introduce
现有的检测网络可以根据ROI(region of interest)分为两种子网络——一个是独立于ROI区域的共享的、全卷积的子网络,另一个是不会共享计算的ROI-wise子网络。这样分类的是有历史原因的,因为AlexNet和VGG把整个网络分为两部分,一部分是一个卷积网络后紧跟着一个空间池化层,一部分是几个全连接层。图像分类网络中的空间池化层转换为了检测网络中的ROI池化层。
对于图像分类的平移不变性和目标检测中的平移变化性,一方面,图像级的分类偏爱平移不变性,因为对分类而言图像不发生变化才是好的,也正是如此全卷积网络才能取得如此好的分类效果。另一方面目标检测需要对定位目标,所以需要在一定范围内进行平移变换。
假设图像分类网络中的卷积层对变换不敏感,ResNet的文章中把ROI池化层加入到了卷积网络中,打破了平移不变性,但该方法牺牲了训练和检测的效率,因为引入了大量region-wise层。
R-FCN方法是基于区域(region-based)的检测方法,是一个全卷积网络,大部分的计算在整个图像上进行共享。为了实现上述目标,使用位置敏感分数图(positive-sensitive score map)来解决图像分类中的平移不变性(transform-invariant)和检测中的平移变换(transform-variant)这两个问题。
R-FCN是通过位置敏感分数图来把平移变换加入FCN中,每个分数图都对 相对空间位置的位置信息进行编码。在FCN的最后面,添加一个位置敏感的ROI池化层处理来自分数图的信息。整个结构进行端到端的训练,所有的可学习的层都是卷积层,且共享整幅图像的参数。
R-FCN
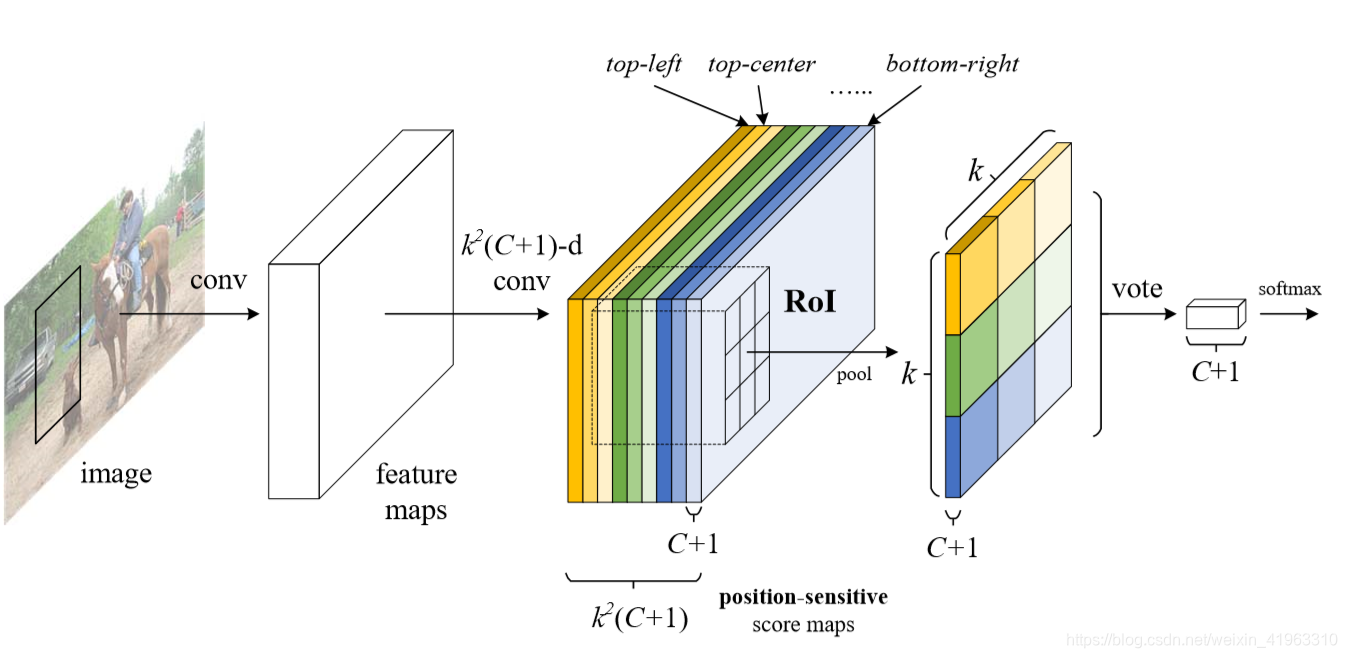
R-FCN的实现步骤(R-FCN的结构可以看作ResNet-101卷积部分+一个1024维的卷积层+一个位置敏感的ROI池化层,不过需要一个额外的RPN进行辅助):
