准备 kNN.py 的python模块
from numpy import *
import operator
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group,labels
问题:ValueError: only 2 non-keyword arguments accepted
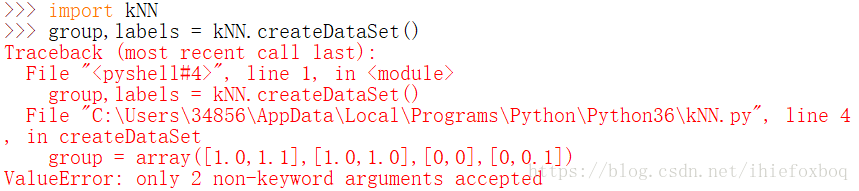
是由于一开始array里数组少了一对中括号
array([1.0,1.1],[1.0,1.0],[0,0],[0,0.1]) - --------加上就好了。如上图Python3.5中:iteritems变为items
问题:AttributeError: 'dict' object has no attribute 'iteritems'
Python3.6中:iteritems变为items
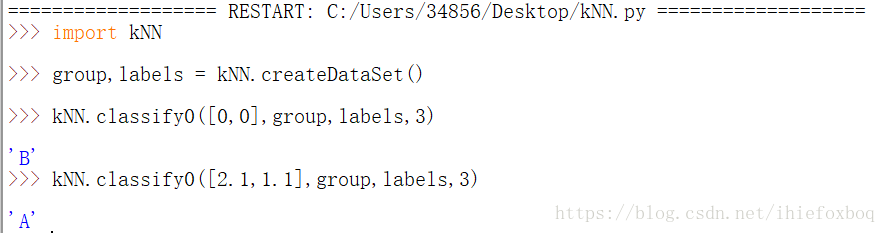
正常结果:
问题:NameError: name 'reload' is not defined
对于 Python 2.X:
import sys
reload(sys)对于 <= Python 3.3:
import imp
imp.reload(sys)对于 >= Python 3.4:
import importlib
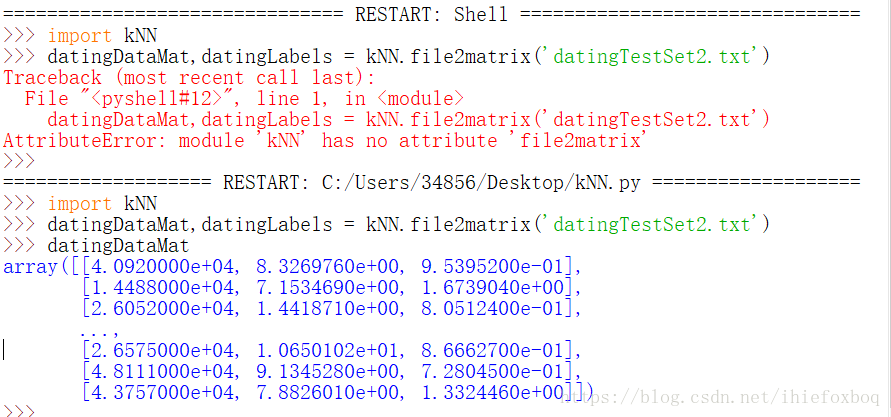
importlib.reload(sys)问题:AttributeError: module 'kNN' has no attribute 'file2matrix'
其实虽然能调出来,原理还是没搞明白 = =
问题:ValueError: invalid literal for int() with base 10: 'largeDoses'
下面是网上参考文献[1]中的例子
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: '1.0'
现象表现:
如果写int("1.0")就会错误,因为Python假设需要进行int转型的字符串仅仅包含数字,这时候用round(float("1.0"))就ok了。
据此找到上面错误的原因是: 该书代码示例有错, datingTestSet.txt应改为datingTestSet2.txt, 因为前者最末列是字符串, 后者最末列是整数.
问题:ValueError: embedded null character
出现这个错误的原因python解释器在遇到'\'会自动增加一个'\'以便与转义字符区分,但是遇到转义字符时不会增加'\',而书中的代码的文件目录有'\0',故而才会报错;解决方法,是把文件路路径中的'\'改为'/'
问题:TypeError: unsupported operand type(s) for %: 'NoneType' and 'tuple'
a = 'Peter'
b = 'Linda'
print("who is the murder? %s or %s?") % (a, b)
后来才发现,python3.x与python2.x有一点区别,
原来%(变量名,...)应该是加在print括号里的
如:print("who is the murder? %s or %s" % (a, b))
问题:NameError: name 'raw_input' is not defined
原因出在raw_input ,python3.0版本后用input替换了raw_input
问题:NameError: name 'img2vecctor' is not defined
NameError: name 'listdir' is not defined
1.
import os
os.listdir()2. from os import *
这里需要注意几个问题,如果直接使用import os的时候,那么调用是就需要写成os.listdir(),如果是使用from os import *,那么是可以直接使用listdir(),但是会出现模块之间的命名冲突问题,对代码的稳定性会有一定的影响,所以LZ建议如果对模块函数还不是很熟悉的情况下使用第一种方法。