版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_37947156/article/details/83145778
准备语料
准备好自己的语料,保存为txt,每行一个句子或一段话,注意要分好词。
准备源码

从GitHub下载代码,https://github.com/stanfordnlp/GloVe
将语料corpus.txt放入到Glove的主文件夹下。
修改bash
打开demo.sh,修改相应的内容
因为demo默认是下载网上的语料来训练的,因此如果要训练自己的语料,需要注释掉
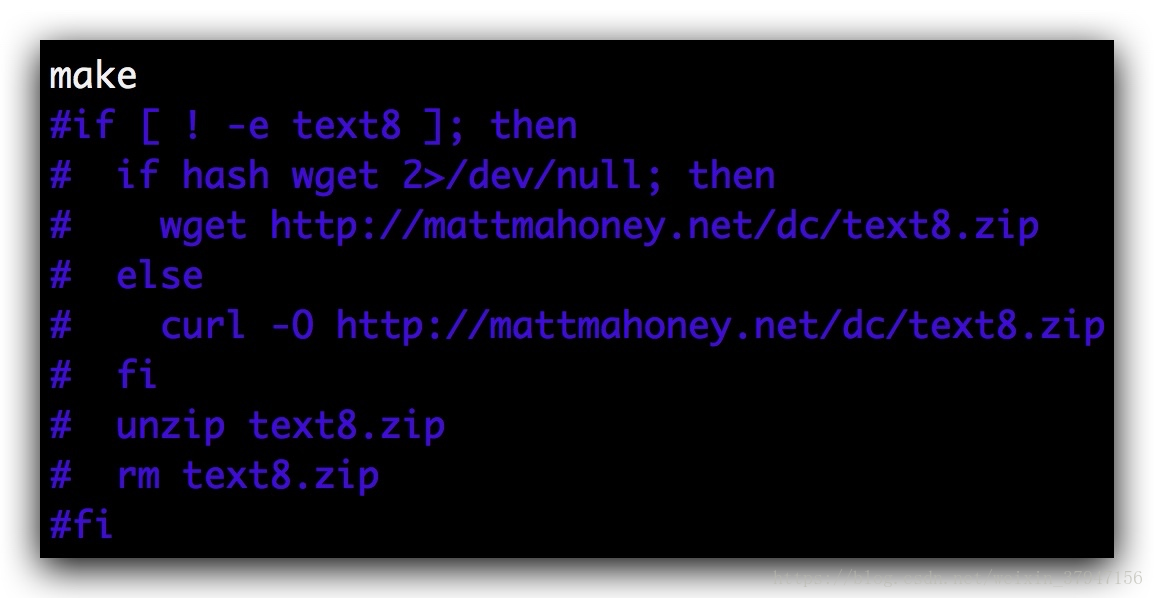
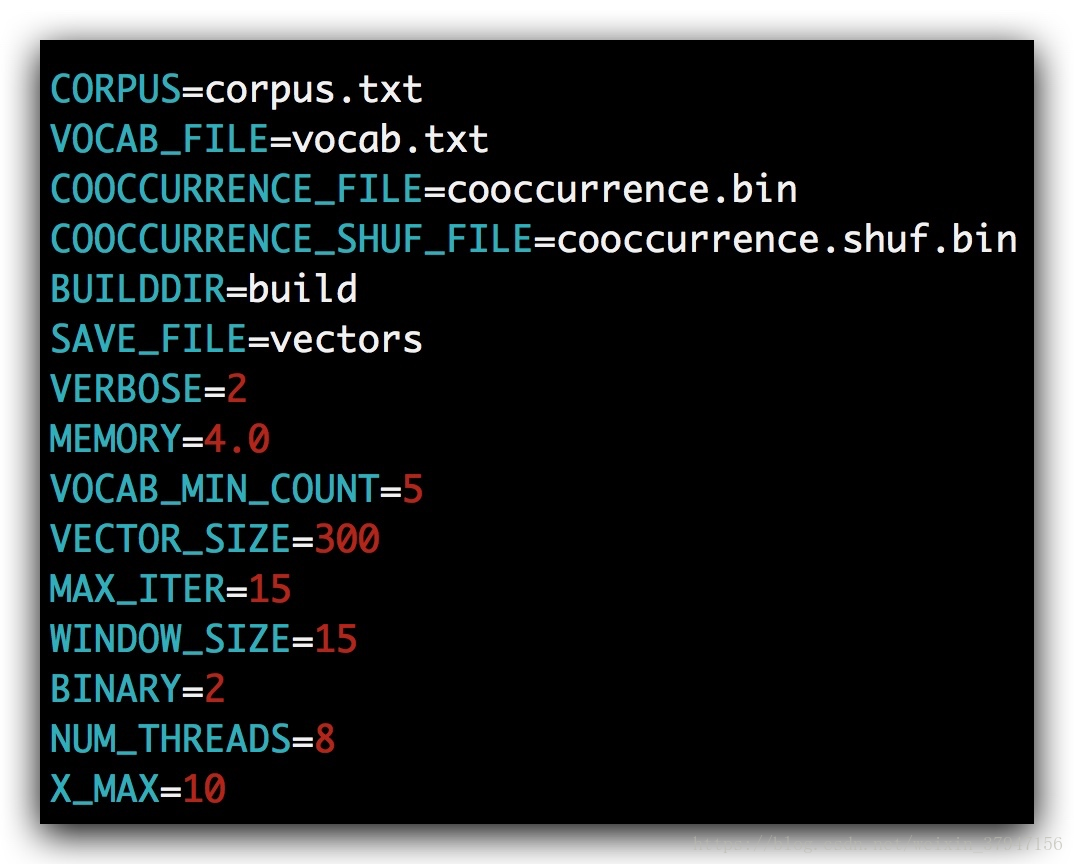
修改参数设置,将CORPUS设置成语料的名字
执行bash文件
进入到主文件夹下
make
bash demo.sh

注意,如果训练数据较大,则训练时间较长,那么建议使用nohup来运行程序
1
nohup bash demo.sh >output.txt 2>&1 &
坐等训练,最后会得到vectors.txt 以及其他的相应的文件。如果要用gensim的word2ve load进来,那么需要在vectors.txt的第一行加上vacob_size vector_size,第一个数指明一共有多少个向量,第二个数指明每个向量有多少维。
参考