爬取拉勾网招聘信息
1、在网页源代码中搜索信息,并没有搜到,判断网页信息使用Ajax来实现的
2、查看网页中所需的数据信息,返回的是JSON数据;
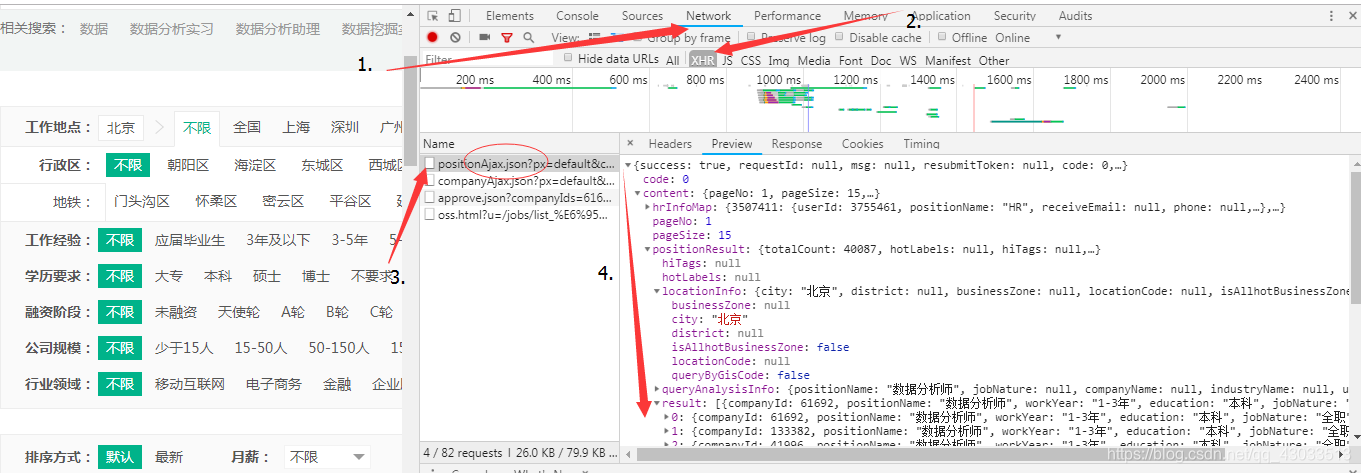
3、条件为北京+数据分析师的公司一共40087家,而实际拉勾网展示的数据只有
15条/页 * 30页 = 450条,所以需要判断想要展示的数据是否能在30页展示完成,超过30页则获取30页数据
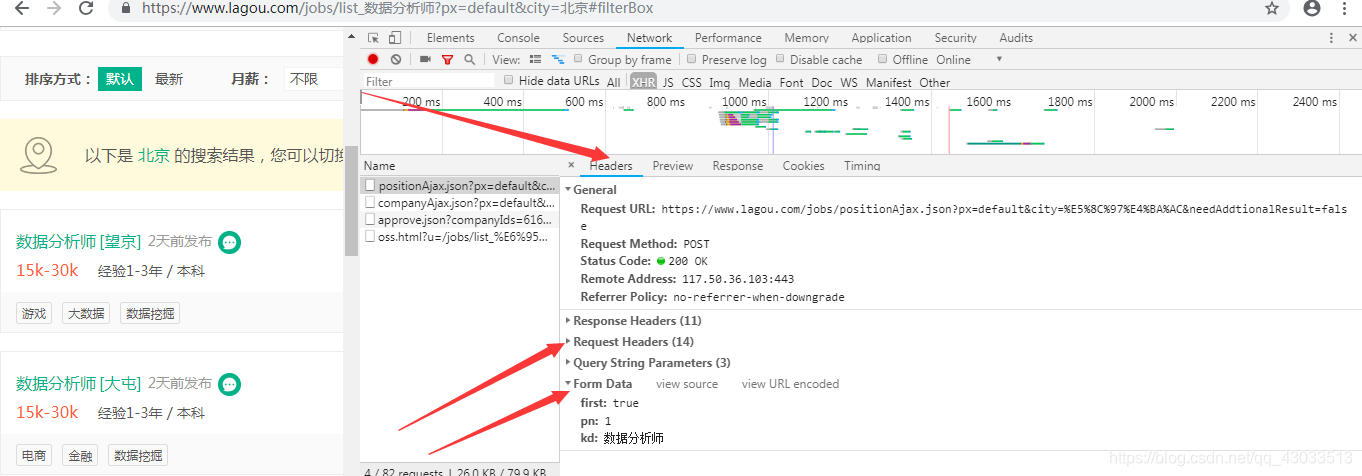
4、获取请求头与Form Data数据
5、将数据以CSV文件存储(首先创建文件,可以最后将表头信息写入)
with open('lagou.csv', 'w', newline = '', encoding='utf-8') as csvfile:
fieldnames = ['businessZones', 'companyFullName', 'companyLabelList', 'companyShortName', 'companySize', 'district',
'education', 'financeStage', 'firstType', 'industryField', 'industryLables', 'linestaion',
'positionAdvantage', 'positionName', 'publisherId', 'salary', 'secondType', 'stationname', 'workYear']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
6、源代码展示
import json
import requests
import math
import time
import csv
headers = {
'Cookie':'LGUID=20160325221916-8e713da1-f294-11e5-baa9-5254005c3644; __guid=237742470.2209186392686119200.1542463319285.1892; WEBTJ-ID=20181117220200-16721fa777529f-063fc0ee1ebcef-5768397b-1049088-16721fa77761fb; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1542463323; _ga=GA1.2.1018218803.1542463324; _gid=GA1.2.545935771.1542463324; user_trace_token=20181117220345-9917d84f-ea71-11e8-892e-5254005c3644; LGSID=20181117220345-9917db98-ea71-11e8-892e-5254005c3644; PRE_UTM=m_cf_cpt_baidu_pc; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Fs%3Fie%3Dutf-8%26f%3D8%26rsv_bp%3D1%26rsv_idx%3D1%26tn%3Dbaidu%26wd%3Dlagouwang%26oq%3D%252526lt%25253BSDN%2525E5%25258F%252591%2525E5%2525B8%252583%2525E7%25259A%252584%2525E5%25258D%25259A%2525E5%2525AE%2525A2%2525E5%25258F%2525AF%2525E4%2525BB%2525A5%2525E4%2525BF%2525AE%2525E6%252594%2525B9%26rsv_pq%3Ded43d71700033d83%26rsv_t%3D43b1GYsCSHSQp1N%252FIp1eR1J3VXskMjt44RcbJkSNM8%252BbE%252Fc4aKUjcI%252FhflA%26rqlang%3Dcn%26rsv_enter%3D1%26rsv_sug3%3D10%26rsv_sug1%3D3%26rsv_sug7%3D100%26rsv_sug2%3D0%26inputT%3D25206156%26rsv_sug4%3D25206157; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Flp%2Fhtml%2Fcommon.html%3Futm_source%3Dm_cf_cpt_baidu_pc; JSESSIONID=ABAAABAAADEAAFI6E3B7886F4C8194B687AAD66C7925F67; index_location_city=%E5%85%A8%E5%9B%BD; SEARCH_ID=96d9378ed73e4c278dc3c4b140ecebaf; LGRID=20181117220435-b693f2da-ea71-11e8-a49f-525400f775ce; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1542463375; monitor_count=7',
'Host':'www.lagou.com',
'Origin':'https://www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88labelWords=sug&fromSearch=true&suginput=shujufenxishi',labelWords=sug&fromSearch=true&suginput=shujufenxishi',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token':'None',
