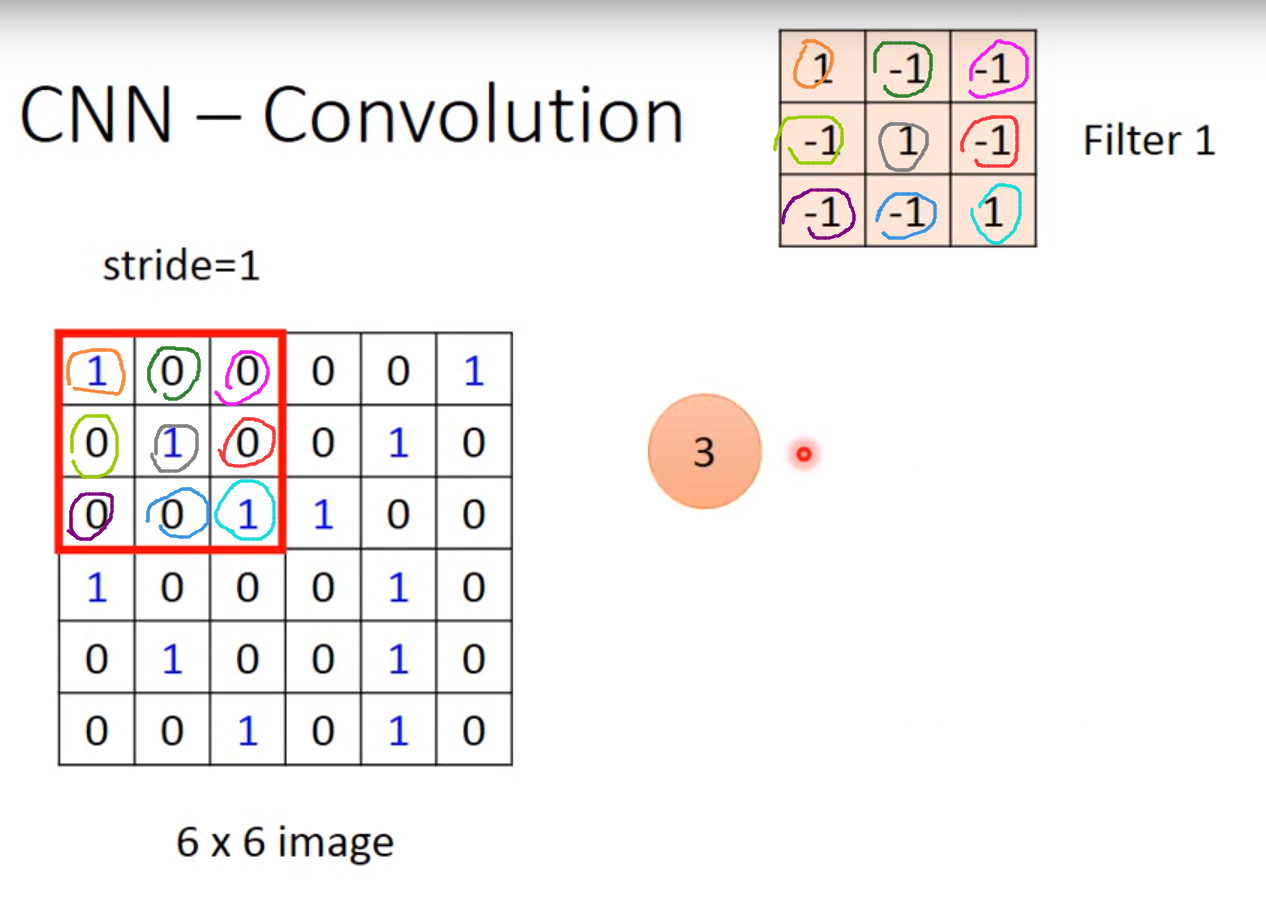
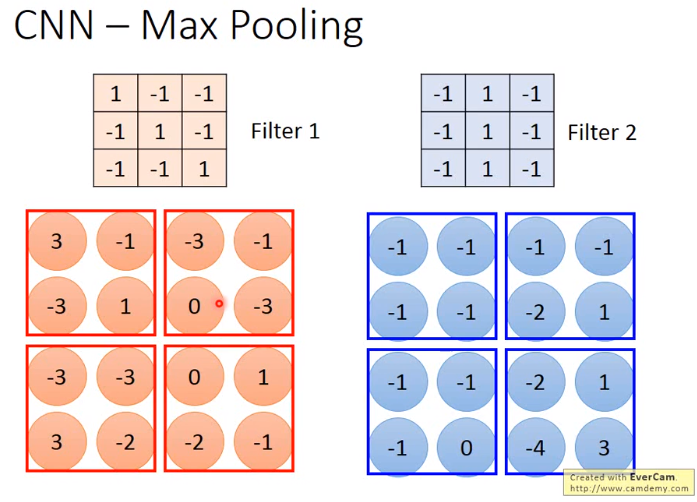
注:卷积操作听起来很复杂,实际上比矩阵乘法简单很多,就是两个大小为 M × N M \times N M×N的矩阵中对应位置的元素相乘,再把乘积累加,建议看视频理解。
下图中 3 = 1 × 1 + 0 × ( − 1 ) + 0 × ( − 1 ) + 0 × ( − 1 ) + 1 × 1 + 0 × ( − 1 ) + 0 × ( − 1 ) + 0 × ( − 1 ) + 1 × 1 3=1\times1+0\times(-1)+0\times(-1)+0\times(-1)+1\times1+0\times(-1)+0\times(-1)+0\times(-1)+1\times1 3=1×1+0×(−1)+0×(−1)+0×(−1)+1×1+0×(−1)+0×(−1)+0×(−1)+1×1
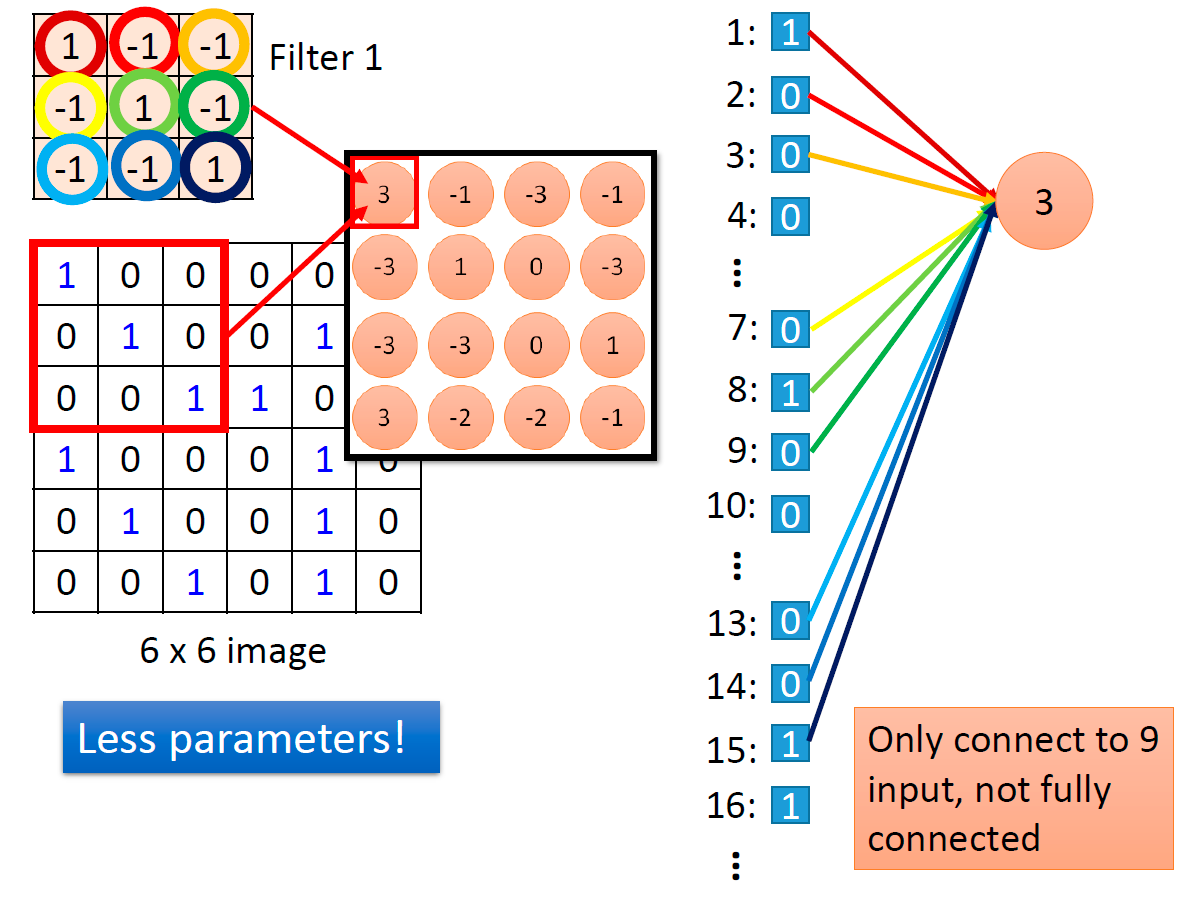
CNN 做卷积相当于 DNN 的全连接层去掉一些权重,比如: 3 × 3 3\times3 3×3 的过滤器相当于它只连接了 9 个输入,而不是全连接。
因此,一个卷积核就是几个神经元的共享参数,使得 CNN 相比 DNN 来说,参数减少了。
最大池化层(Max Pooling)进行下采样。
如:上图划分 2 × 2 2\times2 2×2 的区域进行下采样,选择每个 2 × 2 2\times2 2×2 的区域中最大的值作为这个区域的值。

之后,李宏毅老师介绍了 Keras 中如何搭建CNN(因为这是之前的视频,所以用的是Keras,2020年的作业中用到的是PyTorch)以及输入的图像经过 CNN 的每一层后的大小。
虽然用到的工具不同,但是计算 CNN 中的参数以及图像经过 CNN 的每一层后的大小的方式相同。
例如:
- 输入图像大小为 1 × 28 × 28 1\times28\times28 1×28×28(单通道的灰度图,长为28像素,宽为28像素)。
- 它经过第一个卷积层,卷积层有25个卷积核,每个卷积核大小为 3 × 3 3\times3 3×3,那么输出的图像大小为 25 × 26 × 26 25\times26\times26 25×26×26,每个卷积核有 3 × 3 = 9 3\times3=9 3×3=9 个参数,那么总共有 25 × 3 × 3 = 225 25\times3\times3=225 25×3×3=225个参数。
- 它经过第一个最大池化层,输出的图像大小为 25 × 13 × 13 25\times13\times13 25×13×13.
- 它经过第二个卷积层,卷积层有50个卷积核,每个卷积核大小为 3 × 3 3\times3 3×3,那么输出的图像大小为 50 × 11 × 11 50\times11\times11 50×11×11,每个卷积核有 25 × 3 × 3 = 225 25\times3\times3=225 25×3×3=225 个参数,那么总共有 50 × 25 × 3 × 3 = 11250 50\times25\times3\times3=11250 50×25×3×3=11250个参数。
- 它经过第二个最大池化层,输出的图像大小为 50 × 5 × 5 50\times5\times5 50×5×5.

