一、KNN分类思想

二、例子一
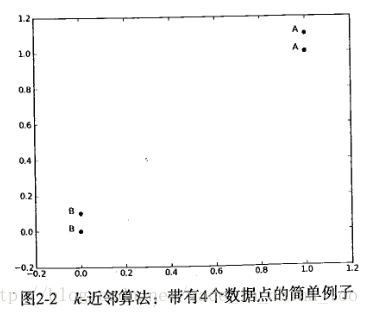
1.情景
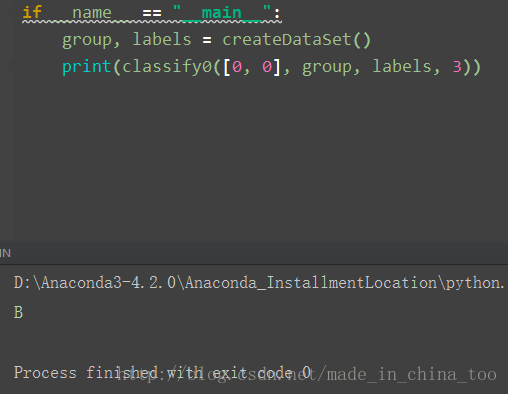
如下图,这里共有四个点,两个B类,两个A类。[1,1.1]-A 、[1,1]-A 、[0,0]-B 、[0,0.1]-B。现在我们输入点[0,0],要求KNN分类器帮我们分类,判断点[0,0]是A类还是B类。算法中设置K=3,表示在该图中,计算输入点[0,0]到图中已经分好类的点间的距离,然后按照距离递增次序排序,选取与输入点[0,0]距离最小的k个点(就是已经排好序的前k个节点),计算该k个点中哪个类别的点最多,出现频率最高的类别作为输入点[0,0]的预测分类。
2.所用函数
''' createDataSet():
共有四个点,两个B类,两个A类。[1,1.1]-A 、[1,1]-A 、[0,0]-B 、[0,0.1]-B,
将它们有序的返回到gourp,labels
group=
[[ 1. 1.1]
[ 1. 1. ]
[ 0. 0. ]
[ 0. 0.1]]
labels= ['A', 'A', 'B', 'B']
'''
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
''' classify0(inX, dataSet, labels, k):
inX=需要进行预测分类的向量;dataSet=已经分好类的数据集;labels=对应dataSet中各个对象的分类标签。
将向量[inX]归类到与其距离最近的k个向量中所属标签出现频率最高的那一个标签
'''
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] #dataSet矩阵的列对应的是一个对象的属性,行对应的是某一个对象;
#这句返回dataSet矩阵第0列的长度(dataSet矩阵的行数,也是对象总数)
#dataSetSize = dataSet矩阵的行数
diffMat = tile(inX, (dataSetSize,1)) - dataSet #tile(inX, (dataSetSize,1)),创造具有
#dataSetSize行1列的矩阵,矩阵每个元素都为向量[inX]。
#diffMat=dataSet中每个对象与向量[inX]的距离
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1) #sqDistances=sqDiffMat的所有列相加
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort() #返回distances中元素大小是递增排序对应的下标
#sortedDistIndicies = 与[inX]距离递增排列的点的下标
classCount={}
for i in range(k): # 0<=i<k
voteIlabel = labels[sortedDistIndicies[i]] #返回与[inX]距离最近的第i个点的标签
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 #遍历完k次后,该句可以统计与[inX]距离
#最近的k个点中,各个标签出现的次数