- 先使用ResNet-101中的卷积层部分对整个图像进行卷积,得到特征图(对于原本的ResNet-101网络结构,删除其中的池化层和全连接层,只保留其卷积部分);
- 再使用R-FCN中附加在ResNet-101卷积部分后的一个特殊的卷积层对特征图进行卷积,对每个类和背景都产生 k 2 k^2 k2个位置敏感分数图(position-sensitive score map),所以结果是 k 2 k^2 k2个(c+1)维(c是类别数)的位置敏感分数图。这 k 2 k^2 k2个位置敏感分数图对应一个直接描述相对位置的k×k网格(当k=3时,这9个位置敏感分数图分别对应网格中的top-left,top-center,top-right,…,bottom-left,bottom-center,bottom-right处的网格,详情见下方图像);
- 使用RPN对特征图进行处理,生成候选区域,并将候选区域ROIs与R-FCN共享(R-FCN的作用就是对灭个ROI进行分类)
- 使用一个位置敏感ROI池化层对每一个ROI,聚合各个位置敏感分数图对应位置的特征(k×k个子结果聚合成一个),并输出对应ROI的分数,紧接着进行vote和softmax操作,得到最终检测结果。
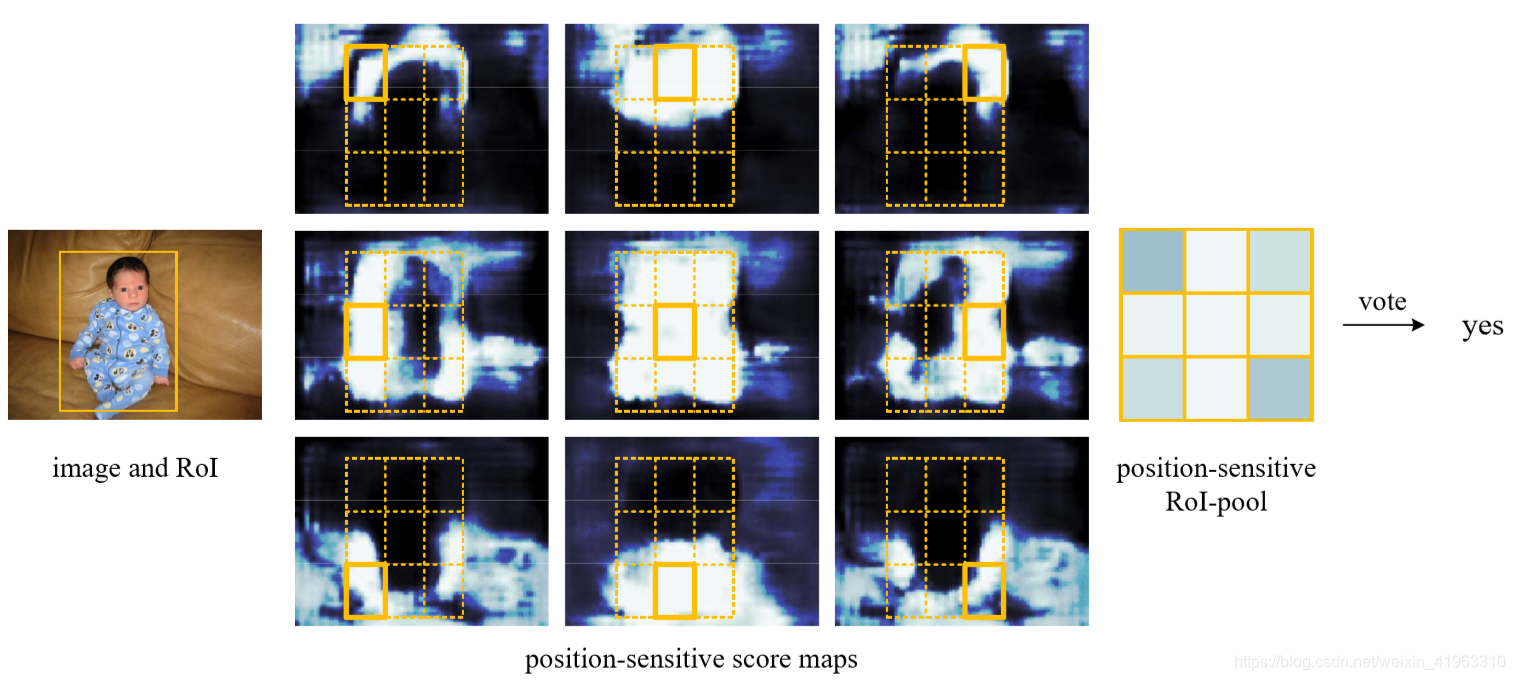
一些细节
-
位置敏感ROI池化操作的实现:
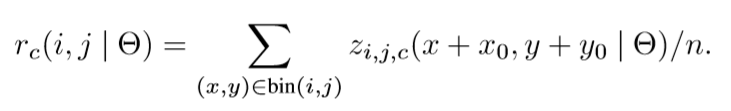
r c ( i , j ) r_c(i,j) rc(i,j)是位置 ( i , j ) (i,j) (i,j)对应的分数图对第c个类别池化的结果, z i , j , c z_{i,j,c} zi,j,c是不属于 k 2 k^2 k2(c+1)分数图的一个分数图, ( x 0 , y 0 ) (x_0,y_0) (x0,y0)是一个ROI的左上角, Θ \Theta Θ代表网络中的所有学习参数。 -
vote操作:平均所有的分数,对每个ROI产生一个 ( C + 1 ) (C+1) (C+1)维的向量 r c ( Θ ) = ∑ i , j C r c ( i , j ∣ Θ ) r_c(\Theta)= \sum^C_{i,j}r_c(i,j| \Theta) rc(Θ)=∑i,jCrc(i,j∣Θ),然后使用softmax( s c ( Θ ) = e r c ( Θ ) / ∑ c ′ = 0 C e r c ′ ( Θ ) s_c(\Theta)=e^{r_c(\Theta)}/ \sum^C_{c^{\prime}=0}e^{r_c^{\prime}(\Theta)} sc(Θ)=erc(Θ)/∑c′=0Cerc′(Θ))进行处理得到最终的检测结果。
-
关于模型的训练:损失函数为
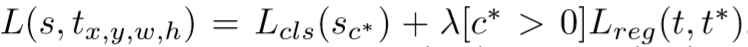
其中 c ∗ c^* c∗是ground_truth的类别, L c l s ( s c ∗ ) = − l o g ( s c ∗ ) L_{cls}(s_{c^*}) = -log(s_{c^*}) Lcls(sc∗)=−log(sc∗), L r e g ( t , t ∗ ) = R ( t , t ∗ ) L_{reg}(t,t^*) = R(t,t^*) Lreg(t,t∗)=R(t,t∗)(其中R(·)是L1正则函数)是边框回归损失, t ∗ t^* t∗是ground_truth的边框。平衡权重 λ = 1 \lambda=1 λ=1。
conclusion
R-FCN利用位置敏感分数图把平移变换引入了目标检测过程,使得检测速度和准确率都有一定程度的提升,但中间仍涉及大量的卷积计算,所以速度上还有提升的空间。