原创不易,转载前请注明博主的链接地址:Blessy_Zhu https://blog.csdn.net/weixin_42555080
本次代码的环境:
运行平台: Windows
Python版本: Python3.x
IDE: PyCharm
一、 前言
在概率引入到机器学习之后,就可以从两个角度:频率角度和贝叶斯角度来讨论问题。其中频率派逐渐发展为统计机器学习;贝叶斯派逐渐发展为概率图模型。今天介绍的Linear Regrssion线性回归分析,在统计机器学习中占据了核心地位,为什么呢?因为它是最基础、最简单的统计机器学习模型。结合下面的图1所示:

图1
由上图Linear Regression的性质有:
- 线性:
- 属性线性:可以理解为,x是p维特征,f关于x是线性的
- 全局线性:可以理解为,f(w,b) = wx+b这样的线性组合的结果直接输出了,并没有作为一个中间结果,作为下一部分的输入。而线性分类是打破了LR的全局分线性这个内容,它是将LR的结果作为下一激活函数的输入,并不是直接输出结果。
- 系数线性:f关于w是线性的。
- 全局性:全局线性指的是LR是否是直接你和为一条直线,而不是分段拟合后,再合并为一条直线。如下图所示,黑色表示LR直接拟合出来这直线,而红色表示需要分为几个阶段,然后分阶段拟合后,再合并。
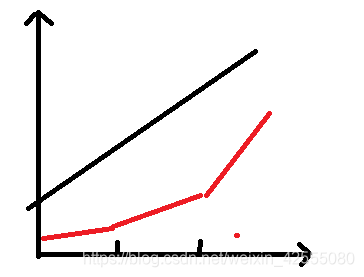
- 数据未加工:指的是,拿到数据之后,直接进行用于拟合,而不是需要继续进行其他操作,如降维等操作。
在这些性质的基础上,如果打破任何一个性质的特点,就会出现一种新的分类方式。比如图1所示的内容,如果打破LR系数线性这个性质,就会变成一种新的分类方式:神经网络
既然LR这么重要,接下来就开始学习一下,LR的基础内容。
二、 线性回归内容介绍
线性回归(Linear Regression)是一种通过属性的线性组合来进行预测的线性模型,其目的是找到一条直线或者一个平面或者更高维的超平面,使得预测值与真实值之间的误差最小化。

- 优点:结果具有很好的可解释性(w直观表达了各属性在预测中的重要性),计算熵不复杂。
- 缺点:对非线性数据拟合不好
- 适用数据类型:数值型和标称型数据
对于线性回归,可以通过几何意义的矩阵表达,这里使用的是最小二乘法LSM(least square method),进行拟合;也可以从概率角度来表达,这里使用的是MLE(maximum likelihood estimation)极大似然估计来拟合;最后介绍正则化,L1和L2:使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。接下来分别进行介绍:
2.1 LSM
假设特征和结果都满足线性。即不大于一次方。这个是针对 收集的数据而言。
收集的数据中,每一个分量,就可以看做一个特征数据。每个特征至少对应一个未知的参数。这样就形成了一个线性模型函数,向量表示形式:
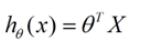
这个就是一个组合问题,已知一些数据,如何求里面的未知参数,给出一个最优解。 一个线性矩阵方程,直接求解,很可能无法直接求解。有唯一解的数据集,微乎其微。
基本上都是解不存在的超定方程组。因此,需要退一步,将参数求解问题,转化为求最小误差问题,求出一个最接近的解,这就是一个松弛求解。
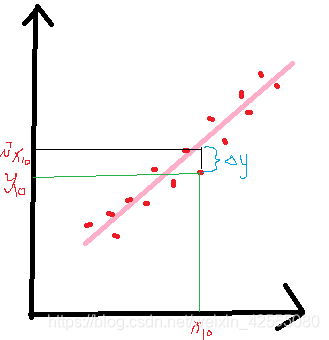
求一个最接近解,直观上,就能想到,误差最小的表达形式。仍然是一个含未知参数的线性模型,一堆观测数据,其模型与数据的误差最小的形式,模型与数据差的平方和最小,如下图所示:
线性回归模型属于监督学习,其训练数据集的形式为
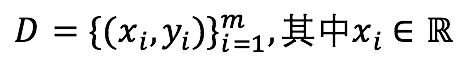
线性模型函数,向量表示形式:
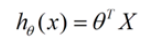

这样,由最小二乘法求得的内容就是

同时为了,便于计算,这里求出来了w值得向量表示。
2.2 MLE
但是,最小二乘法估计的几何意义,只有在非常幸运的情况下,即只有当几个样本点处在同一个直线上,拟合的这条直线误差正好为零。但是现实,是没有意义的,因为数据时具有随机性,也就是说,数据一定会有噪声。
现在假设,噪声是服从高斯分布,均值是零。

这样,可以得出结论是,LSE实际上是等价于MLE(当噪声是服从高斯分布的)。

2.3 正则化-岭回归
正则化引入的原因:
线性回归的Loss Function

的出来的w计算式子为:
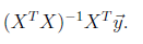
但是,这里面的
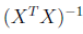
这个内容不一定逆。比如,Xnxp,当N>>p时,在数学上是不可逆的。
这样的形式,是容易过拟合的。实际上,正则化引入的最主要的原因就是防止数据过拟合。一般解决的办法就是:
- 添加数据
- 特征选择|特征提取
- 正则化。
这次使用的是正则化,正则化一般形式为:

在机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作 ℓ1-norm 和 ℓ2-norm,中文称作 L1正则化 和 L2正则化,或者 L1范数 和 L2范数。
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
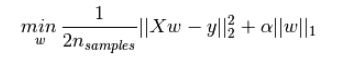
是Lasso回归的损失函数,式中加号后面一项α∣∣w∣∣1 即为L1正则化项。
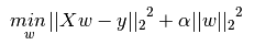
Ridge回归的损失函数,式中加号后面一项
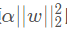
即为L2正则化项。
以下是,正则化-岭回归解决数据过拟合的过程:

岭回归,最终通过添加一个带系数的单位矩阵,使得通过几何意义得到的w值可以通过矩阵计算。
2.4 正则化-MAP概率视角
下面使用贝叶斯角度的最大后验估计MAP,通过概率视角验证正则化的框架是否可以通过和几何视角的验证殊途同归。

可以看到,最终MAP得到的内容正是LSE(最小二乘法)假设的框架是一致的。结论就是:
常规最小二乘法得到的正则化式 等价于 噪声为高斯分布,先验也为高斯分布的最大后验估计的形式。这样就可以验证,概率派的统计机器学习和贝叶斯派的概率图模型是殊途同归的。
三、 结论
本篇内容主要介绍了线性回归方程,以及回归方程的验证,最后涉及到了正则化的内容这篇文章就到这里了,欢迎大佬们多批评指正,也欢迎大家积极评论多多交流。

参考文章:
1 机器学习中正则化项L1和L2的直观理解
2 程序员的机器学习笔记-第三篇 线性回归
3 【机器学习】线性回归原理推导与算法描述
4 线性回归详解
5 对线性回归、逻辑回归、各种回归的概念学习
6 用Excel做回归分析的详细步骤