之后,李宏毅老师介绍了 CNN 每一层可能学到的东西(一些奇怪的模式),最后,介绍了 CNN 的一些应用,如:Deep Dream、Deep Style、AlphaGo、语音识别、文本处理等。
5. GNN
* 2020新增内容,由助教讲授
仍然讲得有点懵逼,就凑合着听听吧。 后来,重新看了一遍,博主感觉比网上大部分讲GNN的视频讲得都好,先留个坑,之后再回来更新吧。
Graph Neural Network (1_2) (选学)(P18)
Graph Neural Network (2_2) (选学)(P19)
6. Semi-supervised
因为下面要侧重讲RNN,这一P和RNN的关系不是很大,但是感觉先学这一部分再看RNN可能更有连贯性,所以就单独提上来先写。
Semi-supervised(P22)
首先,李宏毅老师介绍监督学习(Supervised learning)、半监督学习(Semi-supervised learning)的含义,以及为什么要有半监督学习。
监督学习:
有标签的数据集 { ( x r , y ^ r ) } r = 1 R \{(x^r, \hat{y}^r)\}^R_{r=1} { (xr,y^r)}r=1R
半监督学习:
有标签的数据集 { ( x r , y ^ r ) } r = 1 R \{(x^r, \hat{y}^r)\}^R_{r=1} { (xr,y^r)}r=1R,没有标签的数据集 { ( x u ) } u = R R + U \{(x^u)\}^{R+U}_{u=R} { (xu)}u=RR+U,并且 U > > R U>>R U>>R
半监督学习又分为两种:
- Transductive learning:无标签的数据是测试数据(testing data)
- Inductive learning:无标签的数据不是测试数据(testing data)
Q:为什么要半监督学习?
A:实际生活中,机器学习中要收集数据很容易,但是要收集有标签的数据不容易。
李宏毅老师介绍了在生成模型中,如何做半监督学习(semi-supervised learning for genrative model)。
有监督的生成模型在 P11 中已经讲过,给定有标签的训练样本 x r ∈ C 1 , C 2 x^r \in C_1,C_2 xr∈C1,C2
- 寻找最大先验概率 P ( C i ) P(C_i) P(Ci) 和类依赖概率 P ( x ∣ C i ) P(x\mid C_i) P(x∣Ci)
- P ( x ∣ C i ) P(x\mid C_i) P(x∣Ci)是高斯分布,由均值 μ i \mu^i μi 和方差 Σ \Sigma Σ 决定
有了 P ( C 1 ) , P ( C 2 ) , μ 1 , μ 2 , Σ P(C_1),P(C_2),\mu^1,\mu^2,\Sigma P(C1),P(C2),μ1,μ2,Σ 之后,就可以计算 P ( C 1 ∣ x ) = P ( x ∣ C 1 ) P ( C 1 ) P ( x ∣ C 1 ) P ( C 1 ) + P ( x ∣ C 2 ) P ( C 2 ) P(C_1\mid x)=\frac{P(x\mid C_1)P(C_1)}{P(x|C_1)P(C_1)+P(x|C_2)P(C_2)} P(C1∣x)=P(x∣C1)P(C1)+P(x∣C2)P(C2)P(x∣C1)P(C1)
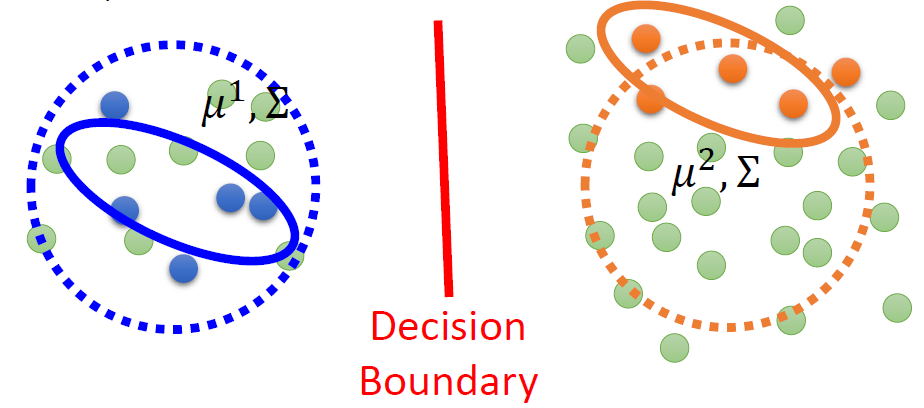
而在半监督学习中,生成模型会存在问题。如下图所示,假设下图绿色的是无标签的数据。实线是根据有标签的数据计算得到的高斯分布,而实际上,如果那些无标签的数据都有标签,那么高斯分布可能如虚线所示。
换言之,无标签数据 x u x^u xu 会影响 P ( C 1 ) , P ( C 2 ) , μ 1 , μ 2 , Σ P(C_1),P(C_2),\mu^1,\mu^2,\Sigma P(C1),P(C2),μ1,μ2,Σ,甚至还会影响 Decision Boundary.

半监督的生成模型算法(EM算法):
初始化参数 θ = P ( C 1 ) , P ( C 2 ) , μ 1 , μ 2 , Σ \theta = {P(C_1),P(C_2),\mu^1,\mu^2,\Sigma} θ=P(C1),P(C2),μ1,μ2,Σ
Step 1(Expectation-step)根据模型 θ \theta θ 计算无标签数据的后验概率 P θ ( C 1 ∣ x u ) P_\theta(C_1\mid x^u) Pθ(C1∣xu)
Step 2(Maximum-step) 更新模型:
P ( C 1 ) = N 1 + ∑ x u P ( C 1 ∣ x u ) N P\left(C_{1}\right)=\frac{N_{1}+\sum_{x^{u}} P\left(C_{1} \mid x^{u}\right)}{N} P(C1)=NN1+∑xuP(C1∣xu)μ 1 = 1 N 1 ∑ x r ∈ C 1 x r + 1 ∑ x u P ( C 1 ∣ x u ) ∑ x u P ( C 1 ∣ x u ) x u \mu^{1}=\frac{1}{N_{1}} \sum_{x^{r} \in C_{1}} x^{r}+\frac{1}{\sum_{x^{u}} P\left(C_{1} \mid x^{u}\right)} \sum_{x^{u}} P\left(C_{1} \mid x^{u}\right) x^{u} μ1=N11xr∈C1∑xr+∑xuP(C1∣xu)1xu∑P(C1∣xu)xu
其中, N N N 是总样本数, N 1 N_1 N1 是属于类别 C 1 C_1 C1 的样本数。回到Step1
注:算法最终会收敛,但是初始化的参数会影响结果。
Q:为什么EM算法可行?其背后的理论支撑是什么?
A:
1.用标签数据来最大化似然 —— 解析解
log L ( θ ) = ∑ x r log P θ ( x r , y ^ r ) \log L(\theta)=\sum_{x^{r}} \log \textcolor{red}{P_{\theta}\left(x^{r}, \hat{y}^{r}\right)} logL(θ)=xr∑logPθ(xr,y^r)P θ ( x r , y ^ r ) = P θ ( x r ∣ y ^ r ) P ( y ^ r ) \textcolor{red}{P_{\theta}\left(x^{r}, \hat{y}^{r}\right) }=P_{\theta}\left(x^{r} \mid \hat{y}^{r}\right) P\left(\hat{y}^{r}\right) Pθ(xr,y^r)=Pθ(xr∣y^r)P(y^r)
2. 同时用标签数据和无标签数据来最大化似然 —— 迭代解决
log L ( θ ) = ∑ x r log P θ ( x r ) + ∑ x u log P θ ( x u ) \log L(\theta)=\sum_{x^{r}} \log P_{\theta}\left(x^{r}\right)+\sum_{x^{u}} \log \textcolor{blue}{P_{\theta}\left(x^{u}\right)} logL(θ)=xr∑logPθ(xr)+xu∑logPθ(xu)P θ ( x u ) = P θ ( x u ∣ C 1 ) P ( C 1 ) + P θ ( x u ∣ C 2 ) P ( C 2 ) \textcolor{blue}{P_{\theta}\left(x^{u}\right)}=P_{\theta}\left(x^{u} \mid C_{1}\right) P\left(C_{1}\right)+P_{\theta}\left(x^{u} \mid C_{2}\right) P\left(C_{2}\right) Pθ(xu)=Pθ(xu∣C1)P(C1)+Pθ(xu∣C2)P(C2)
x u x^u xu可以来自类别 C 1 C_1 C1 或 C 2 C_2 C2
接下来,李宏毅老师介绍了 Low-density Separation.
Low-density Separation 是一个“非黑即白”的世界,即两个类别之间有非常明显的分界线。
Low-density Separation 中最简单的方法是 self-training
给定:有标签的数据集 { ( x r , y ^ r ) } r = 1 R \{(x^r, \hat{y}^r)\}^R_{r=1} { (xr,y^r)}r=1R,没有标签的数据集 { ( x u ) } u = R R + U \{(x^u)\}^{R+U}_{u=R} { (xu)}u=RR+U
重复:
- 从有标签的数据中训练一个模型 f ∗ f^* f∗
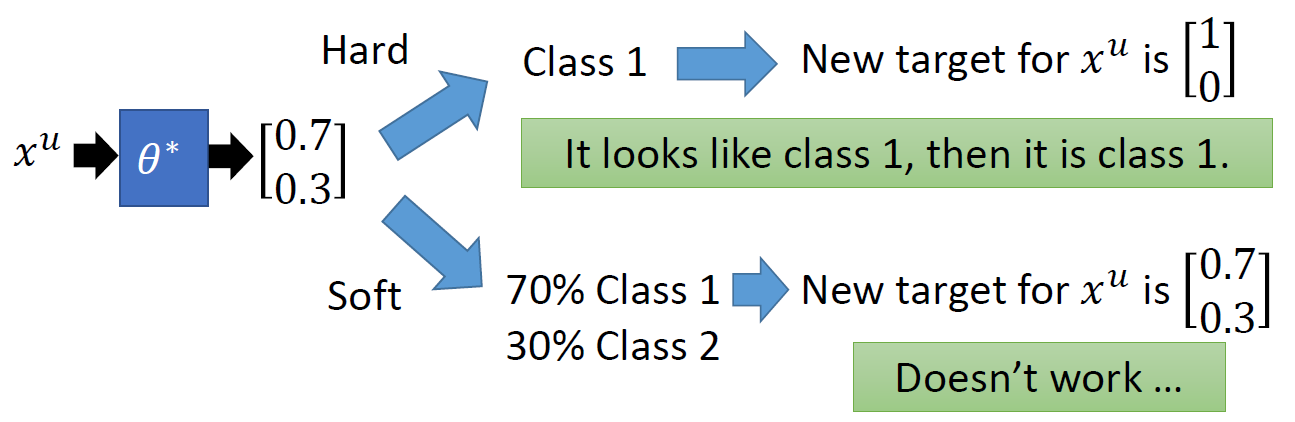
- 把 f ∗ f^* f∗应用于无标签数据集,获得 { ( x u , y u ) } u = R R + U \{(x^u,y^u)\}^{R+U}_{u=R} { (xu,yu)}u=RR+U,这里的 y u y^u yu 是一个伪标签
- 从无标签数据集中取出一些数据,把它们加入标签数据集中。(注:选择拿出哪些无标签数据可以自己设定,也可以给每个数据赋予不同的权重)
Q:这个方法用在回归问题上有用吗?
A:没有用。因为回归是预测数值,所以设置一个伪标签 y u y^u yu 并不会影响 f ∗ f^* f∗。
self-training 和半监督学习的生成模型很类似。差别在于:
- self-training 是硬标签(Hard label),即类别一定是0或者1.(非黑即白)
- 半监督学习的生成模型 是软标签(Soft label),即类别可以是0-1之间的小数,比如:0.3, 0.7等
注:在神经网络中,用软标签是没有用的,类似于刚才说到的回归,软标签不会改变数据的分布,也就不会改变模型。
基于熵的正则化:
x u → θ ∗ → y u x^u \rightarrow \theta^* \rightarrow y^u xu→θ∗→yu
用 y u y^u yu 的熵 E ( y u ) = − ∑ m y m u ln ( y m u ) E(y^u)=- \sum \limits_{m}y_m^u\ln(y^u_m) E(yu)=−m∑ymuln(ymu) 可以评估分布 y u y^u yu 的集中程度。我们希望 E ( y u ) E(y^u) E(yu) 越小越好。因此,损失函数为: L = ∑ x r C ( y r , y ^ r ) + λ ∑ x u E ( y u ) L =\textcolor{blue}{\sum_{x^{r}} C\left(y^{r}, \hat{y}^{r}\right) }+\lambda \textcolor{orange}{ \sum_{x^{u}} E\left(y^{u}\right)} L=xr∑C(yr,y^r)+λxu∑E(yu)
蓝色部分是有标签的数据,橙色部分是无标签的数据。
Low-density Separation 中还有一个很有名的方法,就是半监督的支持向量机模型(Semi-supervised SVM),李宏毅老师在此进行了一个略讲。
半监督学习的下一个议题是平滑假设(Smoothness Assumption)
Smoothness Assumption 的精神是“近朱者赤,近墨者黑”,即假设相似的 x 有相同的标签 y ^ \hat{y} y^。更精确的定义是:
- x x x 的分布是不均匀的
- 如果 x 1 x^1 x1 和 x 2 x^2 x2 在一个高密度区域很接近,那么 y ^ 1 \hat{y}^1 y^1 和 y ^ 2 \hat{y}^2 y^2 是相同的。
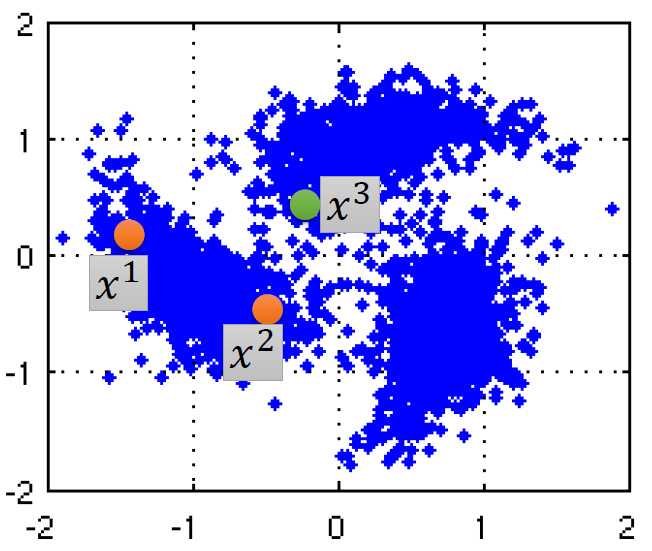
例子如下:
x 1 x^1 x1 和 x 2 x^2 x2 通过一个高密度的路径相连,所以它们有相同的标签;
x 2 x^2 x2 和 x 3 x^3 x3 不能通过一个高密度的路径相连,所以它们的标签不同。
Q:如何基于平滑假设让机器进行半监督学习?
A:有两种方法:
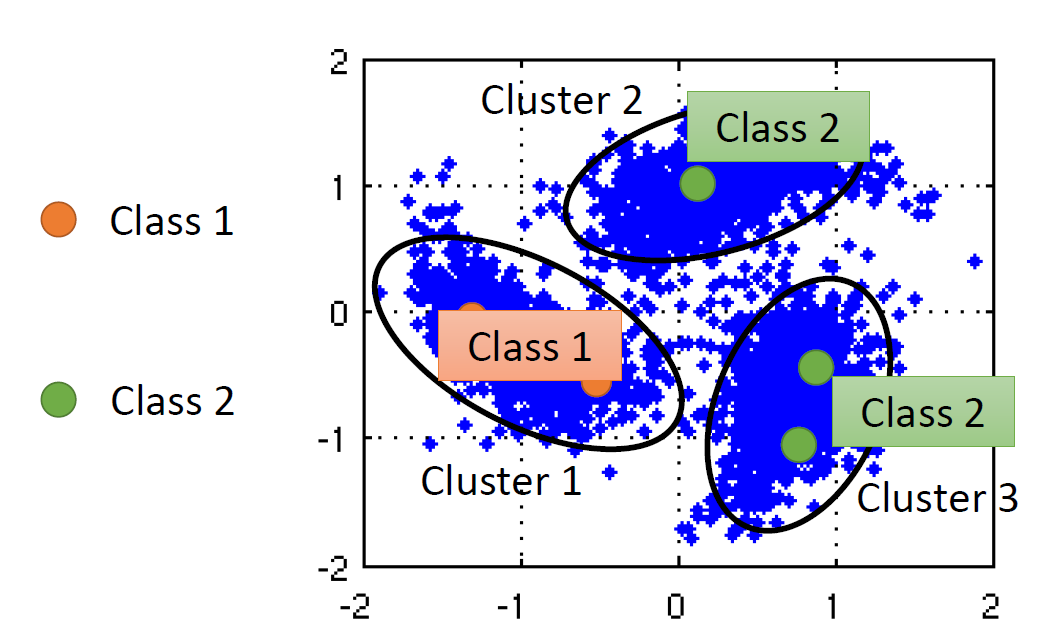
聚类,加标签
注:在图像处理中,如果直接用图像聚类,效果往往不好,常见做法是用深度自动编码器抽取出图像的特征再做聚类。基于图(graph)的方法
构造图:把所有数据点都当作图上的一点,在图上,如果两点相连,它们就是一类。
比如:网页超链接,论文的引用。
Q:在基于图(graph)的方法中,如何构造图?
A:1. 定义 x i x^i xi 和 x j x^j xj 之间的相似度度量 s ( x i , x j ) s(x^i, x^j) s(xi,xj)
- 添加边,两种方法:
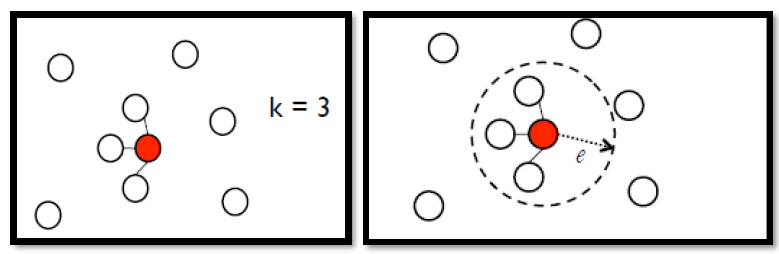
- K Nearest Neighbor(K近邻),如下左图,每个点指定与它最像的K个点相连
- e-Neighborhood,如下右图,每个点指定与它相似度大于e的点相连
- 给边赋予权重,与 s ( x i , x j ) s(x^i, x^j) s(xi,xj) 成正比
s ( x i , x j ) s(x^i, x^j) s(xi,xj) 可以用高斯径向基函数(Gaussian Radial Basis Function,GRBF)定义:
