Abstract
1)文章提出了新的全局的语义框架融入到整个网络中。网络设计的关键是核卷积,核卷积的关键在于此处的卷积核没有参数学习,是固定的一个核。此核能够模糊local 网络的输出,实则是平滑输出,然后用global网络进行refine
2)后处理上用了一个2D-PCA based 网络模型来过滤外点
Contribution
- 提出了核卷积
- 用dilation卷积扩大感受野
- 整个方法可以不适用人脸检测
Local-global context network
文章网络的主要优点在于考虑了全局信息,point distribution model应用在了后处理上面。这篇文章能够利用dilated卷积,避免了过拟合现象,而能够充分使用带孔卷积的原因在于heavily depends on the implicit kernel convolutions。
预处理
将图像转换为灰度图像,标签就是在gt点的地方置为1,没有使用高斯
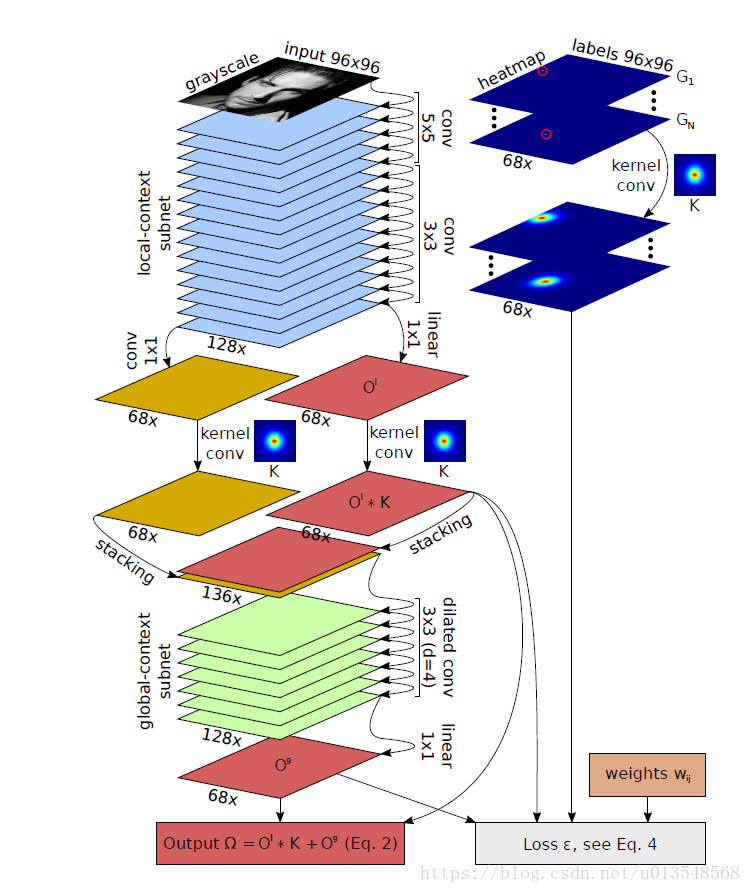
Network architecture
- Local-context, fully-convolutional network
- Convolution with a (customizable) static kernel
- Global-context, dilated fully-convolutional network
- Square error-like loss versus kernel-convolved labels
Local-context subnet
Local-context subnet就是堆积了15个卷积,最后一个1x1的卷积来补偿BN
Kernel convolution
Local-context subnet被kernel卷积。kernal卷积是一个group=1的group convolution,等同于channel-wise的convolution。他在训练和测试的时候都会被用到。
kernal卷积的作用
1、The pixel-wise square loss now correlates with the distance between prediction and ground truth
2、The global-context subnet can take advantage of dilated rather than dense convolutions.
不仅要对网络进行kernal 卷积,同样的对于标签也要进行kernal卷积,一张gt map只有一个点是目标位置而不是高斯这种形式的gt显然是不合理的。
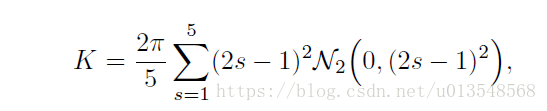
最终的核的形式如上式
将该核进行平移后与未平移的该核做差,得出下面的图
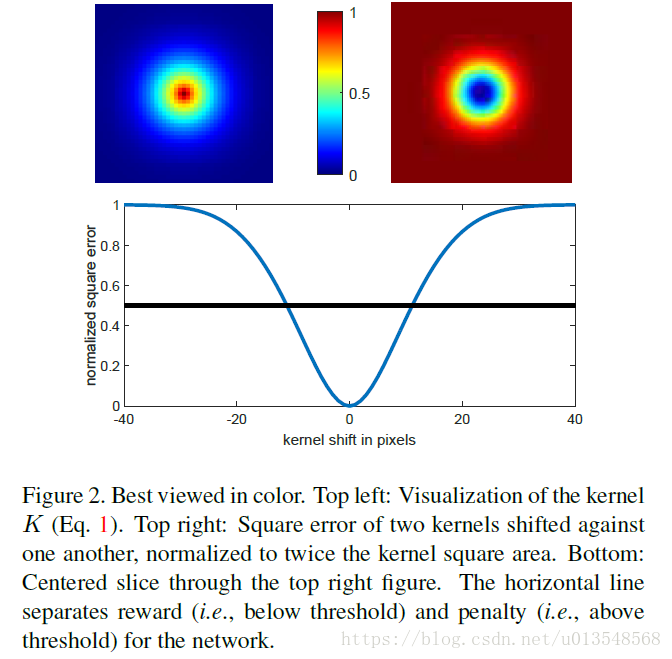
在11px左右normalized error为0.5,所以再11px以内进行奖励,在11px之外进行惩罚
Global-context subnet
在global的语义子网络里,可以使用大的卷积核进行操作,但是为了避免过拟合的现象,就采用带孔卷积更为实际一些。带孔卷积会是一个downsample的过程,会造成结果的不连续,因此不太合理,但是由于之前的map已经被kernal convolution进行了平滑(低通滤波器),所以这里使用带孔卷积的时候不需要考虑带孔卷积带来的不连续情况。
对于local的结果已经很具有判别性了,所以对global的要求是不应该聚焦在pixel的层面上,而应该关注全局的信息多一些。这个的global网络不是从头开始而是对之前的预测的local结果进行了一个refine的操作。
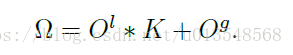
最终的输出是local和global相加的形式,但是只在local和global地方加监督而不再最后的预测的输出加监督。global部分的网络由起个0padded的带孔卷积组成,dilation=4。
Loss
对于landmark点的每一个作者都设置了一个权重,根据是否标注以及是否在界内外。
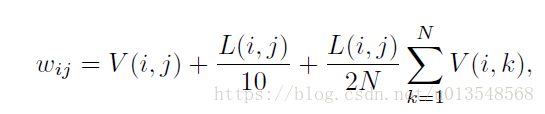
最终的损失是全局加local
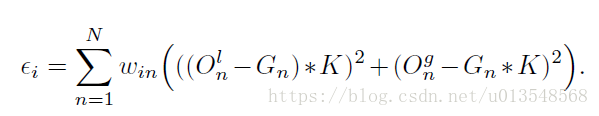
网络结构如下
local和最终的输出的示意图

From heatmaps to coordinates
从热度图到最终的坐标,一般来讲会直接取最大值,但是这种每张map最大值的情形仅仅适用于关键点比较少的情况(疑问脸),然后如果事先确定一个阈值,仅仅在阈值以上的情形是要求取最大,这种情形又是会引进outliers。作者设计了一个2D-PCA based的模型
we interpret the output heatmaps as likelihoods and fit an outlier-robust PCA-based 2D shape model. The model is able to recover from false detections, but also reconstruct occluded or truncated landmarks to a reasonable extent
作者首先对heatmap找到最合适的旋转,产生线性系统等式,每一个像素对应一个等式,用该点像素值进行加权,只有权重大于1%的才考虑进行相关的计算
实验
作者做了很多相关的对比试验,当然作者最后做了一个在全图的实验,证明他们的网络即使不使用bounding box预处理也是可以的。