版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u013555719/article/details/82193049
5.2自然语言处理
觉得有用的话,欢迎一起讨论相互学习~Follow Me
2.8 GloVe word vectors GloVe词向量
Pennington J, Socher R, Manning C. Glove: Global Vectors for Word Representation[C]// Conference on Empirical Methods in Natural Language Processing. 2014:1532-1543.
- 示例 I want a glass of orange juice to go along with my cereal
- 定义
表示单词i在单词j上下文中出现的次数。其中i相当于Context,而j相当于Target.
- 当定义目标单词出现在上下文单词的左或右十个单词数时,此时i和j是一种对称的关系。即有
- 因此根据此定义,得知 就是一个能够获取单词i和单词j出现位置相近时或彼此接近是的频率的计数器
- 目的 Glove算法的目的就是优化

- 此式中 和负采样中的式子 意义相同
- 为了解决 可能为0的问题(因为 )的值为负无穷,引进了 使得当 ,并且会使用规定 .
- 并且 ,引入的 可以解决有些词语例如 this, is, of, a… 等词语出现频率过高而有些名词出现频率过低导致的不平衡问题–即 相当于一个加权因子,对于不常用的词汇也能给予大量有意义的运算,而对于出现频率过高的词汇更大而不至于过分的权重。 对于此函数的具体细节,参考标题下的参考论文。
- Note 现在是完全对称的,因此一种训练参数的方法是 一致的初始化 和e 然后使用梯度下降来最小化输出,当每个词都处理完了之后取平均值。 即
词嵌入向量解释
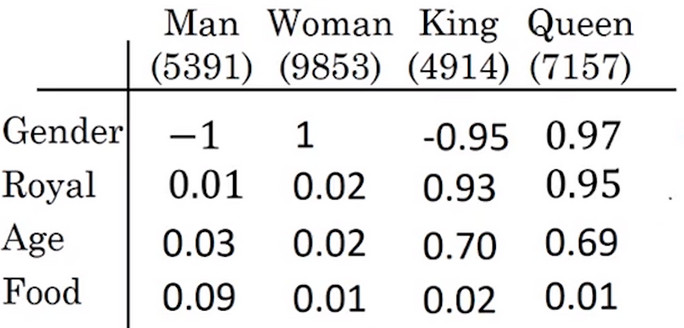
- 因为即使每行表示单词向量独特的特征,但是对于学习到的 词嵌入矩阵 其每行表示的意义不一定是 正交的 ,而是多行特征的线性表征。例如定义的第一行表示Gender,第二行表示Royal,第三行表示Age,第四行表示Food,但是实际学到的是这些特征的 使用平行四边形方法得到的线性表出 所以单独理解学到的 词嵌入矩阵 是十分困难的。