堆排序
堆
什么是堆?
堆和栈是计算机的两种最基本的数据结构。
堆的特点就是FIFO(first in first out)先进先出,这里的话我觉得可以理解成树的结构。
堆在接收数据的时候先接收的数据会被先弹出。
栈的特性正好与堆相反,是属于FILO(first in/last out)先进后出的类型。
栈处于一级缓存而堆处于二级缓存中。这个不是本文重点所以不做过多展开。
堆(定义):(二叉)堆数据结构是一个数组对象,可以视为一棵完全二叉树。如果根结点的值大于(小于)其它所有结点,并且它的左右子树也满足这样的性质,那么这个堆就是大(小)根堆。
大致的排序过程如下:
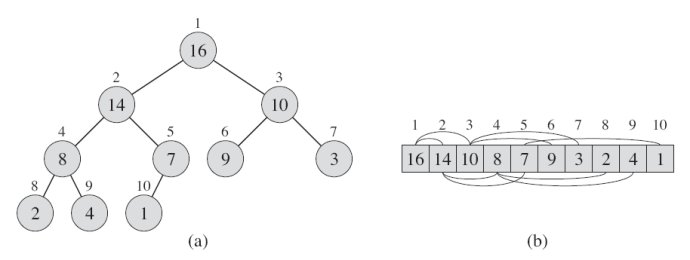
堆排序节点访问
在这里我们借用wiki的定义来说明:
通常堆是通过一维数组来实现的。在阵列起始位置为0的情况中
- 父节点i的左子节点在位置(2*i+1);
- 父节点i的右子节点在位置(2*i+2);
- 子节点i的父节点在位置(i-1)//2;
堆排序操作的意义
堆可以分为大根堆和小根堆,这里用大根堆的情况来定义操作:
(1)大根堆调整(max_heapify):
将堆的末端子节点作调整,使得子节点永远小于父节点。这是核心步骤,在建堆和堆排序都会用到。
比较i的根节点和与其所对应i的孩子节点的值,当i根节点的值比左孩子节点的值要小的时候,就把i根节点和左孩子节点所对应的值交换,同理,就把i根节点和右孩子节点所对应的值交换。
然后再调用堆调整这个过程,可见这是一个递归的过程。
def max_heapify(heap,heapSize,root): # 调整列表中的元素并保证以root为根的堆是一个大根堆
'''
给定某个节点的下标root,这个节点的父节点、左子节点、右子节点的下标都可以被计算出来。
父节点:(root-1)//2
左子节点:2*root + 1
右子节点:2*root + 2 即:左子节点 + 1
'''
left = 2*root + 1
right = left + 1
larger = root
if left < heapSize and heap[larger] < heap[left]:
larger = left
if right < heapSize and heap[larger] < heap[right]:
larger = right
if larger != root: # 如果做了堆调整则larger的值等于左节点或者右节点的值,这个时候做堆调整操作
heap[larger], heap[root] = heap[root], heap[larger]
# 递归的对子树做调整
max_heapify(heap, heapSize, larger)
(2)建立大根堆(build_max_heap):
将堆中所有的数据重新排序。建堆的过程其实就是不断做大根堆调整的过程,从(heapSize -2)//2处开始调整,一直调整到第一个根节点。
def build_max_heap(heap): # 构造一个堆,将堆中所有数据重新排序
heapSize = len(heap)
for i in range((heapSize -2)//2,-1,-1): # 自底向上建堆
max_heapify(heap, heapSize, i)
(3)堆排序(heap_sort):
将根节点取出与最后一位做对调,并做最大堆调整的递归运算。堆排序是利用建堆和堆调整来进行的。
首先建堆,然后将堆的根节点选出与最后一个节点进行交换,然后将前面len(heap)-1个节点继续做堆调整,直到将所有的节点取出,对于有n个元素的一维数组我们只需要做n-1次操作。
import random
def heap_sort(heap): # 将根节点取出与最后一位做对调,对前面len-1个节点继续进行堆调整过程。
build_max_heap(heap)
# 调整后列表的第一个元素就是这个列表中最大的元素,将其与最后一个元素交换,然后将剩余的列表再递归的调整为最大堆
for i in range(len(heap)-1, -1, -1):
heap[0], heap[i] = heap[i], heap[0]
max_heapify(heap, i, 0)
# 测试
if __name__ == '__main__':
a = [30, 50, 57, 77, 62, 78, 94, 80, 84]
print(a)
heap_sort(a)
print(a)
b = [random.randint(1,1000) for i in range(1000)]
print(b)
heap_sort(b)
print(b)
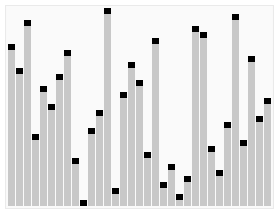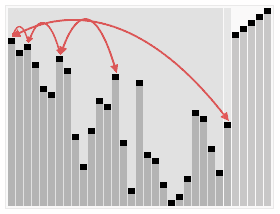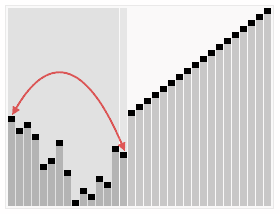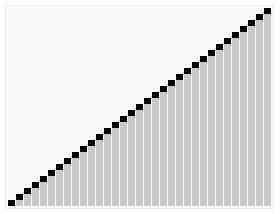
这里用网上的一张比较直观的图来展示一下堆排序的过程:
时间复杂度
堆排序的时间复杂度分为两个部分一个是建堆的时候所耗费的时间,一个是进行堆调整的时候所耗费的时间。而堆排序则是调用了建堆和堆调整。
刚刚在上面也提及到了,建堆是一个线性过程,从len/2-0一直调用堆调整的过程,相当于o(h1)+o(h2)+…+o(hlen/2)这里的h表示节点深度,len/2表示节点最大深度,对于求和过程,结果为线性的O(n) 。
堆调整为一个递归的过程,调整堆的过程时间复杂度与堆的深度有关系,相当于lgn的操作。
因为建堆的时间复杂度是O(n),调整堆的时间复杂度是O(lgn),所以堆排序的时间复杂度是O(nlgn)。