使用了pycharm,和jupyter,均为python3版本。
一、首先根据章节内容创建KNN模块
在pycharm中编写模块:
from numpy import *
import operator
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group,labels
二、保存并导入模块
在jupyter中导入模块,导入过程如下:
import sys
sys.path.append("D:\xx\xxxxxx")
import KNN 在导入模块后,输入指令:
group,labels = KNN.createDataSet()出现错误: only 2 non-keyword arguments accepted
查阅网上回答,并没有找到原因,有位老哥说可能是KNN.py修改后,python没有来得及加载,将jupyter文件关掉,并在Home界面勾选文件,shutdown
再次打开文件,运行,没有出错。
三、python中k-近邻算法的具体实现
k-近邻算法的伪代码为:
接下来贴上代码:

def classify0(inx,dataSet,labels,k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inx,(dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis = 1)
distances = sqDistances **0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(),
key = operator.itemgetter(1),reverse = True)
return sortedClassCount[0][0]
需要十分注意的是
sortedClassCount = sorted(classCount.items()
一句中,原书为
sortedClassCount = sorted(classCount.iteritems()
注意python3与2之间的区别,否则这段会报错。
四、测试
在jupyter中键入:
import KNN group,labels = KNN.createDataSet() KNN.classify0([0,0],group,labels,3)获得结果:
再试一条:

import KNN group,labels = KNN.createDataSet() KNN.classify0([0.9,1],group,labels,3)结果:

看起来还不错。
代码是固定的,但是其中的一些具体代码之前都没接触过,以后会注重原始代码的来历以及应用。
2018.1.15更新
def classify0(inx,dataSet,labels,k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inx,(dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis = 1)
distances = sqDistances **0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(),
key = operator.itemgetter(1),reverse = True)
return sortedClassCount[0][0] 解释下这段代码中的几个函数:
1.numpy.tile(a,b)函数,是在列方向上重复N次,在这是重复dataSetSize次
具体用法为(这段代码是另一位老哥的,我就懒得写了,侵删):
>>> import numpy
>>> numpy.tile([0,0],5)#在列方向上重复[0,0]5次,默认行1次
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
>>> numpy.tile([0,0],(1,1))#在列方向上重复[0,0]1次,行1次
array([[0, 0]])
>>> numpy.tile([0,0],(2,1))#在列方向上重复[0,0]1次,行2次
array([[0, 0],
[0, 0]])
>>> numpy.tile([0,0],(3,1))
array([[0, 0],
[0, 0],
[0, 0]])
>>> numpy.tile([0,0],(1,3))#在列方向上重复[0,0]3次,行1次
array([[0, 0, 0, 0, 0, 0]])
>>> numpy.tile([0,0],(2,3))<span style="font-family: Arial, Helvetica, sans-serif;">#在列方向上重复[0,0]3次,行2次</span>
array([[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0]]) 2.
argsort函数返回的是数组值从小到大的索引值
突然发现一篇博客,写的十分详细,这里贴一下地址,传送门:http://blog.csdn.net/niuwei22007
四、4.1示例:使用k-近邻算法改进约会网站的配对效果
4.1.1准备数据
将文本记录转换为NumPy的解析程序:
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines())
returnMat = zeros((numberOfLines,3))
classLabeVector = []
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabeVector.append(int(listFromLine[3]))
index += 1
return returnMat,classLabeVector 之后在jupyter输入命令:(
原书中的reload在python3中需要
from imp import reload)
import sys
sys.path.append("D:\xx\xxxx")
import KNN 之后导入数据文件,文件在https://www.manning.com/books/machine-learning-in-action中的source code 有下载
import os
os.chdir('D:\\xx\\machinelearning\\MLiA_SourceCode')
datingDataMat,datingLabels = KNN.file2matrix('datingTestSet2.txt') 简单检查数据内容:
4.1.2分析数据:使用Matplotlib创建散点图

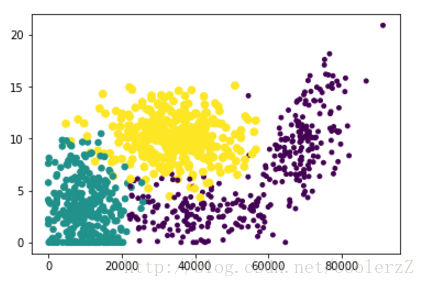
书中之前的两个散点图的具体创建不表,最终清晰标示不同样本分类区域的散点图用到了datingDataMat矩阵的第二和第三列属性。具体代码如下:
import matplotlib import matplotlib.pyplot as plt from numpy import array fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(datingDataMat[:,0],datingDataMat[:,1],15.0 * array(datingLabels),15.0 * array(datingLabels)) plt.show()最终效果如下:
4.2.3准备数据:归一化数值
在计算不同样本数据的距离时,我们会发现飞行常客里程数由于自身数字较大,会远远大于其他两项对计算结果的影响,所以在处理不同取值范围的特征值时,通常采用将数值归一化。
在KNN.py模块中增加新函数autoNorm(),使用该函数可以自动将数字特征转化为0-1之间。
代码如下:
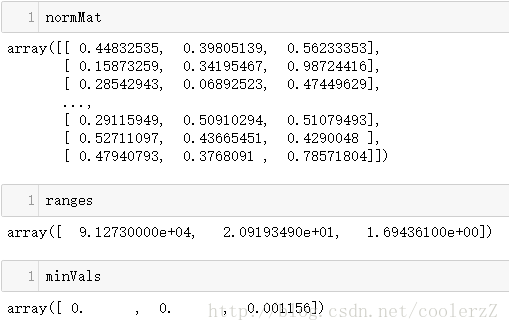
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals,(m,1))
normDataSet = normDataSet/tile(ranges,(m,1))
return normDataSet,ranges.minVals 在jupyter中输入指令:
from imp import reload reload(KNN)
normMat,ranges,minVals = KNN.autoNorm(datingDataMat)
得到结果:
4.2.4测试算法,完整程序验证分类器
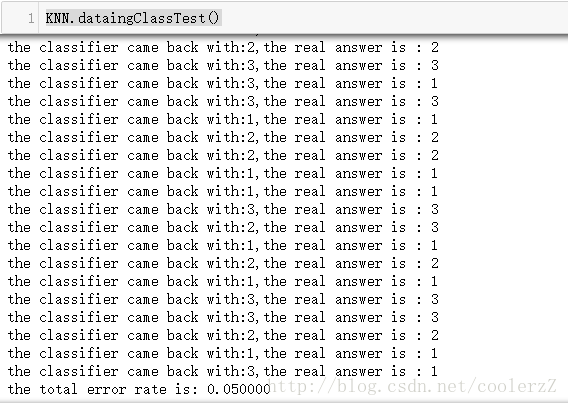
分类器针对约会网站的测试代码:
def dataingClassTest():
hoRatio = 0.10
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')
normMat,ranges,minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m * hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print('the classifier came back with:%d,the real answer is : %d'%(classifierResult,datingLabels[i]))
if (classifierResult != datingLabels[i]): errorCount += 1.0
print('the total error rate is: %f'%(errorCount/float(numTestVecs))) 继续在jupyter中测试:
reload(KNN) KNN.dataingClassTest()结果:
这个结果就要比书中的结果差一些,可能是数据有所改变?这个不太清楚。
4.2.5 使用算法构建完整可用的系统
约会网站预测函数:
def classifyPerson():
resultList = ['not at all','in small doses','in large doses']
percentTats = float(input('percentage of time spent playing video games?'))
ffMiles = float(input('frequent flier miles earned per year?'))
iceCream = float(input('liters of ice cream consumed per year?'))
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')
normMat,ranges,minVals = autoNorm(datingDataMat)
inArr = array([ffMiles,percentTats,iceCream])
classifierResult = classify0((inArr - minVals)/ranges,normMat,datingLabels,3)
print('You will probably like this person:',resultList[classifierResult -1])
依然在jupyter中测试:(记得reload)
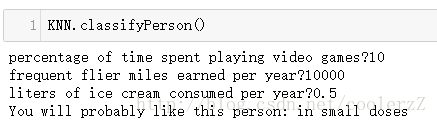
简单的约会网站匹配代码完成,所有的代码都可以在机器语言实战书中找到。代码看似简单实际深究还有很多需要细思的地方,我这里写的比较乱,而且细节理解不够,墙裂推荐@Tig_Free 大佬的文章,传送门:点我去参观代码,讲解清晰,适合入门菜鸡仔细品读。
2018.1.16修改
使用k-近邻算法识别手写数字
在KNN.py中加入函数,代码:
from os import listdir
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits')
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest,trainingMat,hwLabels,3)
print('the classifier came back with: %d, the real answer is: %d'\
%(classifierResult,classNumStr))
if (classifierResult != classNumStr):errorCount += 1.0
print('\nthe total number of errors is: %d '%errorCount)
print('\nthe total error rate is: %f '%(errorCount/float(mTest)))jupyter中敲入代码测试:(记得reloadKNN模块)
KNN.handwritingClassTest()
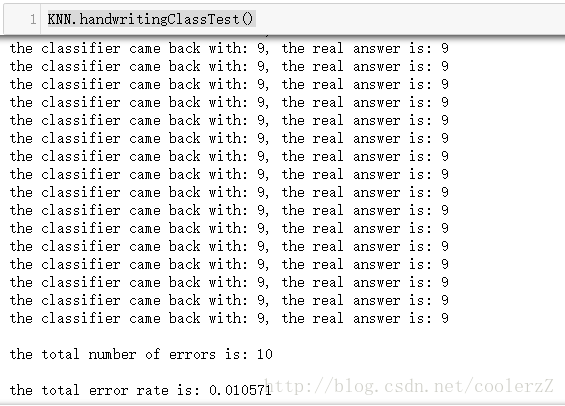
错误率比书上的结果还低一些。