'X-Requested-With':'XMLHttpRequest'
}
# 创建一个csv文件,并将表头信息写入文件中
with open('lagou.csv', 'w', encoding='utf-8') as csvfile:
fieldnames = ['businessZones', 'companyFullName', 'companyLabelList', 'companyShortName', 'companySize', 'district',
'education', 'financeStage', 'firstType', 'industryField', 'industryLables', 'linestaion',
'positionAdvantage', 'positionName', 'publisherId', 'salary', 'secondType', 'stationname', 'workYear']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
# 判断所查询的信息是否用30页可以展示完,大于30页的爬取30页内容
def get_page(url, params):
html = requests.post(url, data=params, headers=headers)
json_data = json.loads(html.text)
total_count = json_data['content']['positionResult']['totalCount'] # 获取信息公司信息总数
page_number = math.ceil(total_count / 15) if math.ceil(total_count / 15) < 30 else 30
get_info(url, page_number)
def get_info(url, page):
for pn in range(1, page + 1):
params = {
'first': 'true' if pn == 1 else 'false', # 第一页点击是true,其余页均为false
'pn':str(pn), # 传入页面数的字符串类型
'kd':'数据分析师' # 想要获取的职位
}
try:
html = requests.post(url, data=params, headers=headers)
json_data = json.loads(html.text)
results = json_data['content']['positionResult']['result'] # 获取JSON数据内容
for result in results: # 获取每条数据并以字典类型存储
infos = {
'businessZones' : result['businessZones'],
'companyFullName' : result['companyFullName'],
'companyLabelList' : result['companyLabelList'],
'companyShortName' : result['companyShortName'],
'companySize' : result['companySize'],
'district' : result['district'],
'education' : result['education'],
'financeStage' : result['financeStage'],
'firstType' : result['firstType'],
'industryField' : result['industryField'],
'industryLables' : result['industryLables'],
'linestaion' : result['linestaion'],
'positionAdvantage' : result['positionAdvantage'],
'positionName' : result['positionName'],
'publisherId' : result['publisherId'],
'salary' : result['salary'],
'secondType' : result['secondType'],
'stationname' : result['stationname'],
'workYear' : result['workYear']
}
print('-------------')
print(infos)
write_to_file(infos) # 调用写入文件函数
time.sleep(2)
except requests.RequestException :
pass
# 将数据追加写入之前创建的lagou.csv文件中
def write_to_file(content):
with open('lagou.csv', 'a', newline='') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writerow(content)
csvfile.close()
# 传入url ,(url中参数包括,城市:北京;),引用get_page函数
if __name__ == '__main__':
url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false'
params = {
'first': 'true',
'pn': '1',
'kd': '数据分析师'
}
get_page(url, params)