s ( x i , x j ) = exp ( − γ ∥ x i − x j ∥ 2 ) s\left(x^{i}, x^{j}\right)=\exp \left(-\gamma\left\|x^{i}-x^{j}\right\|^{2}\right) s(xi,xj)=exp(−γ∥∥xi−xj∥∥2)
Q:如何使用基于图(graph)的方法让机器进行半监督学习?
A:
- 定性来说:
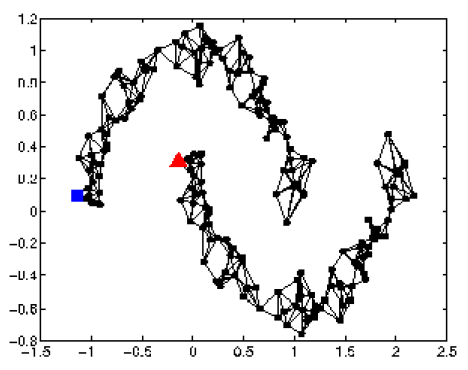
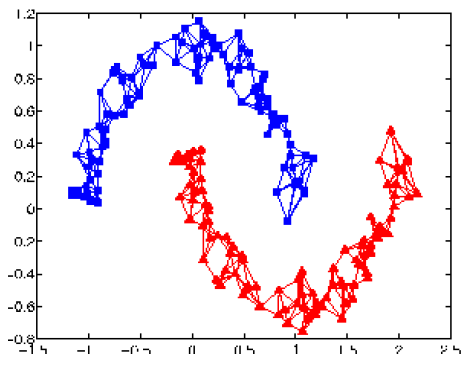
在基于图的方法中,有标签的数据会影响它们的邻居节点,标签会随着图而传播。
例如:最开始只有一个蓝点和一个红点,传播后,一个连通分支被染成了蓝色,一个连通分支被染成了红色。
- 定量来说:
定义图上的标签的平滑程度:
S = 1 2 ∑ i , j w i , j ( y i − y j ) 2 = y T L y S=\frac{1}{2} \sum_{i, j} w_{i, j}\left(y^{i}-y^{j}\right)^{2}=\mathtt{y}^TL\mathtt{y} S=21i,j∑wi,j(yi−yj)2=yTLy
S S S 作用于所有的数据(不论有无标签),越小表示越平滑。
y = [ … y i … y j … ] T \mathtt{y}=[\ldots y^i \ldots y^j\ldots]^T y=[…yi…yj…]T 是 ( R + U ) (R+U) (R+U) 维的向量
L = D − W L=D-W L=D−W 是图的拉普拉斯算子(Graph Laplacian),是 ( R + U ) × ( R + U ) (R+U)\times(R+U) (R+U)×(R+U) 的矩阵
W W W 是权重矩阵, D D D 是度矩阵。上图(忽略标签)的 W W W 和 D D D 如下:
最终的损失函数如下:
L λ = ∑ x r C ( y r , y ^ r ) + λ S L_\lambda=\sum_{x^{r}} C\left(y^{r}, \hat{y}^{r}\right)+\textcolor{red}{\lambda S} Lλ=xr∑C(yr,y^r)+λS
相当于在原来的损失函数上加入一个正则化项 λ S \textcolor{red}{\lambda S} λS
注:平滑操作不一定要作用于神经网络的输出项,可以作用于神经网络的任意一层。
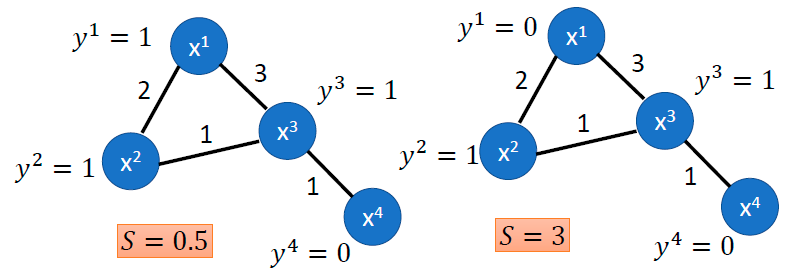
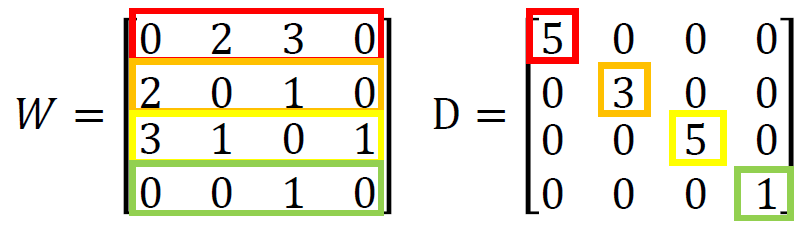
最后,李宏毅老师介绍了 Better Representation,具体会放在无监督学习(P23)中讲。
Better Representation的核心精神是:去芜存菁,化繁为简。即通过观察(observation)得到更好的表征——隐含因素(latent factor)
7. RNN
RNN 这几章的顺序有点混乱,这里按个人学习的顺序进行整理。
Recurrent Neural Network (Part I)(P20)
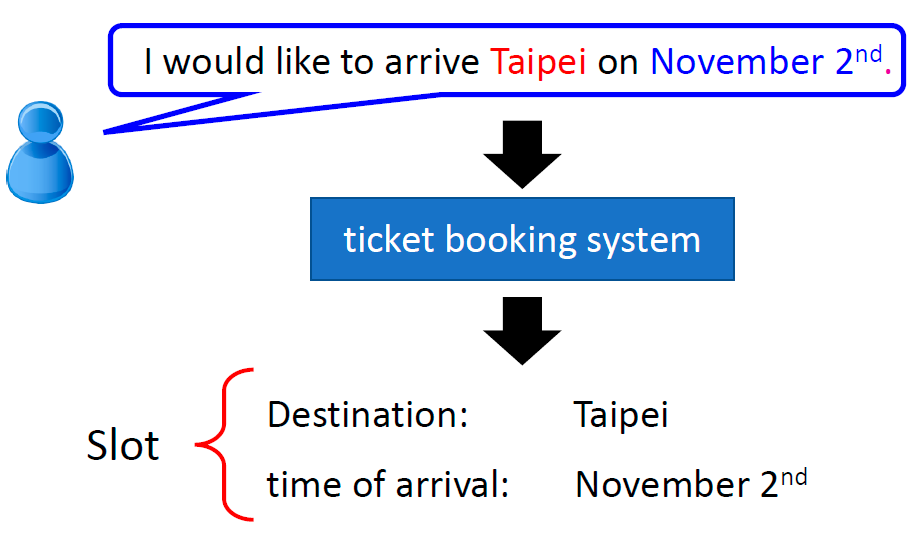
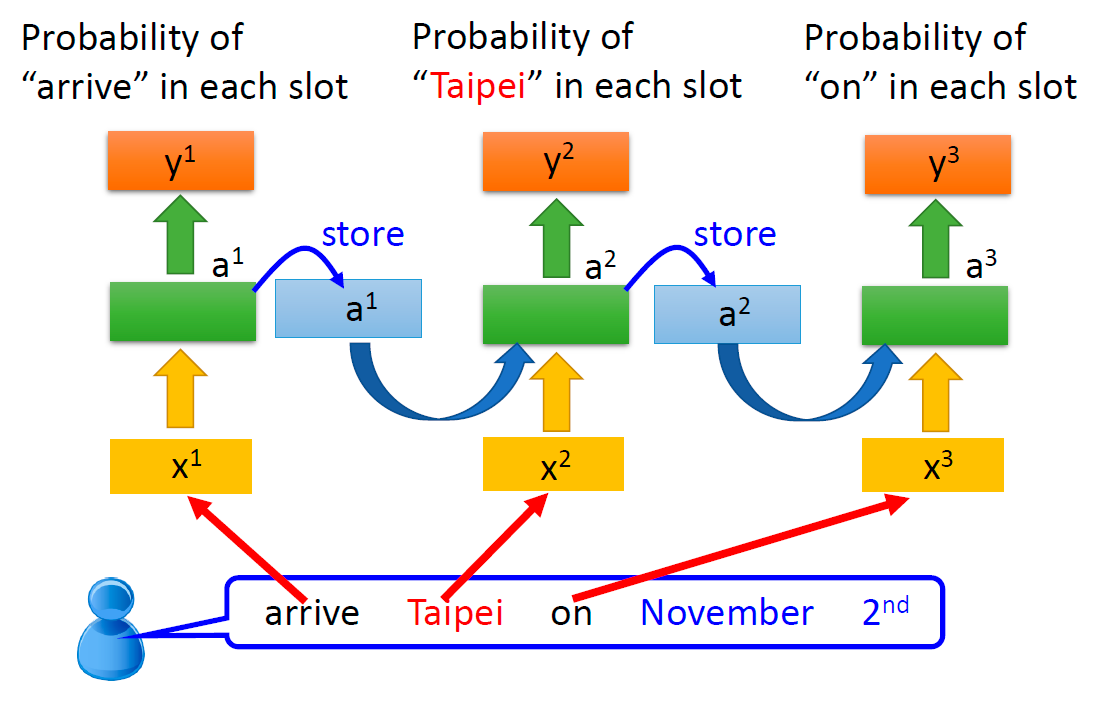
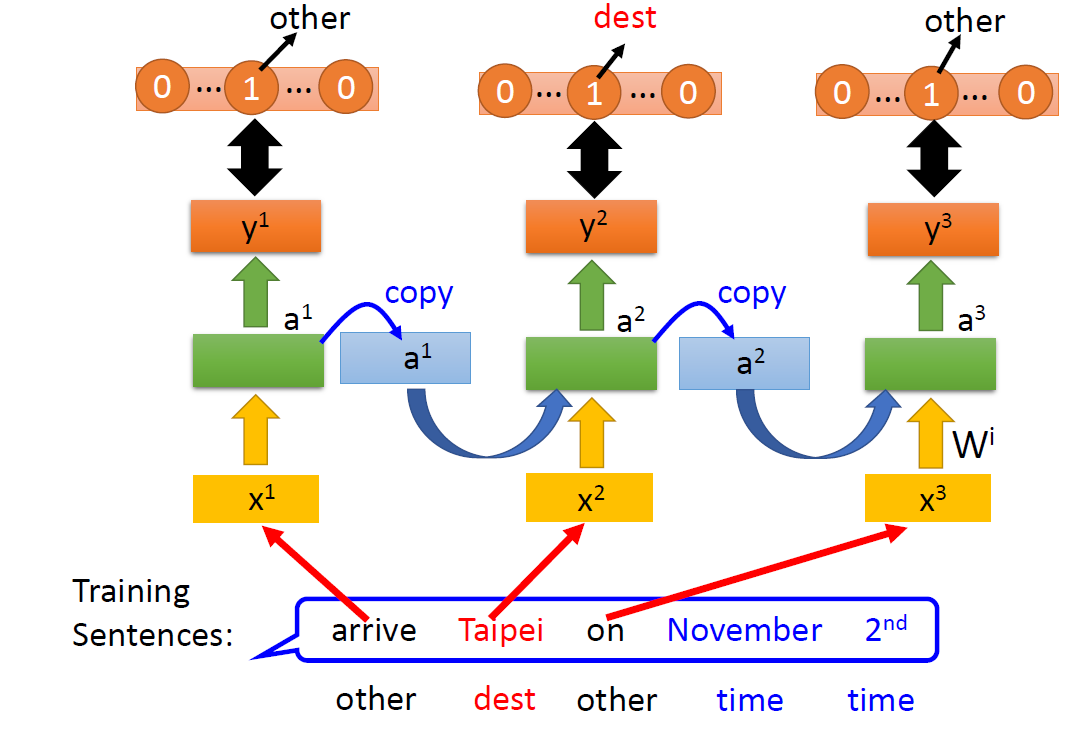
首先,介绍一个自然语言处理任务中常见的应用问题:Slot Filling(填槽)
Slot Filling:
用户说出一句话,提取出其中的重点,把它填入对应的槽中,比如“目的地”填“台北”,“抵达时间”填“11月2日”
当然,可以用前向传播神经网络来解决这个问题。
首先,要用一个向量来表示一个词,这可以叫做词的向量化、词的编码或者词嵌入。这里用到的是最简单的独热编码(one-hot encoding,又叫 1-of-N encoding): 它是一个长度为 N N N 的向量,只有 1 1 1 个数字是1,其它的 N − 1 N-1 N−1 个数字都是0。one-hot 编码使得每个单词在它们各自的维度上,与其它单词是独立的。
通常,这个 N N N 是词汇表的大小。对于出现在词汇表之外的词,还可以额外引入一个“other”维度。
注:其它一些词嵌入的方法见 P22.
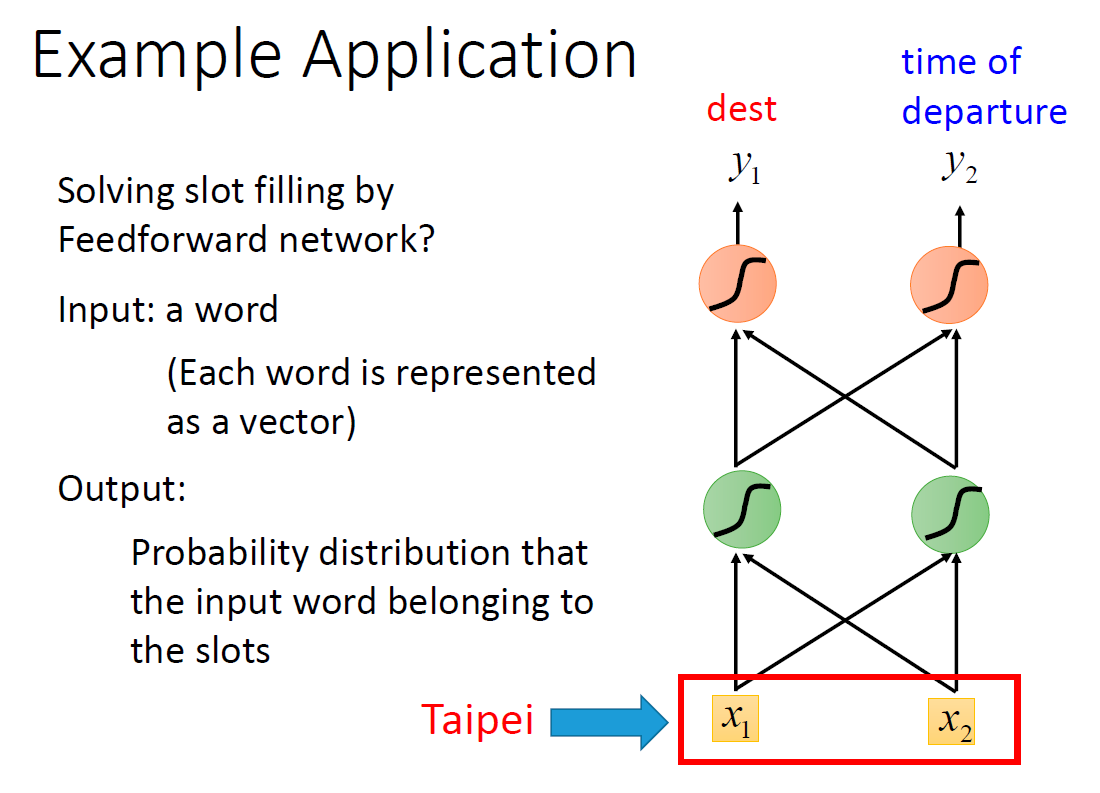
用前向传播神经网络解决 Slot Filling 问题
输入:一个单词(更准确的说,是它的向量)
输出:这个单词属于某个槽的概率分布
如:输入 “Taipei”,输出它属于 y 1 y_1 y1= dest 的概率,属于 y 2 y_2 y2 = time of departure 的概率
李宏毅老师由前向传播神经网络的不足引出 RNN,并举例解释了其运作过程
前向传播神经网络存在的问题:
如果输入的不是“arrive Taipei on November 2nd”,而是“leave Taipei on November 2nd”,那么 “Taipei” 在第一句中是目的地,在第二句中是离开地。
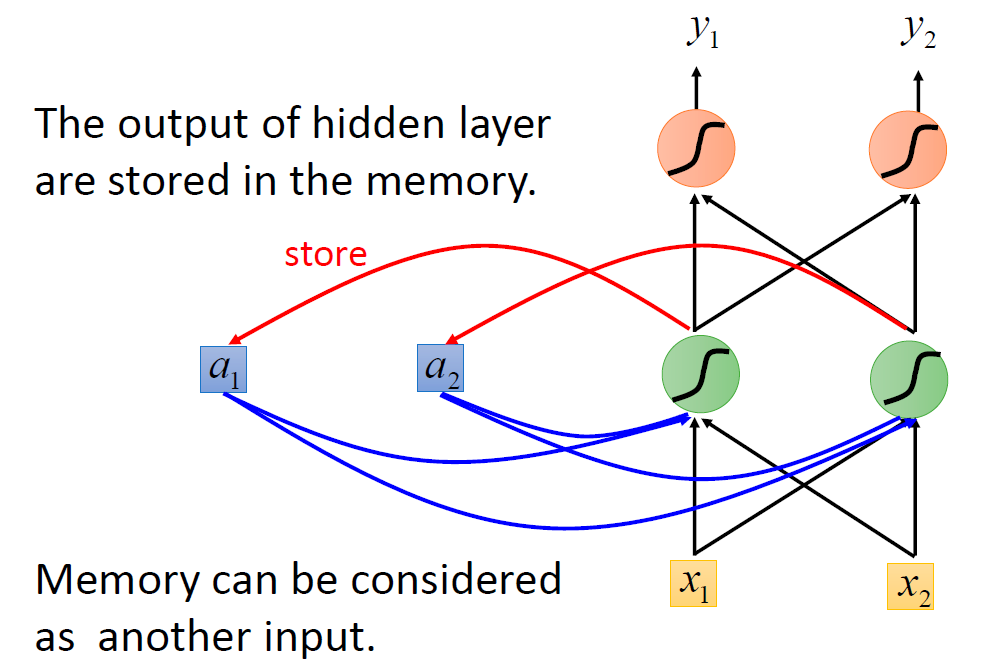
因此,前向传播神经网络需要有一个存储功能,记忆出现在 “Taipei” 之前的词是 “arrive” 还是 “leave”,RNN 由此诞生。
在前向传播神经网络中加入存储单元 (图中的 a 1 a_1 a1、 a 2 a_2 a2),每一步执行后,会将隐藏层的输出存储在 a 1 a_1 a1、 a 2 a_2 a2中。当输入下一个单词时,会从 a 1 a_1 a1、 a 2 a_2 a2 中读取数据,作为输入之一。
这样子的同一个网络会反复使用,把循环图按照时序展开后如下图所示:
而存储单元中的值会不断更新,从 a 1 a^1 a1 变成 a 2 a^2 a2 ,从 a 2 a^2 a2 变成 a 3 a^3 a3 ……由于存储单元的存在,因此,RNN 的输出与前向传播神经网络的输出不相同。
注:更详细的可看 【Pytorch官方教程】从零开始自己搭建RNN1 - 字母级RNN的分类任务
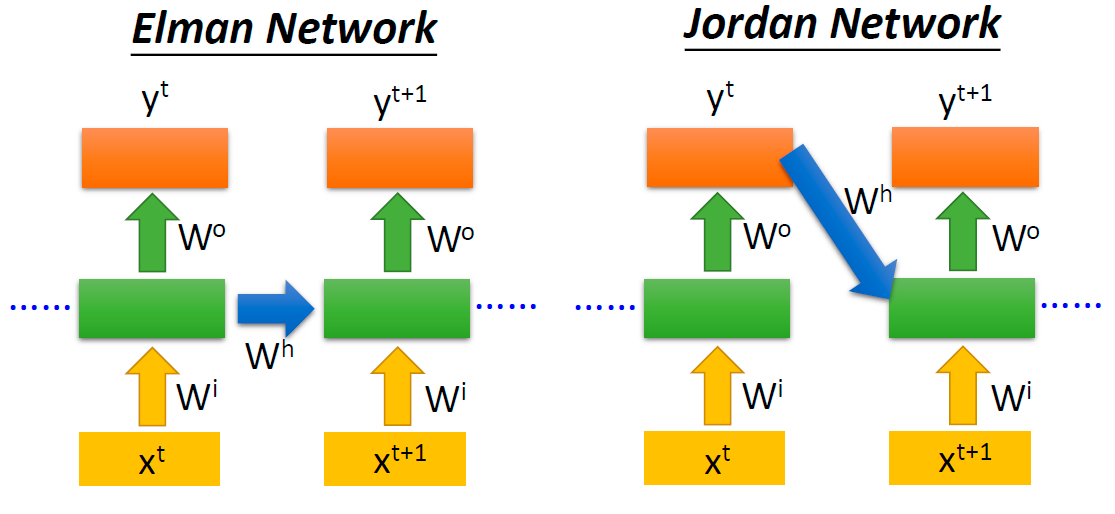
关于这里的循环结构,有两种循环方式:
- Elman Network:存储单元中存储的是上一时间步中最后一层隐藏层的状态
- Jordan Network:存储单元中存储的是上一时间步中输出层的状态
差异如下图所示:

RNN 可能存在一些变体,比如:更深的RNN、双向RNN、LSTM、GRU等。
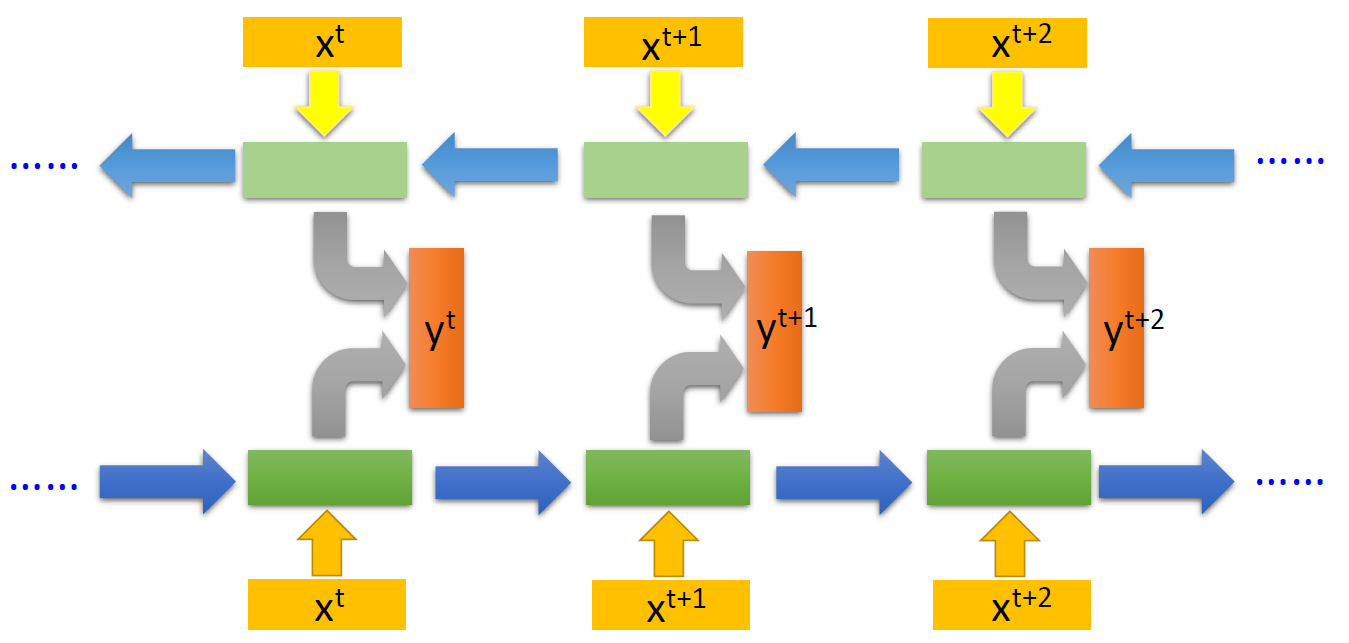
更深的RNN:每一个时间步的 RNN 可以很深,有多个存储单元。

双向RNN:两个RNN把句子正向、反向处理后,把同一个词对应的输出直接拼接在一起,得到双向RNN的输出。
因为LSTM很重要,所以李宏毅老师接下来重点讲了LSTM.
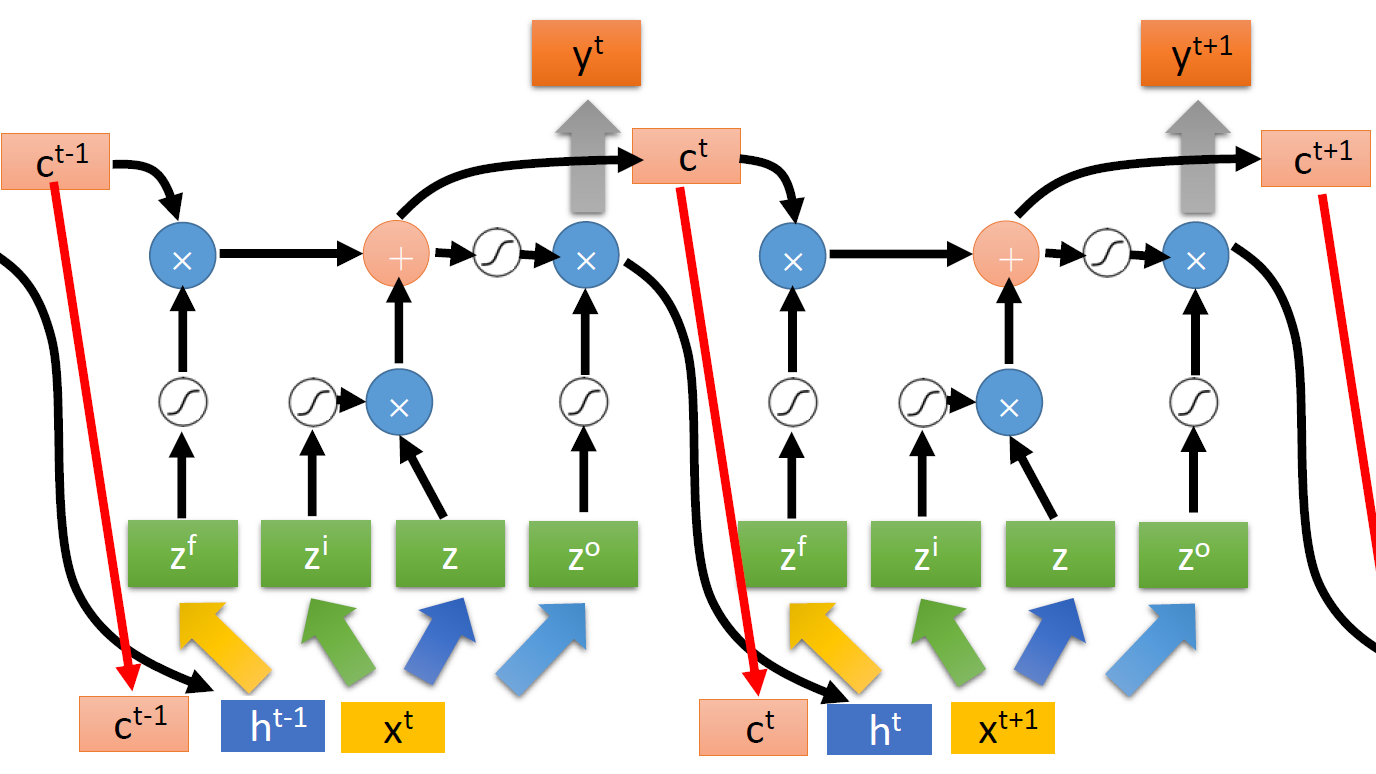
LSTM 是RNN的一个变体,现在提到RNN,一般都是指 LSTM。
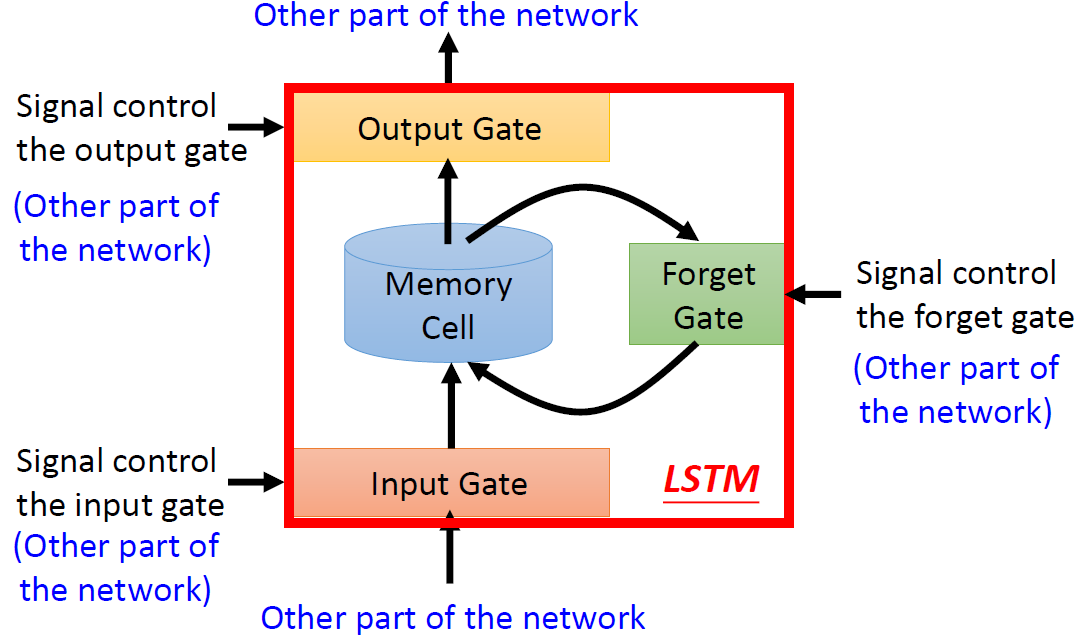
LSTM 的整体框架如下:
- 输入门:输入要被写入到 Memory Cell 中,但是它先要通过一个输入门(Input Gate)。输入门有一个控制信号(这个控制信号来源于网络的其它部分)来控制这个门,只有当这个门被打开的时候,这个输入值才能被写到记忆存储元中。
- 输出门:Memory Cell 中的值要被输出,但是只有当输出门(Output Gate)被打开时,Memory Cell 中的值才能被输出。
- 遗忘门:Memory Cell 中的值可能会被格式化(format),当遗忘门(Forget Gate)被打开时,Memory Cell 中的值可能被清空。
Q:这些门什么时候被打开,什么时候被关闭?
