python算法之堆排序
注意:本文中的结点和结点不加区分的使用
堆的概念:
- 堆是一个完全二叉树
- 每个非叶子结点都要大于或者等于其左右孩子结点的值称为大顶堆
- 每个非叶子结点都要小于或者等于其左右孩子结点的值称为小顶堆
- 根结点一定是大顶堆中的最大值,一定是小顶堆中的最小值
堆其实是从节点值来观察,结点值具有一点特点的完全二叉树
堆的类型
根据堆的特性,我们可以把堆分为两类
大顶堆
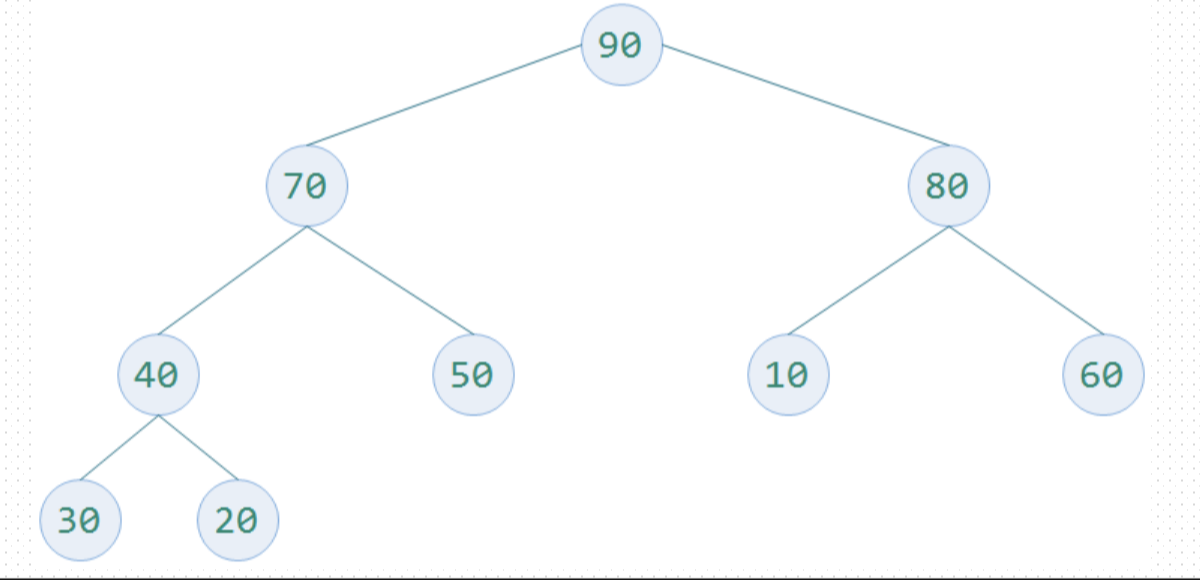
完全二叉树的每个非叶子结点都大于或者等于其左右孩子结点的值,根结点一定是大顶堆中的最大值,如图1
小顶堆
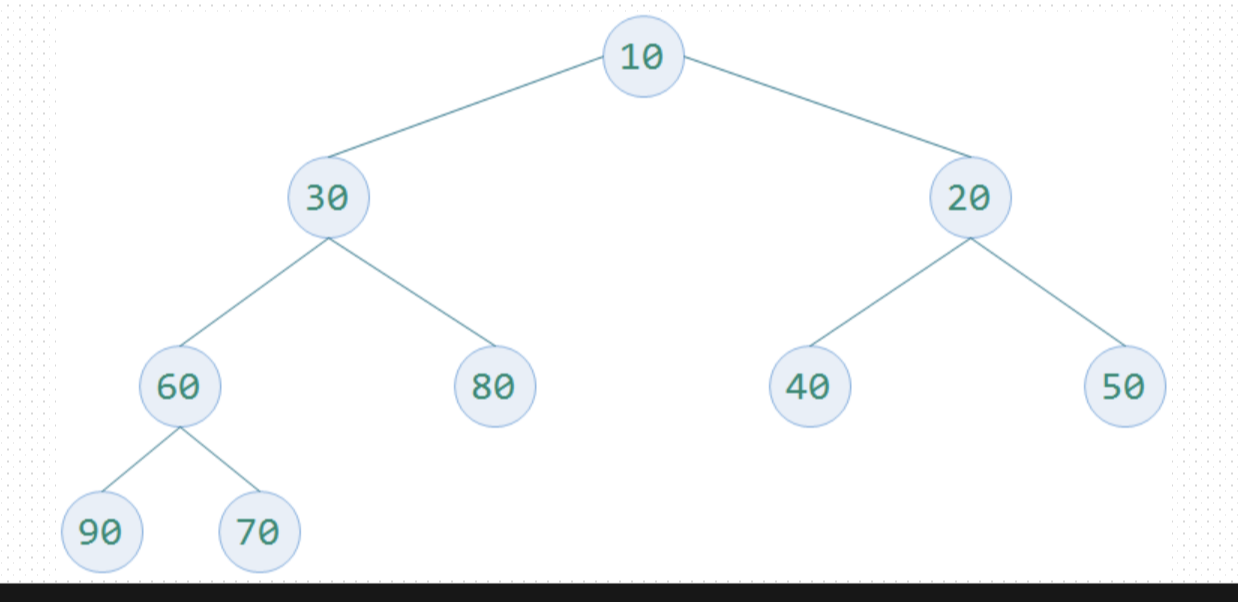
每个非叶子结点都要小于或者等于其左右孩子结点的值,根结点一定是大顶堆中的最小值,如图2
堆排序步骤
构建完全二叉树
原始数据:30,20,80,40,50,10,60,70,90
构建一个完全二叉树存放数据,并根据完全二叉树的性质5对元素编号,: 放入顺序的数据结构中构造一个列表为[0,30,20,80,40,50,10,60,70,90](插入一个0,是为了将数组的下标和完全二叉树的结点编号一致),如下图

构建大顶堆
怎么将一个队列构建成大顶堆(或者小顶堆),是堆排序的算法核心部分
分析
1.度数为2的结点A,如果他的左右孩子结点的最大值比它大的,最大值和该结点交换
2.度数为1的结点A,如果他的左孩子的值大于它,则交换
3.如果节点A被交换到新的位置(此时结点A已经是原来那个A的孩子结点了,所以需要A到了新的岗位上,是否能坐稳,还需要与其孩子结点比较),还需要和其他孩子结点重复上面的过程
1.构建大顶堆--起点结点的选择
从完全二叉树的最后一个结点的双亲结点开始,即最后一层的最右边叶子结点的父结点开始,如果结点数为n,则起始结点的编号为n//2,这也会保证每次比较过程中,到能将所有的数都比较得到(这个堆的起始位置就是9 // 2 = 4)

2.构建大顶堆--下一个结点的选择
从起始结点开始向左找其同层结点,到头后再从上一层的最右边结点开始继续向左逐个查找,直到根结点,如下图,进行的顺序是:4,3,2,1

3.大顶堆的目标
确保每个结点的值都比左右结点的值大
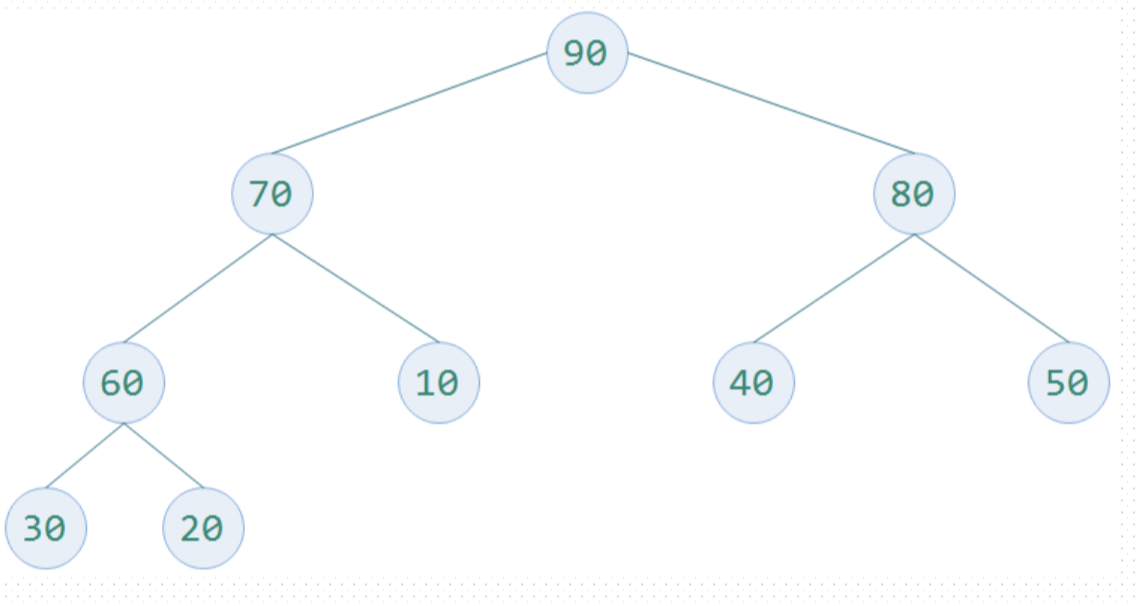
可以看一个更乱的图


排序
分析
1.将大顶堆根结点这个最大值和最后一个叶子结点交换,那么最后一个叶子结点就是最大值,将这个叶子结点排除在待排序结点之外
2.从根结点开始(新的根结点),重新调整为大顶堆后,重复上一步
问:排序,堆顶和最后一个结点交换,并排除最后一个结点,为什么要换最后一个呢?
答:堆顶的数据是已经确认了,这是最大(最小)值了,那就没必要在留在树中了,将其放置到最后一个叶子结点上,好标记。
总结
1.利用堆性质的一种选择排序,在堆顶选出最大值或者最小值(这也就是可以解决我们常见的TopN问题)
2.时间复杂度为O(nlogn)
3.空间复杂度:只是使用了一个交换用的空间,所以空间复杂度为O(1)
4.堆排序是一种不稳定的排序算法注意:由于堆排序对原始记录的排序状态并不敏感,因此它无论是最好、最坏,时间复杂度都是O(nlogn)
代码实现
#!/bin/env python
# -*- coding: utf-8 -*-
'''
__title__ = ''
__author__ = 'cxding'
__mtime__ = '2020/1/3'
# code is far away from bugs with the god
'''
import math
#居中打印 数量少的可以这么打印,多了就不行了
def print_tree(array,unit_width=2):
length = len(array)
depth = math.ceil(math.log2(length + 1))
index = 0
width = 2 ** depth -1 #行宽,最深的行 15个数
for i in range(depth):
for j in range(2 ** i):
#居中打印,后面追加一个空格
print('{:^{}}'.format(array[index],width * unit_width),end=' ' * unit_width)
index += 1
if index >= length:
break
width = width // 2 #居中打印宽度减半
print()
def sift(li:list,low:int,high:int):
'''
调整当前结点,这个时间复杂度最多是一棵树的高度,所以是logn
:param li: 列表
:param low: 堆的根结点位置
:param high: 堆的最后一个元素的位置
:return:
'''
i = low
j = 2 * i + 1 #j开始是左孩子
tmp = li[low] #把堆顶存起来
while j <= high: #只要j位置有数,没有超过堆的长度
if j + 1 <= high and li[j+1] > li[j]:
j = j + 1 # 如果有右孩子,并且他的值比左孩子大,将j指向右孩子
if li[j] > tmp:
li[i] = li[j]
i = j
j = 2 * i + 1
else:
li[i] = tmp
break
else:
li[i] = tmp
#return li
li = [10,40,50,30,20,90,70,80,60]
def heap(li):
'''
实现堆排序,这里面的时间复杂度是nlogn,所以最终的时间复杂度就是nlogn,但是这个速度会比快排慢
:param li: 待排序的列表
:return:
'''
#构建大顶堆
n = len(li)
print("原始的序列为:")
print_tree(li)
for i in range(n//2 - 1,-1,-1):
print('-' * 30)
sift(li,i,n-1)#high为n-1,其实是取了极大值
print_tree(li)
print("准备出数了!")
#挨个出数
for i in range(n-1,-1,-1):
#将第一个元素和堆的最后一个元素交换
li[0],li[i] = li[i],li[0]
sift(li,0,i -1)#将最后一个元素排除在外,只需要调整堆顶的元素就是一个大顶堆了
print('-'*30)
print_tree(li)
heap(li)
再一种写法:
#!/bin/env python
# -*- coding: utf-8 -*-
'''
__title__ = ''
__author__ = 'cxding'
__mtime__ = '2020/1/13'
# code is far away from bugs with the god
'''
origin = [0,30,20,80,50,10,60,70,90]
total = len(origin) - 1
def heap_adjust(n,i,array:list):
'''
调整当前结点,主要是为了保证以i为堆顶的堆是一个大顶堆(或者小顶堆)
:param n: 待排序的序列的总长度
:param i: 当前结点,因为要是一个堆,所以他必须至少有一个子结点
:param array: 待排序的列表
:return:
'''
while 2 * i <= n:
lchild_index = 2 * i
if lchild_index < n and array[lchild_index] < array[lchild_index + 1]:#如果有右孩子,并且右孩子的值比左孩子大
#array[i],array[lchild_index + 1] = array[lchild_index + 1],array[i]
lchild_index += 1
if array[lchild_index] > array[i]:#接上面,已经得到了左右结点中最大结点的index,只要将其与当前结点比较,得到最大的直接就可以了,
# 如果当前结点就是最大的,就不用比较了,这棵子树就是大顶堆了,这是有前提的,前提是认定了,已经从len(li) // 2开始进行了一次次向上了
array[i],array[lchild_index] = array[lchild_index],array[i]
i = lchild_index
else:
break
#调整成大顶堆
for i in range(total//2,0,-1):
heap_adjust(total,i,origin)
'''
heap_adjust(total,4,origin)
print(origin)
heap_adjust(total,3,origin)
print(origin)
heap_adjust(total,2,origin)
print(origin)
heap_adjust(total,1,origin)
print(origin)
#[0, 90, 50, 80, 30, 10, 60, 70, 20]
'''
print(origin)
#[0, 90, 50, 80, 30, 10, 60, 70, 20]
def heap(max_heap:list):
length = len(max_heap) - 1
print("length ---> ",length)
print("origin--->",max_heap)
for i in range(length,1,-1):
print("i-->",i,"element--",max_heap[i])
max_heap[1],max_heap[i]= max_heap[i],max_heap[1]
heap_adjust(i-1,1,max_heap)
heap(origin)
print(origin)