来源:Coursera吴恩达深度学习课程
这篇文章介绍的算法是GloVe算法,虽然不如Word2Vec或是Skip-Gram模型用的多,但是很是简便(its simplicity)。

Glove算法是参考Jeffrey Pennington,Richard Socher和Chris Manning发明的论文Glove: Global Vectors for Word Representation。
GloVe指用词表示的全局变量(global vectors for word representation)。之前,我们列举过上下文和目标词词对,GloVe算法就是使其关系开始明确化。假定X_ij表示单词i在单词j上下文中出现的次数,那么i和j与t和c的功能一样,所以X_ij等同于X_tc。事实上,如果你将上下文和目标词的范围定义为出现于左右各10词以内的话,有一种对称关系(symmetric relationship)。如果你选择的上下文总是目标词前一个单词的话,那么X_ij和X_ji就不对称。不过对于GloVe算法,我们可以定义上下文和目标词为任意两个位置相近的单词,假设是左右各10词的距离,那么X_ij就是一个能够获取单词i和单词j出现位置相近时或是彼此接近的频率的计数器。
GloVe模型就是进行优化,下面具体来看看。

我们将他们之间的差距进行最小化处理:
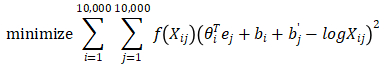
我们想要知道的是这两个单词之间有多少联系,他们同时出现的频率,这是由这个X_ij影响的。然后,我们要做的是解决参数θ和e的问题,可用梯度下降来最小化上面的公式,只需要学习一些向量,这样他们的输出能够对这两个单词同时出现的频率进行良好的预测。
如果X_ij是等于0的话,那么log0是负无穷大的,于是约定0log0=0。上面的求和公式表明,这个和仅是一个上下文和目标词关系里连续出现至少一次的词对的和。
f(X_ij)的另一个作用是加权,有些词在英语里词频较高,比如说this,of,a等等,但是在频繁词和不常用词之间也会有一个连续统(continuum)。不过也有一些不常用的词,我们还是想将其考虑在内,但又不像那些常用词这样频繁。
因此,f(X_ij)就可以是一个加权因子,对于不常用的词同样给大量有意义的运算,同时不会给在英语里出现更频繁的词过分大的权重。因此有一些对加权函数f的选择有着启发性的原则(heuristics),就是既不给词频高的词过分的权重,也不给这些不常用词(durion)太小的权值。如果想知道f是怎么能够启发性地完成这个功能的话,可以看一下GloVe算法论文。
最后,一件有关这个算法有趣的事是θ和e现在是完全对称的(completely symmetric),所以θ_i和e_j就是对称的。如果只看数学式的话,θ_i和e_j的功能很相近,我们可以将它们颠倒或者排序,实际上他们都输出了最佳结果。因此一种训练算法的方法是一致地初始化θ和e,然后使用梯度下降法来最小化输出,当每个词都处理完之后取平均值(mean),因为θ和e在这个特定的公式里是对称的(symmetric),所以给定一个词w,有
![]()
这就是GloVe算法的内容。仅仅是最小化,像这样的一个二次代价函数是怎么能够让你学习有意义的词嵌入的呢?但是结果证明它确实有效。
在我们总结词嵌入学习算法之前,有一件更优先的事(one more property)。

如上图,以这个特制的表格(featurization view)作为例子来开始学习词向量。前四行的嵌入向量分别来表示Gender、Royal、Age和Food。但是当你在使用我们了解过的算法的一种来学习一个词嵌入时,例如我们之前的幻灯片里提到的GloVe算法,会发生一件事就是你不能保证嵌入向量的独立组成部分是能够理解的,为什么呢?
假设说有个空间,里面的第一个轴(上图红色标记1)是Gender,第二个轴(上图红色标记2)是Royal,你能够保证的是第一个嵌入向量对应的轴(上图红色标记3)是和这个轴(红色标记1,2所示)有联系的,它的意思可能是Gender、Royal、Age和Food。具体而言,这个学习算法会选择这个(上图红色标记3)作为第一维的轴,所以给定一些上下文词,第一维可能是这个轴(上图红色标记3),第二维也许是这个(上图红色标记4),或者它可能不是正交的,它也可能是第二个非正交轴(上图红色标记5),它可以是你学习到的词嵌入中的第二部分。如果有某个可逆矩阵A,因为我们将其展开:
![]()
如果没有学过线性代数(linear algebra)的话,也没关系。你不能保证这些用来表示特征的轴能够等同于人类可能简单理解的轴,具体而言,第一个特征可能是个多个属性的组合,所以很难看出独立组成部分,然后解释出它的意思。尽管有这种类型的线性变换,这个平行四边形映射(parallelogram map)也说明了我们解决了这个问题,当你在类比其他问题时,该方法也是可以的。
这就是GloVe 词向量的内容,我们现在已经了解了一些学习词嵌入的算法。
说明:记录学习笔记,如果错误欢迎指正!转载请联系我。