Glove模型
模型目标:进行词的向量化表示,使得向量之间尽可能的蕴含语义和语法的信息
Glove用词向量表达共现词频的对数
代价函数:
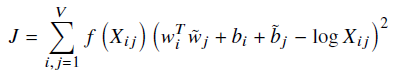
模型推导 (不是很严谨)
首先给予一些定义
共现词频Xi,j 表示若中心词为i,语境词j出现的次数,通俗一点就是说单词i和单词j在给定滑动窗口数时同时出现的次数
Xi表示单词出现的总次数
 表示单词k出现在单词i语境中的概率
表示单词k出现在单词i语境中的概率
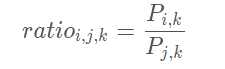 表示在中心词为i时,k出现概率与中心词为j时,k出现概率的比值,用来衡量相对性
表示在中心词为i时,k出现概率与中心词为j时,k出现概率的比值,用来衡量相对性
由于计算比值复杂度比较高(当然是数据量比较大的时候啦),所以想要找到一个F代替,即使得

由于向量空间本质上是线性结构,因此最自然的方法是使用向量差。这样,我们就可以把注意力限制在那些只依赖于两个目标词的差异的函数f上。
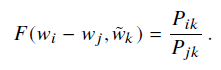
上式左边是向量,而右边则是标量,会使我们试图捕捉的线性结构变得模糊,为了避免这个问题我们对参数取点积得到

通过Pi,k的表达式可转换得到
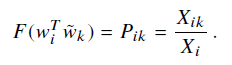
取F(x) = exp(x) ,左右两边同时取log,可得到
![]()
同时我们应该考虑到对称性(单词i单词j出现的次数和单词j单词i出现的次数理应是一样的) ,故将log(xi)表示为bi,b~k
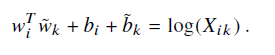
我们的目标就是二者间最小,考虑到最常用的衡量方式便是均方误差,同时考虑到出现频率越高词权重越大的原则,加上权重项可得代价函数
其中权重函数为

经过实验对比,通常取alpha为0.75,Xmax为100,此权重公式可以将过,出现频率过大的权重给拉低,同时使得出现频率为0的权重项也为0,不计入loss function中,f(x)的图形如下。

其实这个代价函数转变的形式比较随意,是根据我们想要的方便的形式转变的,为了方便我们训练,但是无论怎么变形,我们的最终目的就是训练得到单词向量的两个表达W和W~。
这两个向量理应相等,但是可能由于初始化的愿意使两个向量间有略微差别,并且有证据表明,对于某些类型的神经网络,
训练网络的多个实例,然后将结果结合起来,有助于减少过拟合和噪音,通常会提高结果,所以我们将两个向量相加最为我们最终训练得到的词向量
参考论文:GloVe: Global Vectors forWord Representation
