1.需求背景
拉勾网的爬虫是做的很好的,要想从他的网站上爬取数据,那可以说是相当的不容易啊。如果采取一般的requests + xpath解析,很快就能给你识别为爬虫,并提示你操作频繁。基于这种情况,只能使用selenium来进行爬取,并且在爬取的时候还不能太快,太快也容易闪到腰的,下面是具体的实现代码,部分代码来自CSDN博客,我只是根据2020年4月13日的页面进行了代码修改,因为拉勾网随时都在更新自己的网站,做反爬虫机制,需要不断的去修改我们的代码,才能适应。以下代码仅供参考。
2.实现代码
import re
from lxml import etree
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import csv
class LagouSpider(object):
# chromedriver的绝对路径
driver_path = r'D:\Python\chromedriver.exe'
def __init__(self):
self.driver = webdriver.Chrome(executable_path=self.driver_path)
self.url = 'https://www.lagou.com/jobs/list_Python/p-city_282'
self.position_info = []
def run(self):
self.driver.get(self.url) # 打开网页
count = 1
while True:
print('正在获取第{}页的数据...'.format(count))
self.parse_detail_page(self.driver.page_source)
# 如果页数是最后一页,则退出循环
if re.search(r'class="pager_next pager_next_disabled"',self.driver.page_source):
break
self.next_page() # 点击进入下一页
count += 1
self.driver.quit() # 将浏览器退出
def parse_detail_page(self,html):
source_html = etree.HTML(html) # 解析页面
detail_list = source_html.xpath('//a[@class="position_link"]/@href') # 找到每一页里面的职位详情页链接
self.driver.execute_script("window.open()") # 开启新的标签页
self.driver.switch_to.window(self.driver.window_handles[1]) # 切换到新的标签页
for url in detail_list: # 遍历职位的详情页
self.driver.get(url) # 打开职位的详情页
detail_url = etree.HTML(self.driver.page_source) # 解析详情页
company_name = detail_url.xpath("//h4[@class='company']/text()")[0].replace('招聘','')
name = re.findall(r'<h1 class="name">([^<]*)',self.driver.page_source)[0] # 得到职位名称
advantage = re.findall(r'职位诱惑:.*?<p>([^<]*)',self.driver.page_source,re.DOTALL)[0] # 得到职位诱惑内容
job_request = detail_url.xpath('//dd[@class="job_request"]')
for job_info in job_request:
salary = job_info.xpath('.//span[@class="salary"]/text()')[0] # 获取薪资
job_info_other = job_info.xpath('.//span/text()') # 获取职位要求信息,薪资后面跟的那一串简单信息
req = re.sub('/', '', ','.join(job_info_other[1:]))
request = re.sub(' ','',req) # 去除每个逗号前的空格
job_descript = detail_url.xpath('//div[@class="job-detail"]//p/text()') # 获取职位描述
job_descript = ' '.join(job_descript)
job_descript = "".join(job_descript.split())# 此处的split是为了去除\xao(\xa0 是不间断空白符 )
address = re.findall(r'<input type="hidden" name="positionAddress" value="([^"]*)',self.driver.page_source)[0] # 获取工作地点
position = { # 将获取到的数据存入字典
'company_name':company_name,
'name':name,
'address':address,
'advantage':advantage,
'salary':salary,
'request':request,
'job_descript':job_descript
}
sleep(1) # 睡一下 以防开启太快被临时封ip
self.position_info.append(position) # 将存放数据的字典添加到列表中
self.write_to_csv() # 数据写入csv文件中
print(self.position_info)
print('' * 30)
# 清空列表
self.position_info = []
self.driver.close() # 关闭标签页
self.driver.switch_to.window(self.driver.window_handles[0]) # 切换页面
def next_page(self):
# 找到下一页标签
element = WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "pager_next")))
element.click() # 点击下一页标签
sleep(1)
def write_to_csv(self): # 写入文件
header = ['company_name','name', 'address','advantage','salary','request','job_descript']
with open('positons.csv','a',newline='',encoding='utf-8') as fp :
write = csv.DictWriter(fp, header)
with open("positons.csv", "r", newline="", encoding='utf-8') as f:
reader = csv.reader(f)
if not [row for row in reader]:
write.writeheader()
write.writerows(self.position_info)
else:
write.writerows(self.position_info)
if __name__ == '__main__':
spider = LagouSpider()
spider.run()
程序运行截图:

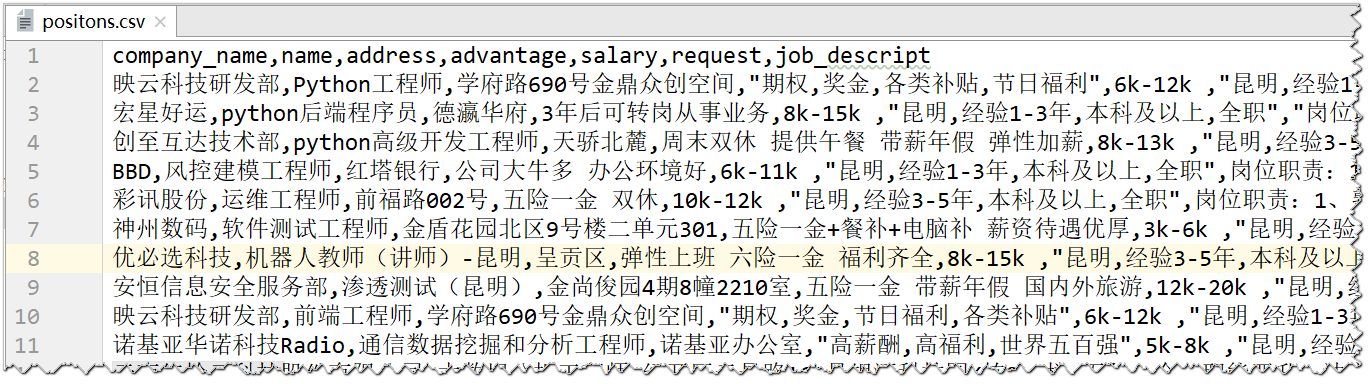
爬取后的CSV截图: