2.相关工作
自然图像中的文本检测已经受到计算机视觉和文档分析社区的广泛关注。然而,大多数文本检测方法主要以两种方式集中于检测水平或近水平文本:1)定位单词的边界框[4,3,17,15,18,33,5,6],2)组合检测和识别程序成为端到端的文本识别方法[8,28]。场景文本检测和识别的综合调查可参考[30,36]。
在本节中,我们将重点介绍为多方向文本检测提供的最相关的工作。在野外进行多4160定向文本检测首先由[31,29]研究。它们的检测管道类似于基于连通分量提取的传统方法,集成了每个字符和文本行的方向估计。 [9]将每个MSER组件视为图中的顶点,然后将文本检测转换为图分区问题。 [32]提出了一种多阶段聚类算法,用于对MSER组件进行分组以检测多向文本。 [28]提出了一种基于SWT [4]的面向多向文本的端到端系统。最近,ICDAR2015文本检测竞赛已经发布了面向多向文本检测的具有挑战性的基准,许多研究人员已经在其上报告了他们的结果。
此外,值得一提的是,最近的两种方法[25,8,6]和我们使用深度卷积神经网络的方法在几个方面都取得了优于传统方法的优越性能:1)学习更强大的组件通过CNN像素标记表示[8]; 2)利用CNN的强大辨别能力,更好地消除误报[6,35]; 3)通过CNN学习一个强大的字符/单词识别器,用于端到端文本检测[25,7]。但是,这些方法仅关注水平文本检测。
3.提议的方法
在本节中,我们将详细描述所提出的方法。 首先,通过完全卷积网络(称为Text-Block FCN)检测文本块。 然后,通过考虑本地信息(MSER组件)从这些文本块中提取多方向文本行候选。 最后,通过字符质心信息消除伪文本行候选。 字符质心信息由较小的完全卷积网络(名为Character-Centroid FCN)提供。
3.1. 文本块检测
在过去几年中,场景文本检测中的大多数主要方法都是基于检测字符。在早期实践[16,18,29]中,大量手动设计的特征用于识别具有强分类器的字符。最近,一些作品[6,8]取得了很好的成绩,采用CNN作为字符检测器。然而,即使是最先进的字符检测器[8]在复杂的背景下仍然表现不佳(图4(b))。由于三个方面,字符检测器的性能受到限制:首先,字符易受多种条件的影响,如模糊,不均匀照明,低分辨率,断开行程等;其次,背景中的大量元素在外观上与人物相似,使得它们极难区分;第三,角色本身的变化,例如字体,颜色,语言等,增加了分类器的学习难度。相比之下,文本块具有更多可区分和稳定的属性。文本块的局部和全局外观都是区分文本区域和非文本区域的有用线索(图4(c))。完全卷积网络(FCN)是最近提出的一种深度卷积神经网络,它在像素级识别任务上取得了很好的性能,如对象分割[12]和边缘检测[26]。由于以下几个优点,这种网络非常适合于检测文本块:1)同时考虑本地和全局上下文信息。 2)以端到端的方式进行培训; 3)受益于完全连接的层的移除,FCN在像素标记中是有效的。在本节中,我们将学习名为Text-Block FCN的FCN模型,以整体方式标记文本块的显着区域。
Text-Block FCN
我们将VGG 16层网络[22]转换为我们的文本块检测模型,如图3所示。前5个卷积阶段来自VGG 16层网络。卷积阶段的感受域大小是可变的,有助于不同阶段可以捕获具有不同大小的上下文信息。每个卷积阶段之后是去卷积层(等于1×1卷积层和上采样层)以生成相同大小的特征图。然后,辨别和分层融合图是这些上采样映射的深度级联。最后,用1×1卷积层和S形层替换完全连接的层,以有效地进行像素级预测。
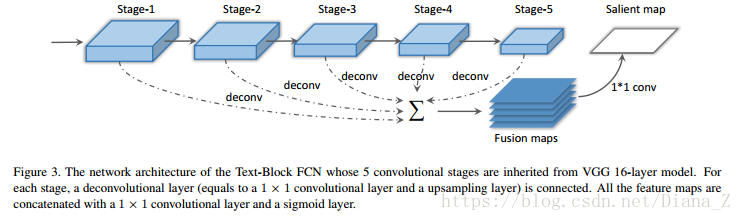
在训练阶段,由于以下原因,每个文本行或单词的边界框内的像素被认为是正区域:首先,相邻字符之间的区域与其他非文本区域不同;其次,全局文本结构可以纳入模型;第三,文本行或单词的边界框易于注释和获得。地面实况图的一个例子如图5所示。交叉熵损失函数和随机梯度下降用于训练该模型。

