前言
较早的目标检测算法,比如SPP-net,Fast R-CNN和Faster R-CNN,它们的网络结构可以通过RoI池化层分为两个子网络:一个是独立于RoI,共享计算的全卷积子网络,其实这部分就是对整个图像进行处理,提取出输入图像的特征图。另一个是RoI-wise子网络,在这个子网络中并不共享计算,也就是对每个RoI(region of interest)进行分类与回归以完成最终的目标检测。这一类目标检测算法的检测精度较高,但检测速度由于RoI的存在而变得较慢。
还有另一类完全使用卷积网络来进行目标检测的算法,它们的网络结构是基于ResNets和GooLeNets等由全卷积设计的图像分类网络。但是这虽然提升了检测速度,检测精度却完全不行。为了解决这个问题,ResNet在两组卷积层中插入了一个RoI池化层,形成了一个更深的RoI-wise子网络,这么做提升了检测精度,但检测速度却下降了。
为什么会出现这种情况呢?这是因为图像识别中增长的平移不变性(translation invariance)与目标检测中的平移变换性(translation variance)之间存在矛盾。在图像识别中,基于图像级别的识别任务更侧重于平移不变性,比如移动图像中的一个目标,并不会改变图像识别的结果。因此深度卷积网络尽可能保持平移不变性是最好的,ImageNet图像分类任务也证明了这一点。在目标检测中,需要对目标位置进行表达,这在一定程度上属于平移变换性。比如,平移候选框中的一个目标,那么会得到候选框与目标重叠程度的反馈。
R-FCN由共享计算的全卷积结构组成,就像FCN那样。论文提出位置敏感分数图(position-sensitive score maps),它是通过将一些专门化的卷积层作为FCN的输出得到的,目的是将平移变换性融入FCN,每个score map相对于空间位置来对位置信息进行编码。在FCN的顶层,添加一个位置敏感RoI池化层(position-sensitive RoI pooling layer)来管理分数图中的信息,这个层后面没有其他卷积层或全连接层。整个架构的学习是端到端的,所有的可学习的层都是卷积层,并且在整个图像上共享,但是要对目标检测所需的空间信息进行编码。

上表比较了不同的region-based检测方法。可以看到,R-FCN中共享计算的卷积层网络是最深的,RoI-wise子网络的深度为0;而R-CNN有最深的RoI-wise子网络,但没有共享计算的卷积层。
2.R-FCN的结构
像R-CNN一样,R-FCN也是two-stage的目标检测算法:首先生成候选区域,然后对候选区域进行分类与回归。其中,用RPN生成候选区域,根据Faster R-CNN中的方法,实现RPN和R-FCN之间的权值共享。整体结构如下图:
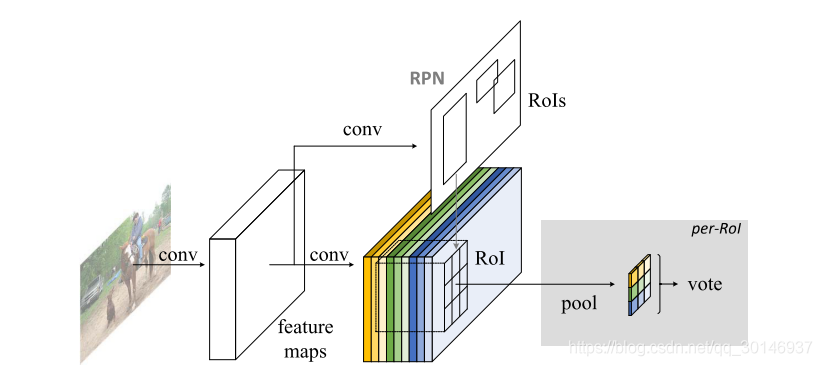
R-FCN的网络结构是基于ResNet-101设计的,在ResNet-101中有一百个卷积层,后面是全局平均池化层和一个处理1000个类别的全连接层。在R-FCN中去掉了平均池化层和全连接层,只使用卷积层从输入图像中提取出特征图,但是对于ResNet-101中最后一个2048-d的卷积,要用一个随机初始化的1024-d 1×1的卷积层对其进行降维,然后添加一个通道数为
的卷积层生成score maps。为什么通道数是
呢? 因为最后一个卷积层要为每个类别生成
个score maps,总共有
个类,因此最后一个卷积层的通道数为
。RPN生成的候选区域(RoIs)被应用到score maps上。在R-FCN中,所有的可学习的层都是卷积层,并且在整个图像上共享计算,每个RoI的计算基本可以忽略。
在conv4以及它之前的所有层没有改变,但是将conv5_1中的步长由2变为1,并且conv5中所有的卷积操作改为空洞卷积,来弥补步长,即在特征图信息损失较少(特征图较大)的情况下,增大感受野。实验证明,在使用空洞卷积后,mAP提升了2.6个百分点。
3.R-FCN的实现方法
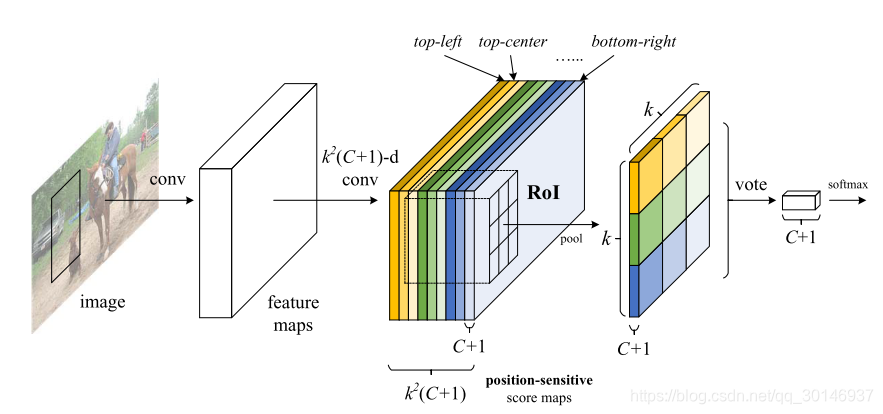
上图说明了R-FCN中的关键结构。图像的特征图在经过最后一个通道数为
的卷积层后生成score maps,就是图中有不同颜色的那个长方体,它的通道数为
。为了在每个RoI中编码位置信息,将每个RoI划分为一个k × k的bin,就是图中k × k ×
的那个长方体。其中每个格子记为(i,j),与前面score maps中具有相同颜色的score map一一对应,并且对应到格子上的位置信息分别是上左、上中、上右……右下。RoI的大小为w×h时,其对应的bin的大小就是w/k × h/k。每个颜色代表一个(i,j)。对于bin中的每个(i,j),在与其对应的颜色相同的(i,j)score map上进行位置敏感的RoI池化操作:

其中
是第c个类的score map对应的bin中的
的池化结果,
是
个score map中的一个score map。(
,
)是RoI的左上角,n是bin中的像素数量,
是网络中所有的参数。在bin中(i,j)的范围是:

在经过上面的池化操作后,bin中每个格子就表示一个位置敏感分数(position-sensitive score),通过对这些score进行average voting,就能为每个RoI产生一个
维的向量:
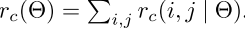
总结一下上面的过程就是:在最后一个卷积层输出position-sensitive score map之后,要对它进行RoI pooling,也就是对bin中每个格子分别进行pooling,注意并不是在所有
维上进行pooling,每个格子只会在对应的
维上进行pooling,也就是在颜色相同的部分上进行pooling。pooling后输出的是
维的
数据,每个维度上的
个数据再加到一起(average voting)就形成了一个
维的向量,代表了RoI中的目标分别属于
个类别的概率。
然后计算类别的softmax进行分类:
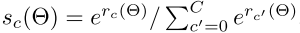
然后用相似的方法进行边界框回归。除了具有 个通道的卷积层,又添加了一个 个通道的卷积层用来进行边界框回归,它们之间是同级的关系。池化层为每个RoI生成4维的 维的数据,然后通过average voting聚合成为一个4维的向量。这个4-d的向量是边界框坐标的参数化表达: 。
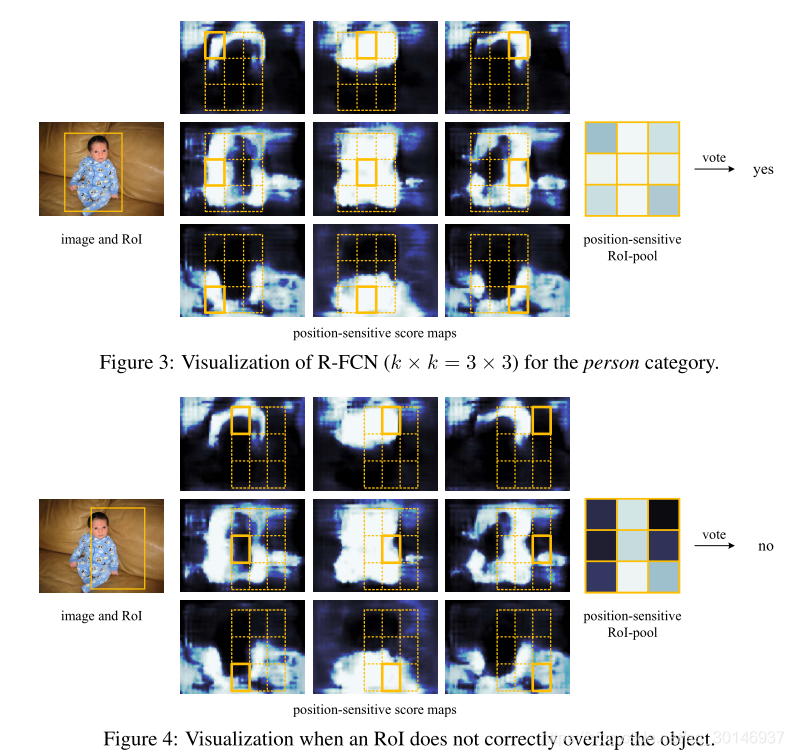
图3和4对k × k = 3 × 3时的score map进行可视化。可以看到,当map位于存在目标的特定位置时,反应很强烈。比如在图3中,位于上中位置的score map在目标的上中位置处得分很高。如果候选框与目标恰好重叠,大多数RoI中的bin会被强烈的激活,voting会很高。相反,如果候选框未与正确的目标重叠(图4),则RoI中有一些bin将不被激活,并且voting很低。
4.训练过程
损失函数参考了Fast R-CNN中的损失函数,也是多任务损失函数,由两部分组成,一是交叉熵损失(分类损失),另一个是边界框回归损失(位置损失)。

其中
表示RoI的真实标记(ground-truth lable),
表示背景。
表示分类误差,
表示边界框回归误差,
表示真实框(ground-truth bpx),当
时,
为1,否则为0。将平衡权重
设为1。将与真实框的IoU至少为0.5的RoI作为正样本,其余都为负样本。
在训练时,每个图像有N个RoI,计算所有RoI的损失函数,然后按照损失由高到低对RoI(包括正样本和负样本)进行排序,选出B个损失最大的RoI,在这些样本上进行后向传播。因为每个RoI的计算可以基本忽略不计,向前传播的时间基本不受N的大小影响。
5.检测过程
从输入图像中提取的特征图由RPN和R-FCN共享,然后RPN生成RoI,R-FCN在这些RoI上计算类别分数,并对边界框进行回归,最后的边界框要进行IoU阈值为0.3的NMS(non-maximum suppression)处理,得到最终的边界框,完成目标检测。
6.与其他网络的区别
1.Fast R-CNN和Faster R-CNN可以被看成是“semi-convolutional”,因为它们在一个卷积网络中共享对整个图像的计算,而在另一个网络中各自处理独立的候选区域。即ROI层后的结构对不同的候选区域是不共享的,在R-FCN中解决了这个问题,也就是将RoI池化层后所有的卷积操作都移到RoI池化层之前,在RoI池化层之后没有其它任何权重层(卷积层和全连接层)。添加position-sensitive score map来解决平移可变性问题。
2.也有一些可以被视为“fully convolutional”,比如OverFeat通过在共享计算的特征图上滑动多尺度窗口来进行目标检测,在这种情况下,可以将单尺度的滑动窗口改造成一个单层的卷积层。
3.另外一些在检测时使用全连接层,来实现在一整个图像上的整体的目标检测,比如YOLO。