A:模型自己学习。
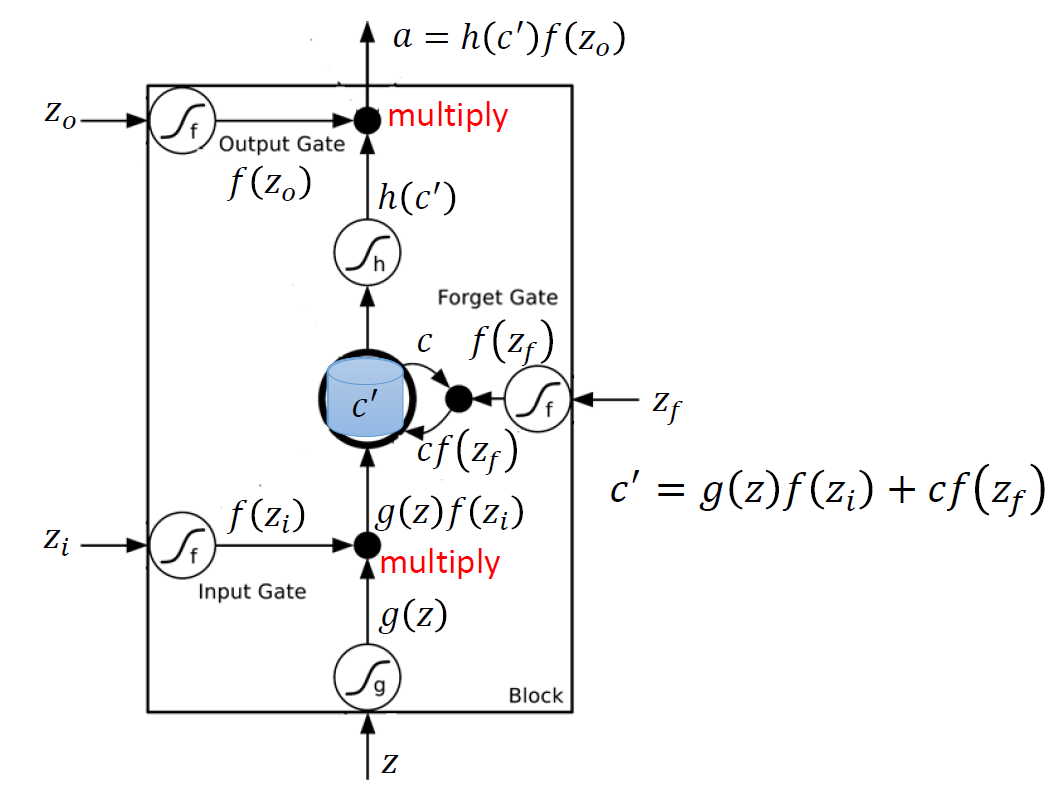
LSTM 引入了1个记忆存储元(c),有3个门(Input Gate、Forget Gate、Output Gate),4个输入(下图的 z f z_f zf、 z i z_i zi、 z o z_o zo、 z z z),1个输出( a a a)。
流程如下:
- z z z 通过变换后变成 g ( z ) g(z) g(z)
- z i z_i zi通过输入门(Input Gate)后变成 f ( z i ) f(z_i) f(zi)
- g ( z ) g(z) g(z) 与 f ( z i ) f(z_i) f(zi) 相乘变成 g ( z ) f ( z i ) g(z)f(z_i) g(z)f(zi)
- z f z_f zf通过遗忘门(Forget Gate)后变成 f ( z f ) f(z_f) f(zf),与memory cell中原有的值 c c c相乘,变成 c f ( z f ) cf(z_f) cf(zf)
- c f ( z f ) cf(z_f) cf(zf) 和 g ( z ) f ( z i ) g(z)f(z_i) g(z)f(zi) 作用后,将memory cell中的值 c c c 更新为 c ′ c' c′,通过变换后得到 h ( c ′ ) h(c') h(c′)
- z o z_o zo通过输出门(Output Gate)后变成 f ( z o ) f(z_o) f(zo)
- f ( z o ) f(z_o) f(zo) 与 h ( c ′ ) h(c') h(c′)相乘得到输出 a = h ( c ′ ) f ( z o ) a=h(c')f(z_o) a=h(c′)f(zo)
说明:
一般是 σ ( ⋅ ) \sigma(·) σ(⋅)的S型曲线,即sigmoid函数,输出在0-1之间,表示门被打开的程度。
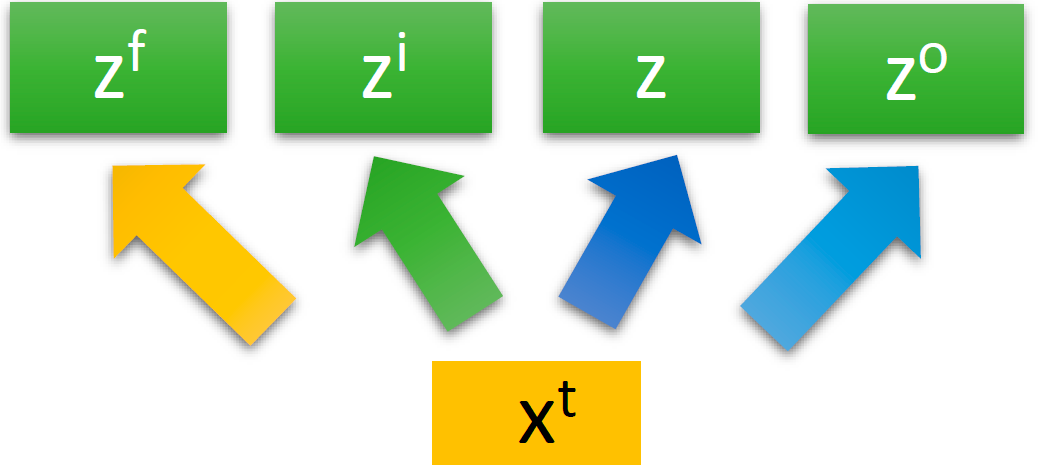
为了便于理解,李宏毅老师又列举了一个例子。接着,他又详细解释了 x t x^t xt 与 z f z_f zf、 z i z_i zi、 z o z_o zo、 z z z之间的关系。
对同一个输入 x t x_t xt,乘上不同的权重 W f W_f Wf、 W i W_i Wi、 W W W、 W o W_o Wo就变成了四个不同的值:
- z f = W f x t z^f=W_fx^t zf=Wfxt,是遗忘门(Forget Gate)的输入,通过遗忘门后变成 f ( z f ) = σ ( z f ) = σ ( W f x t ) f(z^f)=\sigma(z^f)=\sigma(W_fx^t) f(zf)=σ(zf)=σ(Wfxt)
- z i = W i x t z^i=W_ix^t zi=Wixt,是输入门(Input Gate)的输入,通过输入门后变成 f ( z i ) = σ ( z i ) = σ ( W i x t ) f(z^i)=\sigma(z^i)=\sigma(W_ix^t) f(zi)=σ(zi)=σ(Wixt)
- z = W x t z=Wx^t z=Wxt,是真正的输入(和输入门的输入是不一样的),通过变换后变成 g ( z ) g(z) g(z)
- z o = W o x t z^o=W_ox^t zo=Woxt,是输出门(Output Gate)的输入,通过输出门后变成 f ( z o ) = σ ( z o ) = σ ( W o x t ) f(z^o)=\sigma(z^o)=\sigma(W_ox^t) f(zo)=σ(zo)=σ(Woxt)
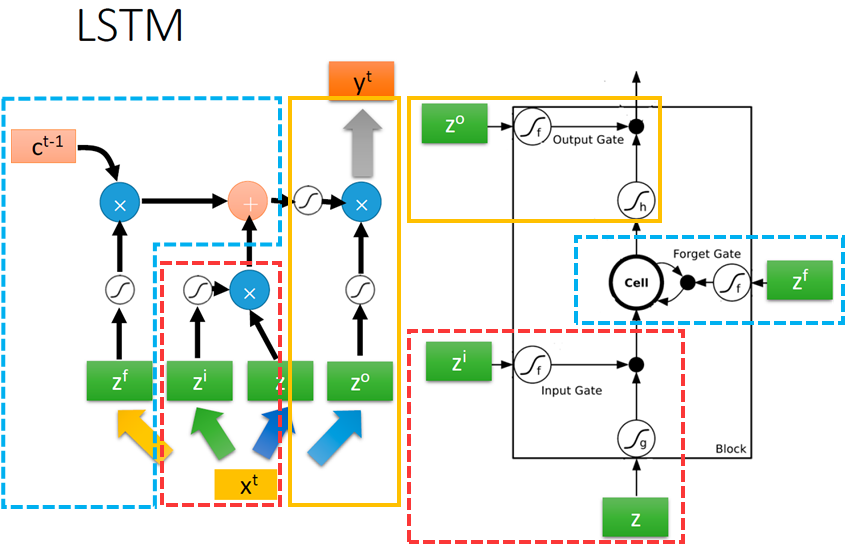
其它几个部分的对应如下图所示:
红色方框圈出来的部分,是输入和输入门的更新,它负责判断是否要接受新的输入:
- z i z^i zi乘以权重 W i W_i Wi,加上偏置向量 b i b_i bi,经过输入门,变成了 i t = σ ( W i z i + b i ) i_t = \sigma(W_iz^i+b_i) it=σ(Wizi+bi)
- z z z乘以权重 W c W_c Wc,加上偏置向量 b c b_c bc,经过 tanh ( ⋅ ) \tanh(·) tanh(⋅),变成了 c ~ t = σ ( W c z + b c ) \tilde{c}_t=\sigma(W_cz+b_c) c~t=σ(Wcz+bc)。这里的 c c c是上面的cell的简写,它是一个存储单元
- 把 i t i_t it 和 c ~ t \tilde{c}_t c~t 按元素相乘(Hadamard乘积,运算符为 ⊙ \odot ⊙或 ∗ * ∗),得到 i t ∗ c ~ t i_t*\tilde{c}_t it∗c~t,然后输入cell
蓝色圈出来的部分,是遗忘门的更新,它负责判断是否要更新cell中的值,如果更新了,就要忘记之前的值,写入新的值:
- cell中存放了上一步的存储向量 c t − 1 c_{t-1} ct−1
- z f z^f zf乘以权重 W f W_f Wf,加上偏置向量 b f b_f bf,经过遗忘门,变成了 f t = σ ( W f z f + b f ) f_t=\sigma(W_fz^f+b_f) ft=σ(Wfzf+bf)
- 在cell中,把 c t − 1 c_{t-1} ct−1 和 f t f_t ft同样按元素相乘,然后和刚才提到的 i t ∗ c ~ t i_t*\tilde{c}_t it∗c~t相加,就变成了新的存储向量 c t = c t − 1 ∗ f t + i t ∗ c ~ t c_t=c_{t-1}* f_t+i_t*\tilde{c}_t ct=ct−1∗ft+it∗c~t
橙色圈出来的部分,输出门的更新,它负责判断是否要输出最后的值:
- 新的 c t c_t ct 先通过一个 tanh ( ⋅ ) \tanh(·) tanh(⋅) 函数,变成 tanh ( c t ) \tanh(c_t) tanh(ct)
- z o z^o zo乘以权重 W o W_o Wo,加上偏置向量 b o b_o bo,经过输出门,变成了 o t = σ ( W o z o + b o ) o_t=\sigma(W_oz^o+b_o) ot=σ(Wozo+bo)
- 把 tanh ( c t ) \tanh(c_t) tanh(ct) 和 o t o_t ot 按元素相乘,得到新的隐藏层状态 h t = o t ∗ tanh ( c t ) h_t=o_t*\tanh(c_t) ht=ot∗tanh(ct)
- 隐藏层状态 h t h_t ht 通过一个softmax函数,得到最后的输出 y t = s o f t m a x ( h t ) y_t=softmax(h_t) yt=softmax(ht)

更复杂一点,LSTM 中引入了 Memory Cell 中存储的结果 c t c^t ct 和隐藏层状态 h t h^t ht,形成 “peephole”。即原来的输入只有 x t x^t xt,现在变成了 [ c t − 1 , h t − 1 , x t ] [c^{t-1}, h^{t-1}, x^t] [ct−1,ht−1,xt],则:
- z f = W f [ c t − 1 , h t − 1 , x t ] z^f=W_f[c^{t-1}, h^{t-1}, x^t] zf=Wf[ct−1,ht−1,xt],是遗忘门(Forget Gate)的输入
- z i = W i [ c t − 1 , h t − 1 , x t ] z^i=W_i[c^{t-1}, h^{t-1}, x^t] zi=Wi[ct−1,ht−1,xt],是输入门(Input Gate)的输入
- z = W [ c t − 1 , h t − 1 , x t ] z=W[c^{t-1}, h^{t-1}, x^t] z=W[ct−1,ht−1,xt],是真正的输入(和输入门的输入是不一样的)
- z o = W o [ c t − 1 , h t − 1 , x t ] z^o=W_o[c^{t-1}, h^{t-1}, x^t] zo=Wo[ct−1,ht−1,xt],是输出门(Output Gate)的输入
Recurrent Neural Network (Part II)(P21)
接着上一P,继续讲循环神经网络,这里讲 RNN 如何学习。
首先是Loss function,这里只举了一个例子讲 Loss function 是预测值和实际值的交叉熵损失之和。
然后是如何 training,用到的仍然是梯度下降法,用到后向传播,不过这里是 BPTT(Backpropogation through time):
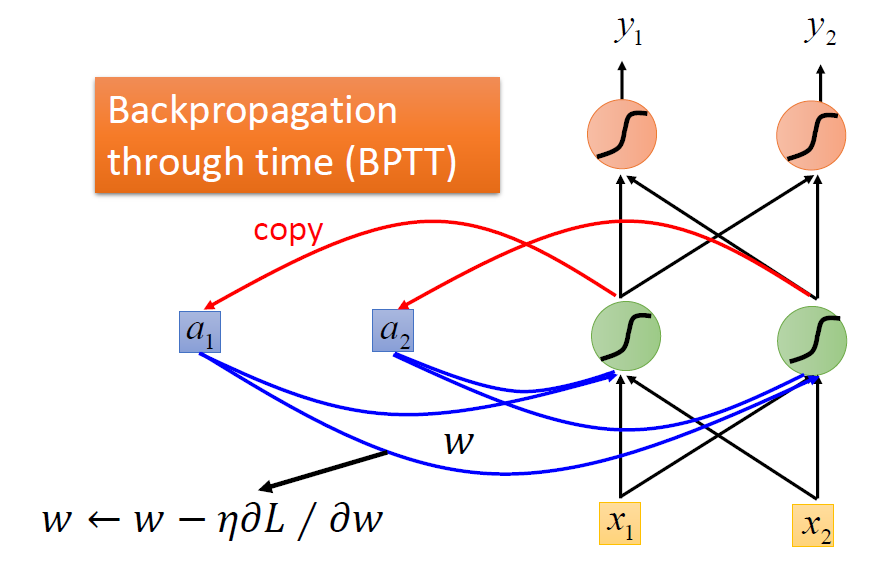
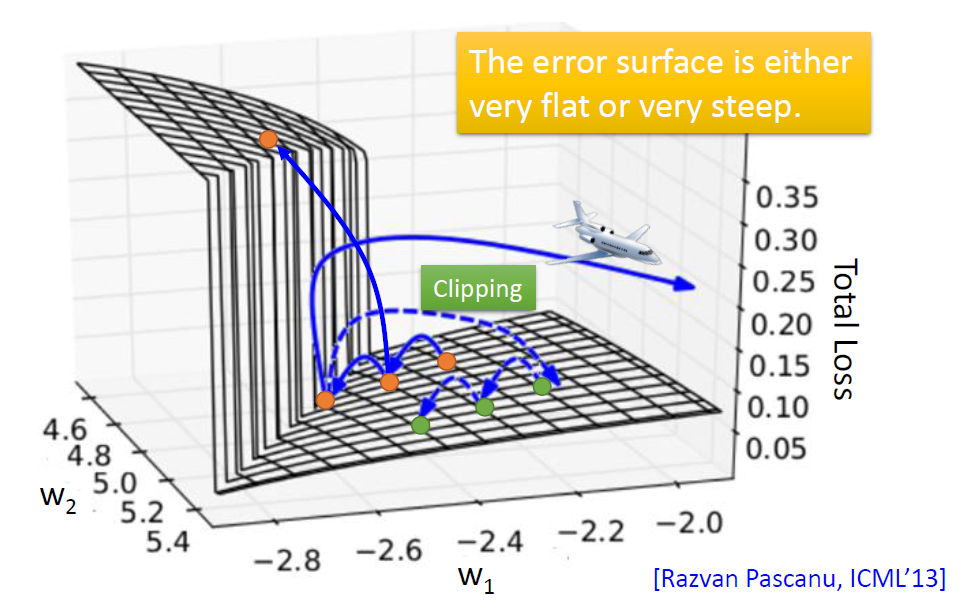
RNN 虽好,但是它在训练时会遇到一些问题(梯度爆炸、梯度消失),李宏毅老师举了例子来说明梯度爆炸的问题。
因为error surface太陡峭,在更新参数时很容易飞出去。
然后,李宏毅老师提供了一些解决技巧。
Q: 有什么解决的方法?
A:
- Clipping:当梯度更新超过某个值时,就让它等于这个值。可以在一定程度上缓解这个问题。
- LSTM. 可以解决梯度消失,但不能解决梯度爆炸。
Q: 为什么可以解决梯度消失?
A:
a. 记忆的值和输入的值是相加而不是相乘。
b. 之前的运算结果对LSTM的影响是一直存在,不会消失,除非遗忘门关上。
Gated Recurrent Unit (GRU) 比 LSTM 简单,只有两个门,如果 LSTM 过拟合太严重,可以尝试GRU。
其它变体:Clockwise RNN、 Structurally Constrained Recurrent Network (SCRN)- 用单位矩阵初始化一般的RNN + ReLU
一般,不用单位矩阵时,sigmoid 效果比 ReLU 好。
李宏毅老师讲了更多关于RNN的应用场景。
多对一(Many to one):输入是向量序列,输出只有一个向量。
比如:
- 情感分析(Sentiment Analysis):输入一个句子,输出态度是“正面”或“负面”
- 关键词提取(Key Term Extraction):输入一篇文档,输出它的关键词
多对多(Many to many):
- 输入输出都是向量序列,但是输出更短。
比如:
- 语音识别(Speech Recognition):输入声音,输出文字
- CTC(Connectionist Temporal Classification)
- 输入输出都是向量序列,没有限制。
比如:
- 机器翻译(Machine Translation)
除了序列,其它应用:
- 句法分析(Syntactic parsing)
序列到序列的自动编码器(文本、语音)
- 聊天机器人(Chat-bot)
- 视频描述生成(Video Caption Generation)
- 图像描述生成(Image Caption Generation)
基于注意力机制的模型(Attention based Model)
- 阅读理解(Reading Comprehension)
- 视觉问答(Visual Question Answering)
- 语音问答(Speech Question Answering)
更多学习资料:
- The Unreasonable Effectiveness of Recurrent Neural Networks:http://karpathy.github.io/2015/05/21/rnn-effectiveness/
- Understanding LSTM Networks:http://colah.github.io/posts/2015-08-Understanding LSTMs/
最后,李宏毅老师描述了 RNN 和 Structured Learning 的关系。
RNN 和 Structured Learning 对比
RNN, LSTM:
- 单向RNN无法考虑整个序列
- 成本和误差并不一定相关
- 深度
HMM, CRF, Structured Perceptron/SVM:
- 用 Viterbi 算法,可以考虑整个序列(双向RNN可以克服)
- 成本是误差的上界

RNN 和 Structured Learning 可以结合起来,同时享有两者的优点。
比如:
- 在语音识别中,CNN/LSTM/DNN + HMM
HMM公式: P ( x , y ) = P ( y 1 ∣ s t a r t ) ∏ l = 1 L − 1 P ( y l + 1 ∣ y l ) P ( e n d ∣ y L ) ∏ l = 1 L P ( x l ∣ y l ) P(x, y)=P\left(y_{1} \mid start \right) \prod\limits_{l=1}^{L-1} P\left(y_{l+1} \mid y_{l}\right) P\left(end \mid y_{L}\right) \prod\limits_{l=1}^{L} \textcolor{#0000FF}{P\left(x_{l} \mid y_{l}\right)} P(x,y)=P(y1∣start)l=1∏L−1P(yl+1∣yl)P(end∣yL)l=1∏LP(xl∣yl)
最后一项的计算可以借助RNN:
P ( x l ∣ y l ) = P ( x l , y l ) P ( y l ) = P ( y l ∣ x l ) P ( x l ) P ( y l ) \textcolor{#0000FF}{P\left(x_{l} \mid y_{l}\right)} = \frac{P(x_l,y_l)}{P(y_l)}=\frac{\textcolor{#FF0000}{P(y_l\mid x_l)}P(x_l)}{\textcolor{green}{P(y_l)}} P(xl∣yl)=P(yl)P(xl,yl)=P(yl)P(yl∣xl)P(xl)
其中, P ( y l ∣ x l ) \textcolor{#FF0000}{P(y_l\mid x_l)} P(yl∣xl)可以用 RNN 来得到; P ( y l ) \textcolor{green}{P(y_l)} P(yl) 可以用计数的方式得到。- 语义标注:双向LSTM+CRF/结构化的SVM
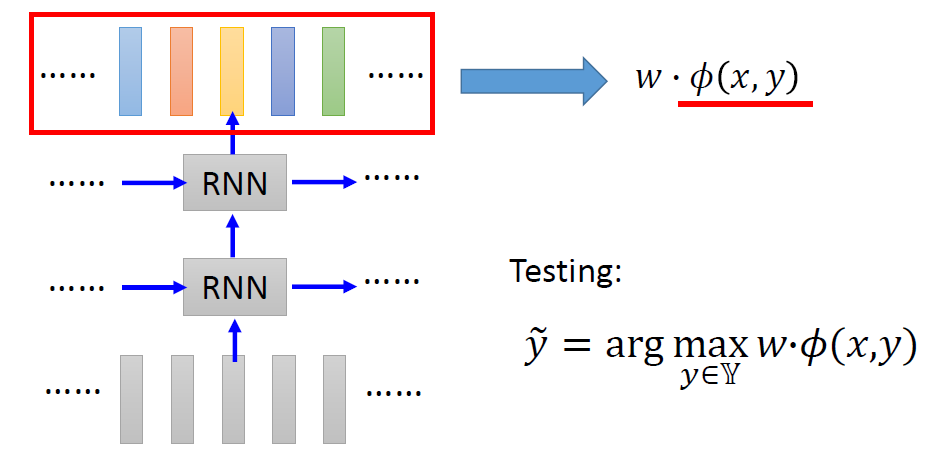
最后,李宏毅老师用 GAN(Generative Adversarial Network 生成对抗神经网络)来说明 Structured Learning 可行的原因。
神经网络未来的趋势可能是变得deep并且structured,这里李宏毅老师介绍了他的另一门课程——Machine learning and having it deep and structured (MLDS) ,这门课程只略微复习 DNN、CNN 的内容,侧重讲 Deep learning 和 Structured learning。
Unsupervised Learning - Word Embedding(P23)
P22 半监督学习的内容上面已经写了,所以这边继续写 P23,以词嵌入为例讲无监督学习。
首先,李宏毅老师介绍了 1-of-N Encoding,引入词嵌入(Word Embedding)
1-of-N Encoding,又叫one-hot encoding(独热编码),一个向量表示一个词,只有一个维度是1,其它维度都是0。
比如:
- apple = [ 1 0 0 0 0]
- bag = [ 0 1 0 0 0]
- cat = [ 0 0 1 0 0]
- dog = [ 0 0 0 1 0]
- elephant = [ 0 0 0 0 1]
优点:简单,方便
缺点:维度大,占用空间大,且无法表达两个词之间的关系。比如 cat 和 dog 都是动物,这两个词应该比较接近,cat 和 bag 之间的关系应该比较远,但是这种编码方式无法体现出这种关系。
一个理想的方法是Word Embedding,将单词降维,嵌入到高纬度的向量空间中,使得相似的词在向量空间中比较接近。
生成词向量的过程是无监督的,我们只知道输入是一堆文本,但是不知道神经网络会输出什么。
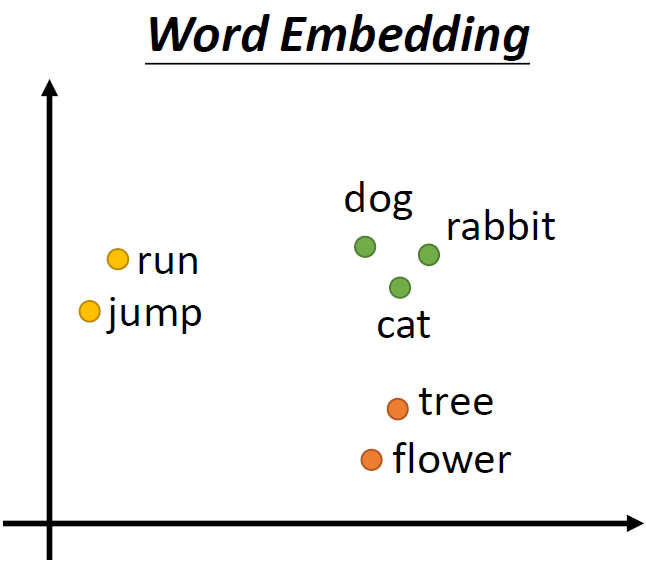
Q:如何计算得到词嵌入?
A:auto-encoder 是不可行的,可以通过一个词汇的上下文来理解它。
Q:如何利用上下文?
A:有两类方法:
- 基于计数的方法(count based)
如果单词 w i w_i wi 和 w j w_j wj 经常一起出现,那么它们的词向量 V ( w i ) V(w_i) V(wi) 和 V ( w j ) V(w_j) V(wj) 一定很接近。希望两个词向量的内积 V ( w i ) ⋅ V ( w j ) V(w_i)·V(w_j) V(wi)⋅V(wj) 与 单词 w i w_i wi 和 w j w_j wj在同一篇文档中一起出现的次数 N i j N_{ij} Nij 相关。
这里常用的一个方法就是:Glove Vector- 基于预测的方法(prediction based)
根据 w i − 1 w_{i-1} wi−1 预测 w i w_i wi
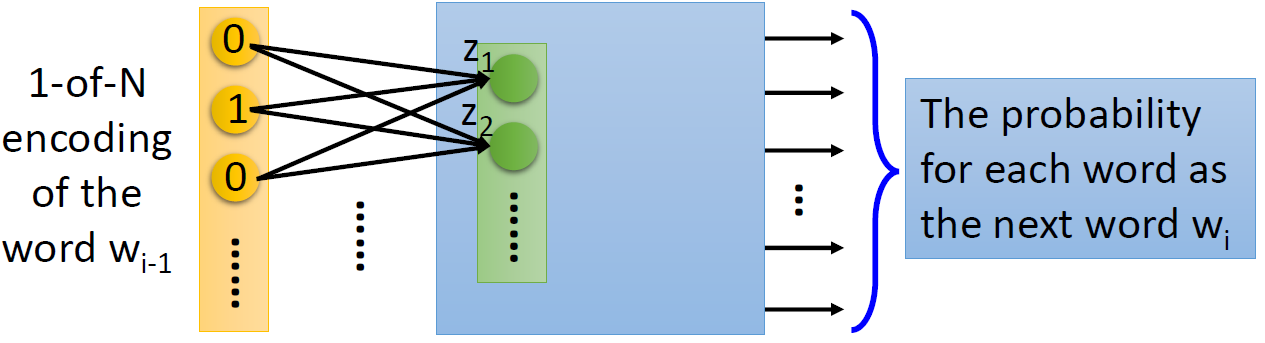
输入单词 w i − 1 w_{i-1} wi−1 的 1-of-N 编码,通过神经网络,输出每个单词成为 w i w_i wi 的概率。
可以拿出这个神经网络的第一个隐藏层的神经元 [ z 1 z 2 … ] [z_1 z_2 \ldots] [z1z2…],用它作为单词 w w w 的词向量表示 V ( w ) V(w) V(w)
可以进一步拓展,根据前面两个词 w i − 2 w_{i-2} wi−2、 w i − 1 w_{i-1} wi−1 来预测 w i w_i wi,每一维度参数共享(下图中相同颜色的线表示权重相同),否则一个单词会有两个词向量 。
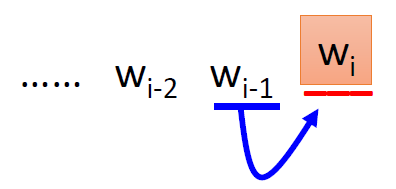
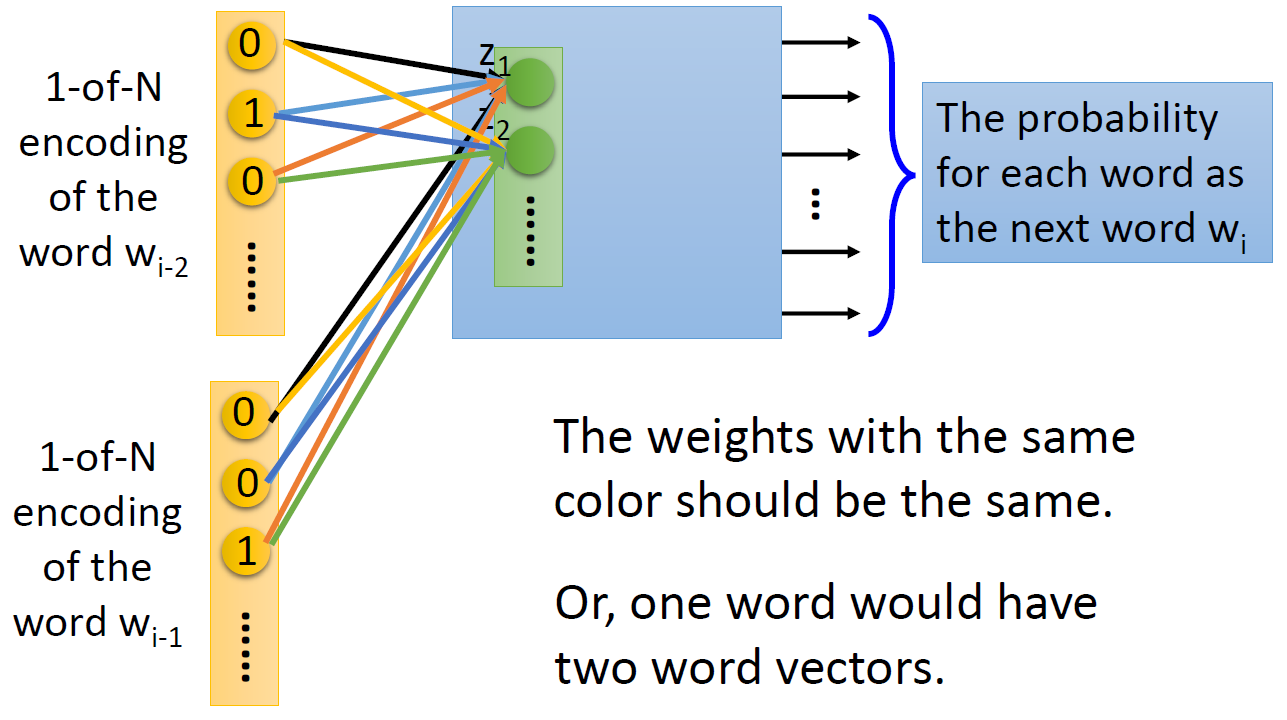
Q:在基于预测的方法中如何训练?
A:最小化预测值和目标值的交叉熵损失。网络结构有几种变体,其中最常见的有两类:
- Continuous bag of word (CBOW) 模型
给定上下文预测单词
- Skip gram
给定单词预测它的上下文
注:这里的神经网络不是DNN,一般只有一个隐藏层。


最后,李宏毅老师介绍了词嵌入中一些有意思的现象和应用,比如可以做类比、多语言的嵌入(Multi-lingual Embedding)、多领域的嵌入(Multi-domain Embedding)、文档嵌入(Document Embedding)等等。