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0] #sortedClassCount = 将classCount={}的标签频率递增排列返回的序列3.运行结果
三、例子二
1.情景
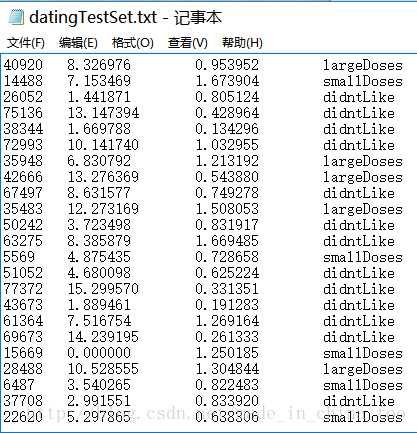
海伦收集了自己的1000条约会信息(datingTestSet.txt),每条信息对应的属性是:
[ 每年获得的飞行常客里程数,玩视频游戏所耗时间百分比,每周消费的冰淇淋公升数,海伦喜欢这个男生的程度 ]
该例子要进行两个实验:
1. 取datingTestSet.txt中90%的数据作为训练集、10%的数据作为验证集,并计算分类的错误率
2.根据海伦提供的一条男生的信息【每年获得的飞行常客里程数,玩视频游戏所耗时间百分比,每周消费的冰淇淋公升数】,判断海伦是否喜欢这个男生
2.从文本解析数据
以下函数将从datingTestSet.txt中读取数据,并将海伦喜欢这个男生的程度进行转换:
[ largeDoses,smallDoses,disntLike ]->[ 3,2,1 ]
代码:
'''
读取文件filename,将原数据集拆分为两个数据结构returnMat矩阵、classLabelVector数组
并返回returnMat(returnMat是由原数据集除去最后一列的矩阵)
并返回classLabelVector(数组中第i个元素就是原数据集中第i行的最后一列的属性,且存入
数组前已将最后一列的属性映射到3,2,1三个数字中的一个)
'''
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #numberOfLines = 数据集的行数
returnMat = zeros((numberOfLines,3)) #returnMat = numberOfLines行3列的零矩阵
classLabelVector = []
fr = open(filename)
index = 0
int = {'largeDoses': 3, 'smallDoses': 2, 'didntLike': 1} #创建名为int的字典,将并将海伦喜欢这个男生的程度进行转换:
#[ largeDoses,smallDoses,disntLike ]->[ 3,2,1 ]
for line in fr.readlines():
line = line.strip() #去除当前一行字符串头尾的空格
listFromLine = line.split('\t') #将当前字符串按照'\t'进行分割,例如第一行数据这里会返回一个数组为:
#['40920', '8.326976', '0.953952', 'largeDoses']
returnMat[index,:] = listFromLine[0:3] #将一行数据中的前三个属性放入零矩阵的第index行,例如这里
#将'40920', '8.326976', '0.953952'放入零矩阵的第0行
classLabelVector.append(int[listFromLine[-1]]) #将listFromLine的最后一个元素(即'largeDoses')按照字典转化
#为3 并添加到数组classLabelVector
index += 1
return returnMat,classLabelVector结果:

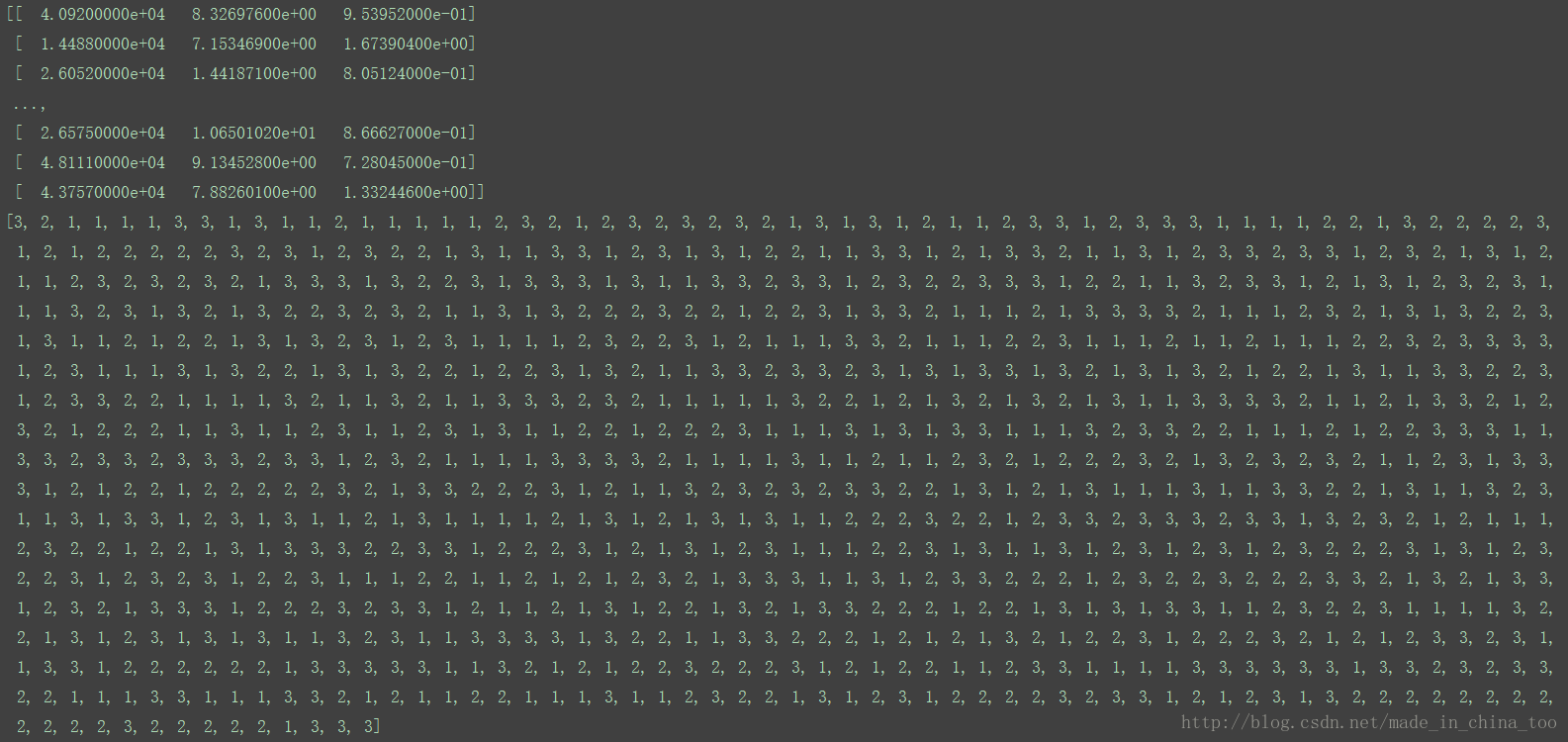
3.画出散点图
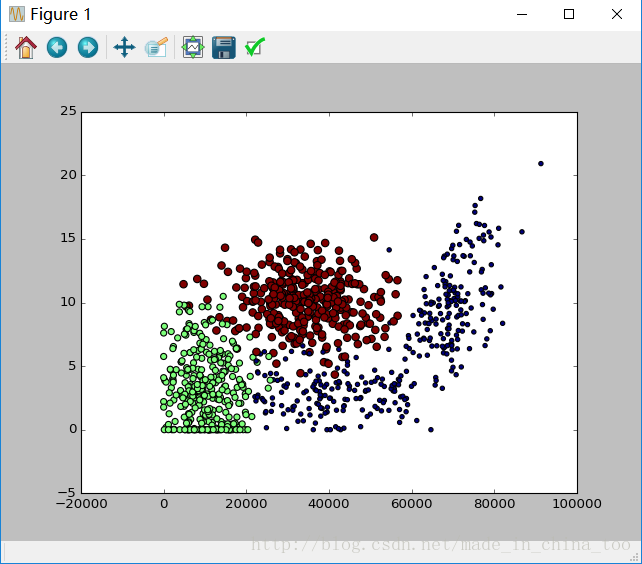
使用returnMat,classLabelVector画出散点图,其中横坐标x=每年获取的飞行常客里程数,纵坐标y=玩视频游戏所耗时间百分比。
代码:
'''
returnMat,classLabelVector=file2matrix('datingTestSet.txt')
使用returnMat,classLabelVector画出散点图,
其中横坐标x=每年获取的飞行常客里程数,纵坐标y=玩视频游戏所耗时间百分比。
s为datingDataMat对应第i行数据点的size,size的数值等于classLabelVector数组中第i个
元素([ largeDoses,smallDoses,disntLike ]->[ 3,2,1 ],3、2、1中的一个)乘以15。
c为datingDataMat对应第i行数据点的color,color的数值等于classLabelVector数组中第i个
元素([ largeDoses,smallDoses,disntLike ]->[ 3,2,1 ],3、2、1中的一个)乘以15。
'''
def painting(datingDataMat, datingLabels): #从datingDataMat,datingLabels=file2matrix('datingTestSet.txt')获取参数,并画出散点图
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111)
# ax.scatter(datingDataMat[:,1],datingDataMat[:,2])
ax.scatter(datingDataMat[:, 0], datingDataMat[:, 1], s=15 * array(datingLabels), c=15 * array(datingLabels))
plt.show()结果:

4.数据准备:归一化数据
代码:
'''
这里的参数dataSet使用经过函数file2matrix(filename)返回的returnMat矩阵,其中
returnMat矩阵只包含'datingTestSet.txt'的0~2共3列的数据。
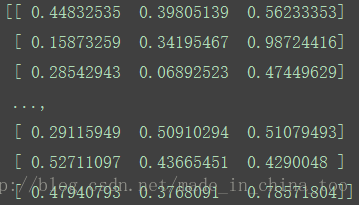
函数autoNorm(dataSet)将returnMat矩阵进行归一化处理(即将returnMat矩阵中的所有数据转化为0~1之间),
并将结果返回到normDataSet,而返回的
数组ranges=[(第一列元素极差),(第二列元素极差),(第三列元素极差)]
'''
def autoNorm(dataSet):
minVals = dataSet.min(0) #返回当min()的参数为0时,返回dataSet每列的最小值
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet)) #构建与dataSet矩阵相同大小的零矩阵
m = dataSet.shape[0] # m=dataSet矩阵的行数
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1))
return normDataSet, ranges, minVals结果:

5.取’datingTestSet.txt’中的第0~10%的数据作为待分类集,取第10%~100%的数据作为已经分好类的数据集。并计算kNN分类器的错误率
代码:
'''
取'datingTestSet.txt'中的第0~10%的数据作为待分类集,取第10%~100%的数据作为已经分好类的数据集。
并计算kNN分类器的错误率
'''
def datingClassTest():
hoRatio = 0.10 # hold out 10%
datingDataMat, datingLabels = file2matrix('datingTestSet.txt') # load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m * hoRatio)
errorCount = 0.0
for i in range(numTestVecs): #这个for循环中取normMat的第0~10%的数据作为待分类集,取第10%~100%的数据作
#为已经分好类的数据集。
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)
#classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)中,例如i=0是,则
#取normMat矩阵的第0行在已经分好类的normMat矩阵的第numTestVecs到m行的数据中进行分类,计算前3个最接近【normMat矩阵第0行数据的特征】的
#数据所对应的标签出现次数,将normMat矩阵的第0行数据归类为出现频率最高的标签
if classifierResult == datingLabels[i]:
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]))
else:
errorCount += 1.0
print("\33[1;35m the classifier came back with: %d, the real answer is: %d \33[0m" % (
classifierResult, datingLabels[i]))
print("the total error rate is: %f" % (errorCount / float(numTestVecs)))
print("errorCount= ",errorCount)
结果:

6.通过海伦输入某男生的信息【每年获得的飞行常客里程数,玩视频游戏所耗时间百分比,每周消费的冰淇淋公升数】,使用该程序判断海伦是否喜欢这个男生
代码:
'''
通过海伦输入某男生的信息【每年获得的飞行常客里程数,玩视频游戏所耗时间百分比,每周消费的冰淇淋公升数】,使用
该程序判断海伦是否喜欢这个男生
'''
def classifyPerson():
resultList = ['disntLike' ,'smallDoses','largeDoses']
percentTats = float(input("percentage of time spent playing video games?"))
ffMiles = float(input("frequent flier miles earned per year?"))
iceCream = float(input("liters of ice cream consumed per year?"))
datingDataMat , datingLabels = file2matrix('datingTestSet.txt')
normMat , ranges , minVals = autoNorm(datingDataMat)
inArr=array([ffMiles,percentTats,iceCream])
classfierResult=classify0((inArr-minVals)/ranges,normMat,datingLabels,3)
print("You will probably like this person:", resultList[classfierResult-1])结果:

四、例子三
1.情景
现在我们要构建一个手写识别系统。
(训练集的格式与测试集相同)
目前我们有一堆训练数据集(手写数字及其标签,例如文件名0_14.txt表示这个第14个手写数字’0’的样本,0同时也是该样本的标签。),具体如下图:

2.代码
'''
图像用txt文件表示,是一个32*32的矩阵。该函数将这个矩阵放入一个1*1024的向量里面。
例如,矩阵中第一行放入向量的0~31号位置,矩阵中的第二行放入向量的32~63号位置。
'''
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
'''
将目录“trainingDigits”的全部文件放进一个矩阵trainingMat中,矩阵trainingMat的行数等于文件数,列数等于每个文件的长度;
函数handwritingClassTest()将目录“testDigits”中的全部测试集进行kNN分类,并与测试集原本自带的标签进行比较,得出分类的错误率
'''
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits') #listdir函数将返回目录中的所有文件名
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #以“.”进行划分,获取第0号划分元素
classNumStr = int(fileStr.split('_')[0]) #以“_”进行划分,获取第0号划分元素
hwLabels.append(classNumStr) #将当前样本的标签存放到数组hwLabels的尾部
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print( "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr))
if (classifierResult != classNumStr): errorCount += 1.0
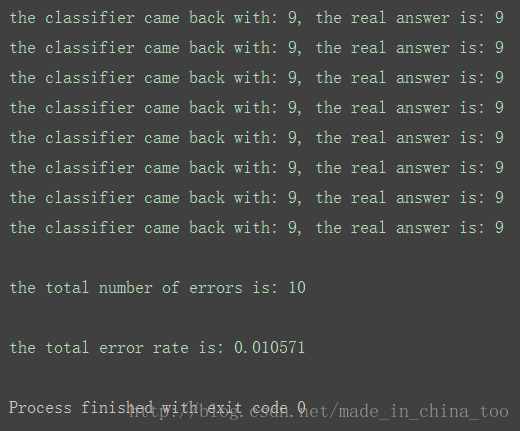
print( "\nthe total number of errors is: %d" % errorCount)
print ("\nthe total error rate is: %f" % (errorCount/float(mTest)))
3.运行结果

五、使用kNN挖掘一个真实的数据集
(1)MNIST数据集
MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.
MNIST 数据集包含了四个部分:
● Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
● Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
● Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
● Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
(2)MNIST数据集的存储格式
1.TRAINING SET LABEL FILE (train-labels-idx1-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 60000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
……..
xxxx unsigned byte ?? label
The labels values are 0 to 9.
2.TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
……..
xxxx unsigned byte ?? pixel
Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black).
3.TEST SET LABEL FILE (t10k-labels-idx1-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000801(2049) magic number (MSB first)
0004 32 bit integer 10000 number of items
0008 unsigned byte ?? label
0009 unsigned byte ?? label
……..
xxxx unsigned byte ?? label
The labels values are 0 to 9.
4.TEST SET IMAGE FILE (t10k-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 10000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
……..
xxxx unsigned byte ?? pixel
Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black).
(3)MNIST数据集的读取方法
1.函数load_mnist(path, kind=’train’)
从指定路径path读取mnist数据集,返回矩阵images存放所有图像,每行有28*28个像素点(代表一个图片), 共有60,0000行。返回一维数组labels,存放每张图片对应的标签
2.函数print_First_10_Row(images,labels)
从load_mnist(path, kind=’train’)中返回images, labels,将images的前10行(共10张图片)显示出来
'''
def load_mnist(path, kind='train'):从指定路径path读取mnist数据集,返回矩阵images存放所有图像,每行有28*28个像素点(代表一个图片),
共有60,0000行。返回一维数组labels,存放每张图片对应的标签
'''
def load_mnist(path, kind='train'):
"""Load MNIST data from `path`"""
labels_path = os.path.join(path,'%s-labels.idx1-ubyte'% kind)
images_path = os.path.join(path,'%s-images.idx3-ubyte'% kind)
with open(labels_path, 'rb') as lbpath:
magic, n = struct.unpack('>II',lbpath.read(8))
labels = fromfile(lbpath,dtype=uint8)
with open(images_path, 'rb') as imgpath:
magic, num, rows, cols = struct.unpack('>IIII',imgpath.read(16))
images = fromfile(imgpath,dtype=uint8).reshape(len(labels), 784)
return images, labels
'''
def print_First_10_Row(images,labels):从load_mnist(path, kind='train')中返回images, labels,
将images的前10行(共10张图片)显示出来,,并在控制台输出这10张图片真实的标签
'''
def print_First_10_Row(images,labels):
print(labels[0:10])
fig, ax = plt.subplots(nrows=2,ncols=5,sharex=True,sharey=True, )
ax = ax.flatten()
for i in range(10):
img = images[i].reshape(28, 28)
ax[i].imshow(img, cmap='Greys', interpolation='nearest')
ax[0].set_xticks([])
ax[0].set_yticks([])
plt.tight_layout()
plt.show()
(4)对测试集中的前100个样本进行kNN(k=3)分类测试
所用函数:
''' classify0(inX, dataSet, labels, k):
inX=需要进行预测分类的向量;dataSet=已经分好类的数据集;labels=对应dataSet中各个对象的分类标签。
将向量[inX]归类到与其距离最近的k个向量中所属标签出现频率最高的那一个标签
'''
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] #dataSet矩阵的列对应的是一个对象的属性,行对应的是某一个对象;
#这句返回dataSet矩阵第0列的长度(dataSet矩阵的行数,也是对象总数)
#dataSetSize = dataSet矩阵的行数
diffMat = tile(inX, (dataSetSize,1)) - dataSet #tile(inX, (dataSetSize,1)),创造具有
#dataSetSize行1列的矩阵,矩阵每个元素都为向量[inX]。
#diffMat=dataSet中每个对象与向量[inX]的距离
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1) #sqDistances=sqDiffMat的所有列相加
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort() #返回distances中元素大小是递增排序对应的下标
#sortedDistIndicies = 与[inX]距离递增排列的点的下标
classCount={}
for i in range(k): # 0<=i<k
voteIlabel = labels[sortedDistIndicies[i]] #返回与[inX]距离最近的第i个点的标签
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 #遍历完k次后,该句可以统计与[inX]距离
#最近的k个点中,各个标签出现的次数
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0] #sortedClassCount = 将classCount={}的标签频率降序返回的序列
'''
使用kNN进行测试(MNIST的训练集,MNIST的测试集),path是MNIST数据集在硬盘中的存放路径,k是kNN使用的k值
'''
def kNN_MNIST(path,k):
train_x, train_y = load_mnist(path,'train')
test_x, test_y = load_mnist(path,'t10k')
test_x_size=test_x.shape[0]
print(test_x_size)
errorCount=0.0
for i in range(test_x_size):
classifierResult=classify0(test_x[i], train_x, train_y, k)
if classifierResult!=test_y[i]:
errorCount+=1.0
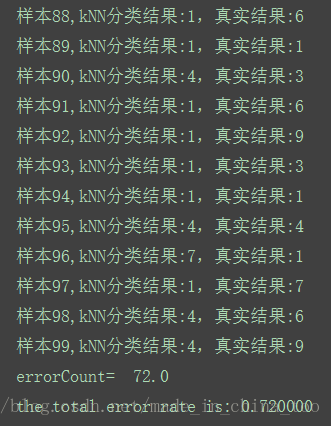
print("样本%d,kNN分类结果:%d,真实结果:%d" % (i,classifierResult,test_y[i]))
print("errorCount= ", errorCount)
print("the total error rate is: %f" % (errorCount / float(test_x_size)))