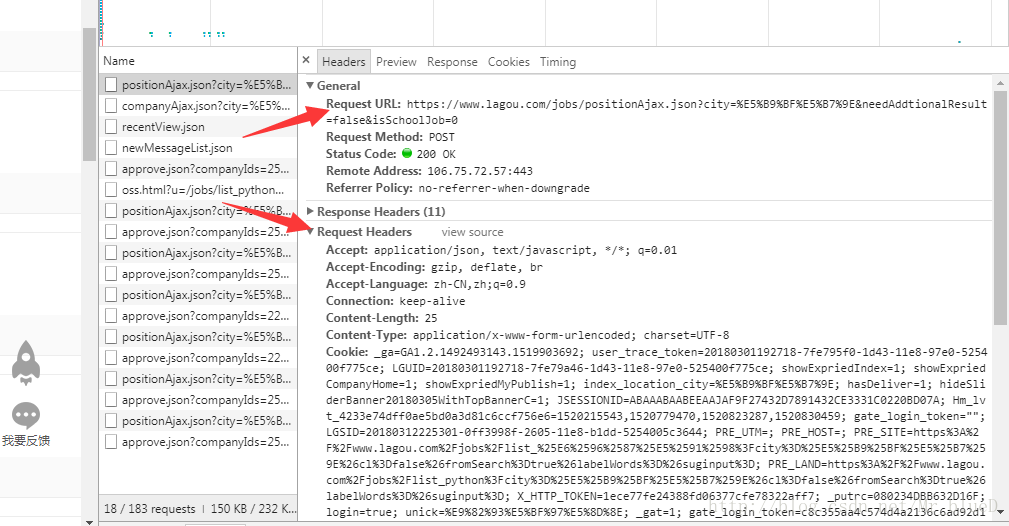
先抓包分析我们想要获取的数据,很明显都是动态数据,所以直接到Network下的XHR里去找,这里我们找到具体数据后,就要去寻分析求地址与请求信息了。

还有需要提交的表单信息
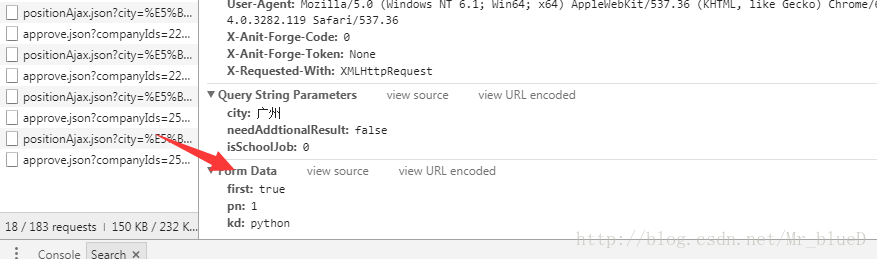
分析完毕之后,我们就可以开始写我们的爬虫项目了。
一.编写Item
item编写比较简单
# 拉钩职位信息
class LagouItem(scrapy.Item):
# 城市
city = scrapy.Field()
# 公司
companyFullName = scrapy.Field()
# 公司规模
companySize = scrapy.Field()
# 地区
district = scrapy.Field()
# 教育程度
education = scrapy.Field()
# 地点
linestaion = scrapy.Field()
# 招聘职务
positionName = scrapy.Field()
# 招聘要求
jobNature = scrapy.Field()
# 工资
salary = scrapy.Field()
# 工作经验
workYear = scrapy.Field()
# 岗位发布时间
createTime = scrapy.Field()二.编写Pipelines
因为我这里是将数据存入数据库中,所以编写pipline之前记得创建好数据库和表,不知道的可以去看我之前写的文章,这里就不说怎么创建了。
import pymysql
def process_item(self, item, spider):
# 如果爬虫名是movie
if spider.name == 'lagou':
try:
self.cursor.execute("insert into Lagou (city, companyName, companySize, district, \
linestaion, positionName, jobNature, education, salary, workYear, showTime) \
VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)", (item['city'], item['companyFullName'], \
item['companySize'], item['district'], item['linestaion'], item['positionName'], \
item['jobNature'], item['education'], item['salary'], item['workYear'], item['createTime']))
self.conn.commit()
except pymysql.Error:
print("Error%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s" % (item['city'], item['companyFullName'], \
item['companySize'], item['district'], item['linestaion'], item['positionName'],\
item['jobNature'], item['education'], item['salary'], item['workYear'], item['createTime']))
return item三.编写Spiders
最后就是编写我们的蜘蛛了。
# -*-coding:utf-8-*-
from scrapy.spiders import Spider
from scrapy import FormRequest
from scrapy.selector import Selector
from Mycrawl.items import LagouItem
import random
import json
import time
class LagouSpider(Spider):
# 爬虫名字,重要
name = 'lagou'
headers = {'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Referer': 'https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput=1'}
allow_domains = ['lagou.com']
url = "https://www.lagou.com/jobs/positionAjax.json?" # &needAddtionalResult=true&isSchoolJob=0"
page = 1
allpage = 0
def start_requests(self):
yield FormRequest(self.url, headers=self.headers,
formdata={
'first': 'false',
'pn': str(self.page),
'kd': 'Python',
'city':'广州'
}, callback=self.parse
)
def parse(self, response):
# print(response.body)
item = LagouItem()
data = json.loads(response.body.decode('utf-8'))
result = data['content']['positionResult']['result']
totalCount = data['content']['positionResult']['totalCount']
resultSize = data['content']['positionResult']['resultSize']
for each in result:
item['city'] = each['city']
item['companyFullName'] = each['companyFullName']
item['companySize'] = each['companySize']
item['district'] = each['district']
item['education'] = each['education']
item['linestaion'] = each['linestaion']
item['positionName'] = each['positionName']
item['jobNature'] = each['jobNature']
item['salary'] = each['salary']
item['createTime'] = each['createTime']
item['workYear'] = each['workYear']
yield item
time.sleep(random.randint(5, 20))
if int(resultSize):
self.allpage = int(totalCount) / int(resultSize) + 1
if self.page < self.allpage:
self.page += 1
yield FormRequest(self.url, headers=self.headers,
formdata={
'first': 'false',
'pn': str(self.page),
'kd': 'Python',
'city':'广州'
}, callback=self.parse
)编写完毕后运行蜘蛛爬取数据。
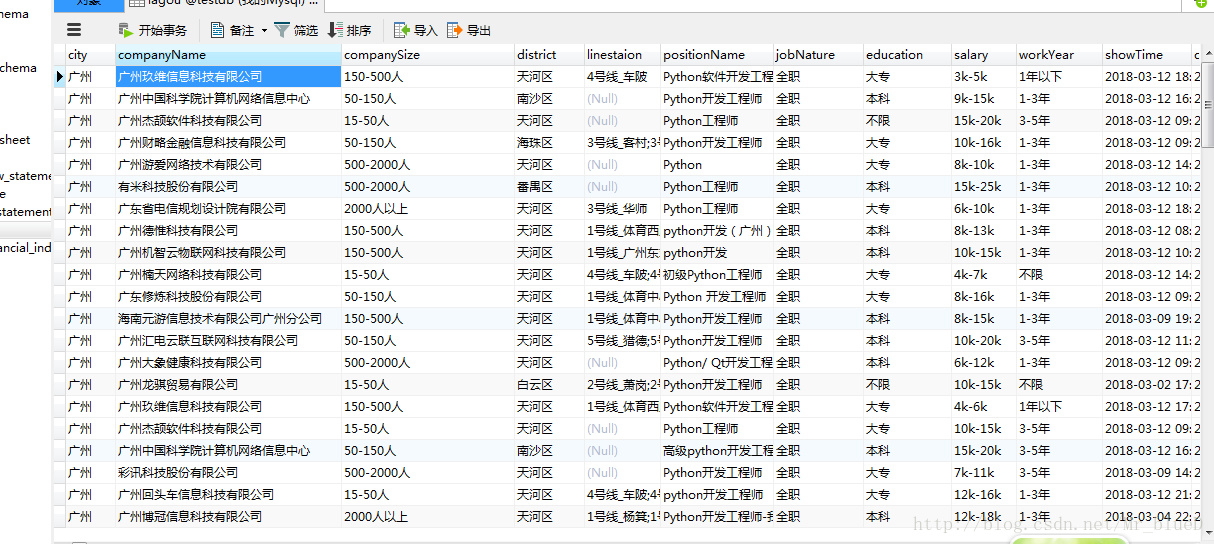
四.结果