版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Wastematerial/article/details/82228539
在堆中,我们熟悉的有小顶堆、大顶堆。其是怎么定义呢,正如一颗二叉树的数据结构,大顶堆的定义是每一个根(节点)都会比它们的两个节点的值要大,二小顶堆,其恰恰是跟大顶堆相反。
我们已大顶堆为例:
堆排序的基本思想是:将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了。
首先是给无序序列构建一个初始的大顶堆:我们首先拿到的是这样的一个数组arr,
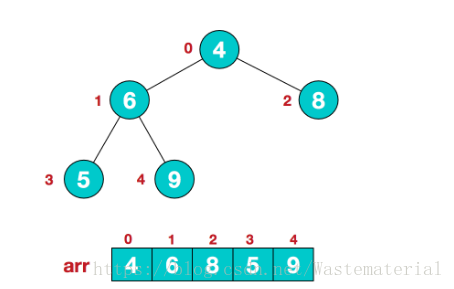
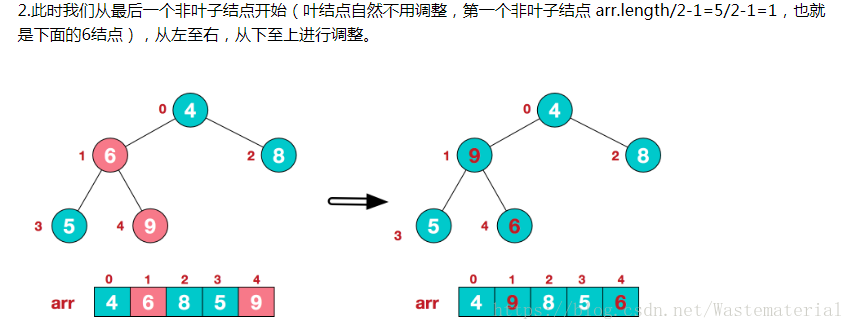
(第一个叶子节点,我们可以从二叉树的特性可知)
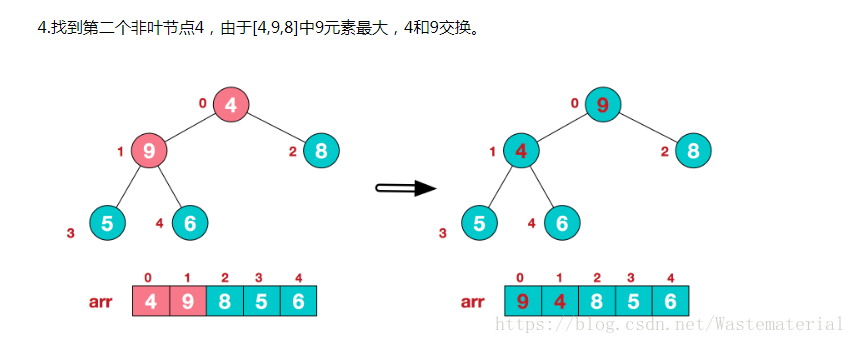
(此时在跟根节点调换之后,我们的子节点1 3 4 ,已经乱序了,这也是二叉树的调整思路,每次对子节点调换位置之后,都需要重新调整子树,这是二叉树一个比较重要的逻辑)
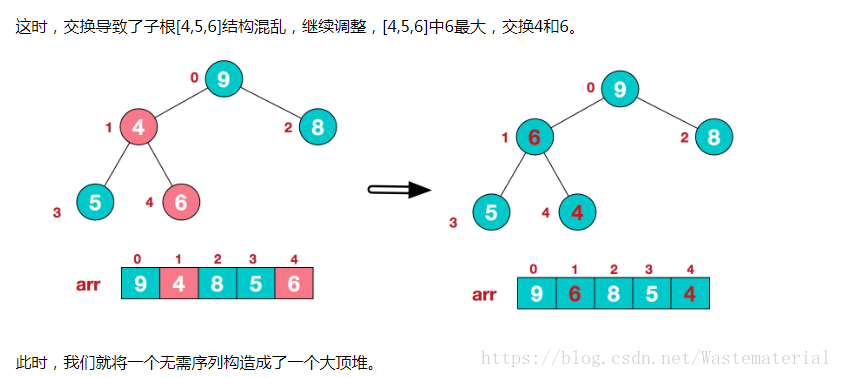
下面是一个初始堆的代码
package aobi.com.task;
import java.util.Arrays;
/**
* Created by bianca on 2018/8/30.
* 堆排序demo
*/
public class HeapSort {
public static void main(String []args){
int []arr = {7,5,9,4,6,2,3,1};
sort(arr);
System.out.println(Arrays.toString(arr));
}
public static void sort(int[] arr){
int n = arr.length;
for(int i = n/2-1;i>=0;i--){
adjustHeap(arr,i,arr.length);
}
}
public static void adjustHeap(int []arr,int index,int length){
int temp = arr[index];
for(int j = index*2+1;j<length;j++){
if(j+1<length && arr[j]<arr[j+1]){
j++;
}
if(arr[j]>temp){
arr[index] = arr[j];
index = j;
}else{
break;
}
}
arr[index]=temp;
}
}
这个步骤就不展示了,就是不断的调用上面的初始堆的方法。