版权声明:转载请声明转自Juanlyjack https://blog.csdn.net/m0_38088359/article/details/83759163
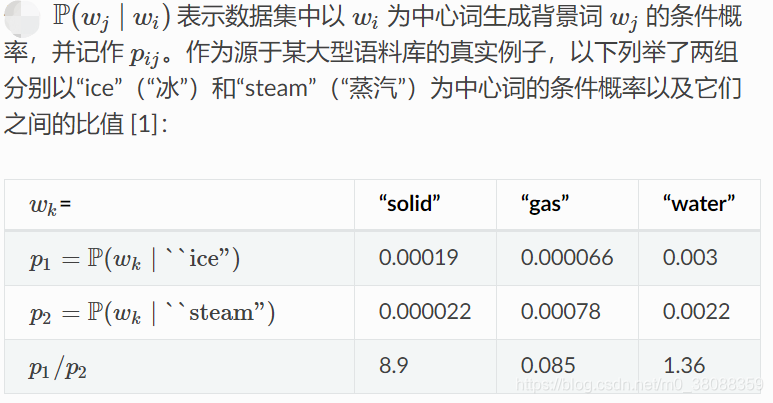
从条件概率比值理解GloVe



此处注意,在GloVe中的损失函数还添加了每个损失项的权重。
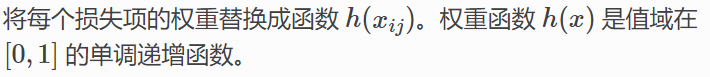
如此一来,GloVe 的目标是最小化损失函数:


原论文作者使用中心词和背景词学习到的向量相加得出该词的最终词向量,在原论文中有作者此举的解释。不管如何,从直观上看,哪怕最终训练得出的两个向量不同,相加之后即可忽略不同,也即可以减少向量初始化对模型训练结果的影响。
小结:
(1)在有些情况下,交叉熵损失函数有劣势。GloVe 采用了平方损失,并通过词向量拟合预先基于整个数据集计算得到的全局统计信息。
(2)任意词的中心词向量和背景词向量在 GloVe 中是等价的。
学习自此处