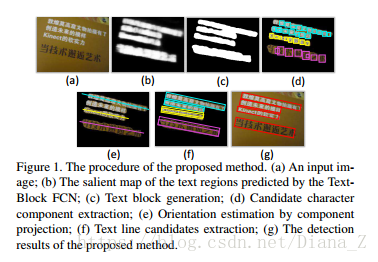
在测试阶段,文本区域的salient map,利用来自不同阶段的所有上下文信息,首先由训练的Text-Block FCN模型计算。如图2所示,阶段1的特征图捕获更多局部结构,如梯度(图2(b)),而较高阶段捕获更多全局信息(图2(e)(f)) 。然后,保留概率大于0.2的像素,并将连接的像素组合在一起成为几个文本块。文本块检测结果的一个例子如图1(c)所示。

3.2. 多方位文本行候选生成
在本节中,我们将介绍如何基于文本块形成多方向文本行候选。虽然文Text-Block FCN检测到的文本块提供了文本行的粗略定位,但它们仍然远远不能令人满意。为了进一步提取文本行的准确边界框,需要考虑有关文本的方向和比例的信息。文本行或单词中的字符组件显示文本的比例。此外,可以通过分析字符组件的布局来估计文本的方向。首先,我们通过MSER [16]提取文本块中的字符组件。然后,类似于文档分析[19]中的许多歪斜校正方法,通过组件投影来估计文本块内文本行的方向。最后,通过有效组合块级(全局)提示和组件级别(本地)提示的新方法提取文本行候选。
字符组件提取
我们的方法使用MSER [16]来提取字符组件(图1(d)),因为MSER对比例,方向,位置,语言和字体的变化不敏感。采用两个约束来消除大部分虚假成分:面积和纵横比。具体地,字符候选的最小面积比需要大于阈值T1,并且它们的纵横比必须限于[1/T2,T2]。在这两个约束条件下,大多数错误组件都被排除在外。
方向估计
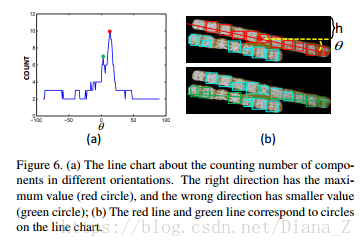
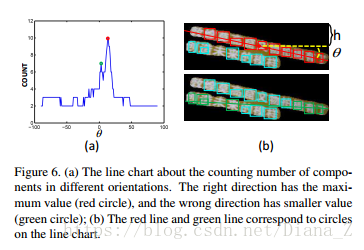
在本文中,我们假设来自同一文本块的文本行具有大致均匀的空间布局,并且来自一个文本行的字符是直线或近直线的排列。受文献分析[19]中基于投影轮廓的偏斜估计算法的启发,我们根据计数组件提出一种投影方法,以估计文本行的可能方向。假设文本块中文本行的方向是θ,垂直坐标偏移是h,我们可以在文本块上画一条线(绿色或红色线如图6(b)所示)。并且计数分量Φ(θ,h)的值等于线路所经过的字符分量的数量。由于右方向的元件数通常具有最大值,如果我们对所有方向上的计数分量的峰值进行统计,则可以容易地找到可能的方向θr(图6(a))。通过这种方式,θr可以很容易地计算如下:

其中Φ(θ,h)表示当方向为θ且垂直坐标偏移为h时的分量数。
文本行候选生成
与基于组件的方法[16,4,6]不同,在我们的方法中生成文本行候选的过程不需要在文本块的指导下捕获文本行中的所有字符。首先,我们将组件分成组。如果文本块α中的一对组件(A和B)满足以下条件,则它们被组合在一起:
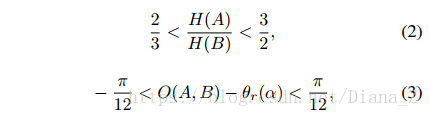
其中H(A)和H(B)代表A和B的高度,O(A,B)代表该对的方向,θr(α)是α的估计方向。
然后,对于一组β= {ci},ci是第i个组件,我们沿着θr(α)的方向绘制一条通过β的中心的线L。点集P定义为:
其中B(α)表示α的边界点。
最后,β的最小边界框bb作为文本行候选框被计算出来:
其中U表示包含所有点和组件的最小边界框。
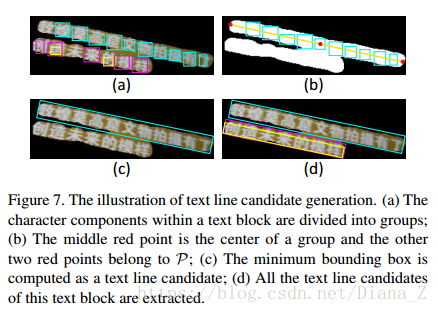
图7说明了这个过程。我们对每个文本块重复此过程以获得图像中的所有文本行候选。通过同时考虑两个水平线索,与基于组件的方法相比,我们的方法具有两个优点[16,4,6]。首先,在文本块的指导下,MSER组件不需要准确捕获所有字符。即使某些字符被MSER遗漏或部分检测到,文本行候选的生成也不会受到影响(例如图7中的三个候选者)。其次,自然场景中多方向文本检测的先前作品[29,9,32]通常使用一些脆弱的聚类/分组算法进行基于角色等级的文本方向估计。这种方法对缺失字符和非文本噪声很敏感。我们的方法通过使用投影方法从整体轮廓估计方向,该方法比基于字符聚类/分组的方法更有效和更健壮。
3.3. 文本行候选分类
在最后阶段(第3.2节)生成的候选项的一小部分是非文本或冗余。为了删除错误的候选者,我们基于文本行候选的字符质心提出两个标准。为了预测角色质心,我们采用了另一种名为Character-Centroid FCN的FCN模型。
Character-Centroid FCN
Character-Centroid FCN继承自Text-Block FCN(第3.1节),但仅使用前3个卷积阶段。与TextBlock FCN相同,每个阶段后跟一个1×1卷积层和一个上采样层。全连接的层也用1×1卷积层和sigmoid层代替。该网络也使用交叉熵损失函数进行训练。通常,Character-Centroid FCN是Text-Block FCN的小版本。

图8中示出了几个示例以及地面实况图。地面实况图的正区域由与角色质心的距离小于15%的相应字符高度的像素组成。在测试阶段,我们首先可以获得文本行候选的质心概率图。然后,收集地图上的极值点E = {(ei,si)}作为质心,其中ei表示第i个极值点,并且si表示ei定义在上的概率图的值的分数。图9中显示了几个例子。为了去除错误的候选者,在获得质心之后,采用两个基于强度和几何特性的直观而有效的标准:
强度标准
对于文本行候选,如果字符质心的数量nc <2,或者质心的平均得分Savg <0.6,我们将其视为假文本行候选。质心的平均分数定义为:

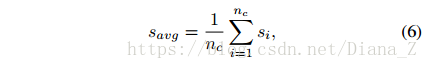
几何标准
文本行候选框内的字符的排列总是近似为直线。 我们采用方位角μ的平均值和质心之间的方位角的标准偏差σ来表征这些属性。 μ和σ定义为:
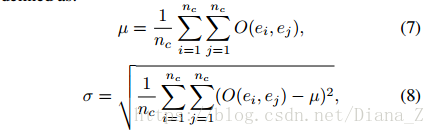
其中O(ei,ej)表示ei和ej之间的方位角。 在实践中,我们仅保留μ<π/32且σ<π/16的候选框。
通过上述两个约束,排除了假文本行候选,但仍然存在一些冗余候选。 为了进一步去除冗余候选者,对剩余候选者应用标准非最大抑制,并且将非最大抑制中使用的分数定义为所有质心的分数之和。
4.实验
为了将提出的方法与竞争方法进行全面比较,我们在几个最近的标准基准上评估了我们的方法:ICDAR2013,ICDAR2015和MSRATD500。
代码: