GloVe是一种用于获取词汇向量表示的无监督学习算法。 对来自语料库的聚合全局字词同现统计进行训练,并且所得到的表示展示了词向量空间的有趣的线性子结构。
官网主页地址:https://nlp.stanford.edu/projects/glove/
Github:https://github.com/stanfordnlp/GloVe
论文下载地址:https://nlp.stanford.edu/pubs/glove.pdf
gloVe词向量格式
GloVe是Word embedding(词嵌入)的一种,通过斯坦福开源的代码训练出来GloVe词向量和word2vec的格式有点不同。word2vec训练出来的模型第一行有:词库大小和维度,而gloVe并没有
Word2vec训练出来格式:
Size Dimension
Word1 vector1
Word2 vector1
….
WordN vectorN
GloVe 训练出来格式:
Word1 vector1
Word2 vector1
….
Wordn vector
所以,我们使用Glove训练出来的模型在前面加上一行Vocabulary Size,模型的使用方法就和word2vec一样了。官网上提供了很多使用词库训练得到的词向量模型,可以下载下来直接用。

源码解析
eval是用来评价训练好的词向量模型的.src是四个过程的源码:- vocab_count:计算原词库的单词统计(生成的vocab.txt,每行为:单词 词频)
- cooccur:统计词与词的共现(生成cooccurrence.bin)
- shuffle:对2的共现结果重新整理(生成cooccurrence.shuf.bin)
- glove: glove算法训练模型
demo.sh主要做了这几步事情:下载text8并且解压
把解压之后的text8用于训练模型,输出vectors.txt和vectors.bin模型 ,前者是文本文件,后者是二进制文件
调用eval里面的函数进行评价
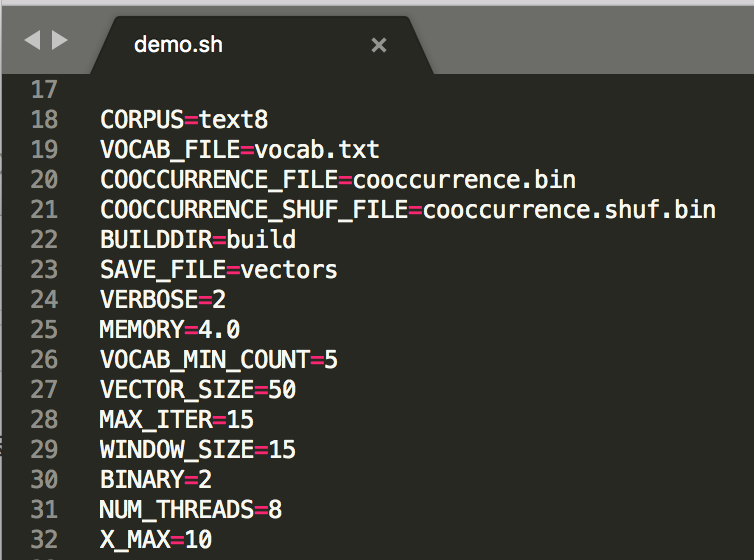
可以修改demo.sh的源码,进行训练词向量模型:
CORPUS=text8 //把这里换成自己的词典 VOCAB_FILE=vocab.txt //得到的词 词频文件 COOCCURRENCE_FILE=cooccurrence.bin COOCCURRENCE_SHUF_FILE=cooccurrence.shuf.bin BUILDDIR=build SAVE_FILE=vectors //保存为词向量的名字 VERBOSE=2 MEMORY=4.0 VOCAB_MIN_COUNT=5 VECTOR_SIZE=50 //词向量维度 MAX_ITER=15 //训练迭代次数 WINDOW_SIZE=15 //上下文窗口大小 BINARY=2 //保存文件类型 NUM_THREADS=8 //线程数 X_MAX=10