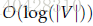- Word Vectors
将单词编码成向量,将其表示成在词空间中的某一点。每一维都可看作是某些语义信息的编码。
- one-hot vector:
最简单的词向量,将每个单词表示成一个 |V|*1维的向量。|V|是词表大小,其在词表中的索引位置值为1,其余为0。
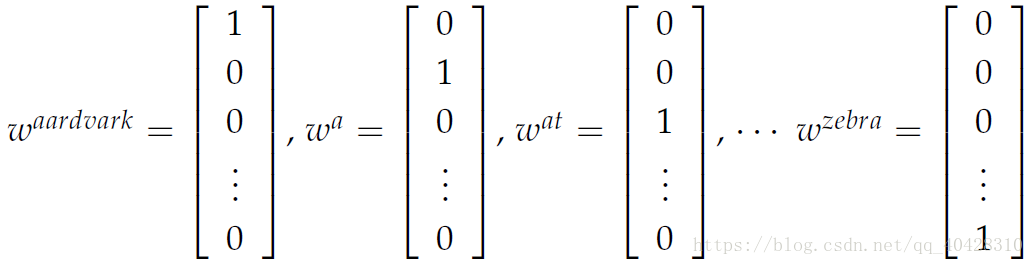
但由于词表中单词巨多,所以one-hot vector维度过高;此外,任意两个vector点乘值为零,所以词向量之间彼此独立,不能寓含词间的相似性信息。
- SVD奇异值分解:
1.生成词的共现矩阵X(Word-Document Co-occurrence Matrix,Word-Word Co-occurrence Matrix)
2.分解X = USV^T
3.U的行就表示 the word embeddings
Word-Document Co-occurrence Matrix:
矩阵第 i 行第 j 列表示,单词 i 在篇章 j 中是否出现,出现为 1,否则为 0。所以共现矩阵的维度是|V|*num(docs),即单词总数*篇章总数,无疑是一个很大的矩阵。
Word-Word Co-occurrence Matrix:
表示两个单词同时出现的次数,设置一个窗口window,只有在window内的两个单词才算作共现。举例如下,window size = 1,语料库包含以下三个句子:

接下来对共现矩阵进行SVD分解( 点击打开链接)

通过选取前k维来降维
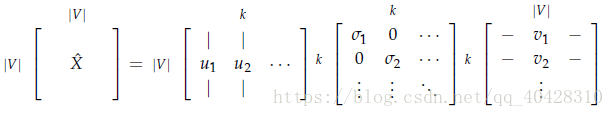
由此生成的词向量包含了丰富的语法语义信息在里面,但却存在很多其他的问题:
由于新词的频繁加入,矩阵的维度也要随之变化
- 矩阵稀疏
- 矩阵维度高
- SVD分解计算量大
- 词语出现频率严重不平衡
- word2vec:
是google开源的词向量计算模型。基于一个非常重要的语言学假设distributional similarity,即相似的词语有相似的上下文语境。 包括两个浅层神经网络算法:continues bag-of-word CBOW、Skip-gram和两个训练模型:negative sampling负采样、hierarchical softmax 。
- CBOW: 输入上下文矩阵context,预测中间词center word 。
比如对于句子:The cat jumped over the puddle.
input context 为 "The","cat","over","the","puddle"
output center word 为 "jumped"
作为神经网络模型的已知参数:
input:x(c),one-hot vectors—context
output:y(c) ,one-hot vector—center word
待求的未知参数为两个矩阵
和
其中,n 自定义大小表示 embedding space,V 表示 vocabulary,|V|则为单词总数
的第 i 列表示单词 wi 的 词向量embedded vector , 记作 vi
的第 j 行表示单词 wj 的 词向量embedded vector,记作uj
实际上学习了每个词的两个向量u和v
模型的计算过程如下:
1. 产生context的one-hot vectors
2. 用矩阵
3. 对embedded word vectors求平均值,可看作是对上下文单词的特征求均值
4. 计算得分矩阵score vector
因为两个向量dot product点乘,所得的值越大表示这两个词向量越相似。所以在score vector z 中值越大则说明对应的单词与context vectors的特征均值越相似,是center word的可能性越大。
5. 将score转换为概率值
6. 通过将我们计算出的概率矩阵
和 实际的进行学习
设置目标函数
用随机梯度下降法迭代更新求解
CBOW模型网络结构图
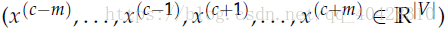
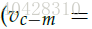
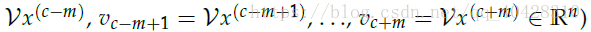
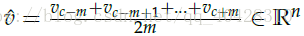
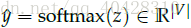
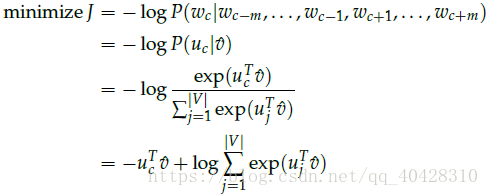
- Skip-gram:输入中间词center word,预测上下文矩阵context概率分布 。
input:x(c) ,one-hot vector—center word
output:y(c),one-hot vectors—context
两个矩阵
和CBOW相同
模型的计算过程如下:
1.输入center word :
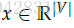
2.生成embedded vector :
3.计算score vector :
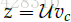
4.
5.在生成目标函数时需要用到朴素贝叶斯,给定center word假设context中的单词是相互独立的
Skip-gram模型网络结构图
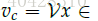
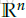

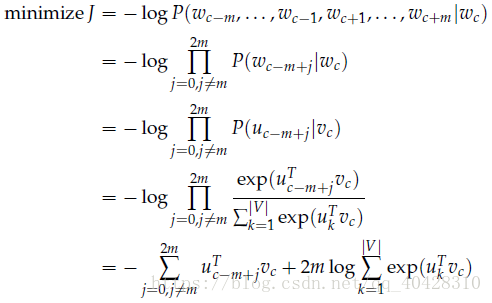
- Negative Sampling负采样
在计算损失函数J时,由于需要对softmax正则化,将|V|个score进行累加,计算量巨大,所以需要简化计算,进行近似估计。
Negative Sampling是通过对几个负样本进行采样来取代遍历整个vocabulary。
通过一元分布“Unigram distribution”的 3/4 次方来进行选取负样本。
表示word 和 context
表示 word 和 context 是语料库中的数据,相反
表示不是语料库中的数据
用sigmoid函数取代softmax
新的目标函数为
这里的
指
和
,
指非语料库
上式极大似然概率等价于如下最小化损失函数
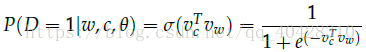
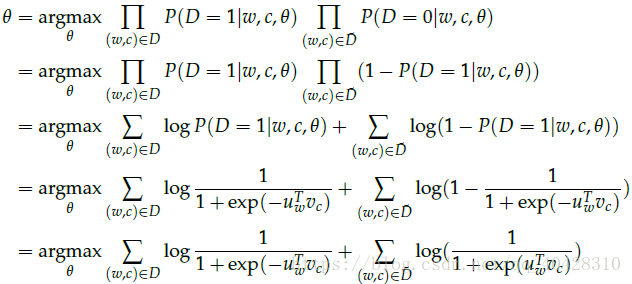
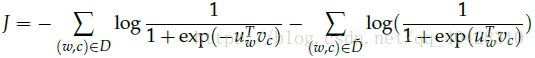
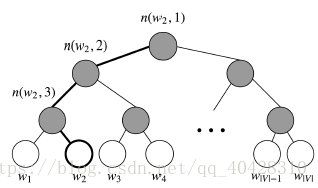
- Hierarchical Softmax
比普通的Softmax更高效,使用哈夫曼树来表示词表中的单词,使得越常见的单词编码长度越短。主要优势在于将计算成本降到了
每个叶子节点表示一个单词
表示从 root 到 w 路径中的节点数
表示从 root 到 w 路径中第 i 个节点的词向量
表示节点 n 的左孩子
目标函数变成了使w = 正确单词 的路径概率最大