KNN工作原理:
输入为实例的特征向量,对应于特征空间的点;
输出为实例的类别
k 近邻算法假设给定一个训练数据集,其中的实例类别已定。
分类时,对新的实例,根据其 k 个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻算法不具有显式的学习过程。
k 近邻算法实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”。 k值的选择、距离度量以及分类决策规则是k近邻算法的三个基本要素。
代码:
import numpy as np
import matplotlib.pyplot as plt
from collections import Counter
#创建训练数据集(创建多个点)
user_data=[[0.3, 0.6],
[3.5, 5.8],
[2.4, 1.9],
[1.3, 8.2],
[2.4, 7.9],
[5.1, 7.1],
[6.8, 3.2],
[7.5, 6.3],
[4.9, 9.5],
[2.3, 5.0]]
#标签
user_class=[0,0,0,0,0,1,1,1,1,1]
#转换为array矢量数组
user_train=np.array(user_data)
user_lable=np.array(user_class)
#创建测试数据集
user_test=np.array([4.5, 5.1])
#显示初始数据
plt.scatter(user_train[user_lable == 0, 0], user_train[user_lable == 0, 1])
plt.scatter(user_train[user_lable == 1, 0], user_train[user_lable == 1, 1])
plt.scatter(user_test[0], user_test[1])
#定义测试函数
def predict_math(data_test,data_train,lable_train):
#1.计算测试数据集点与训练数据集点之间的距离,放入distance列表中
distance=[]
for data in data_train:
# 欧式距离
distance.append(np.sqrt(np.sum(np.square(data_test-data))))
#print(distance)
#2.列表值从小到大排列,并返回其索引值
near = np.argsort(distance)
#print(near)
#3.定义k值,获取对应标签,k值必须是奇数才能选出(少数服从多数)
k_value = 3
top = []
for i in near[:k_value]:
top.append(lable_train[i])
#print(top)
#4.统计标签出现次数最多的元素,得到测试数据集点的类型
vote = Counter(top).most_common(1)[0][0]
print("{}的类型是{}".format(data_test,vote))
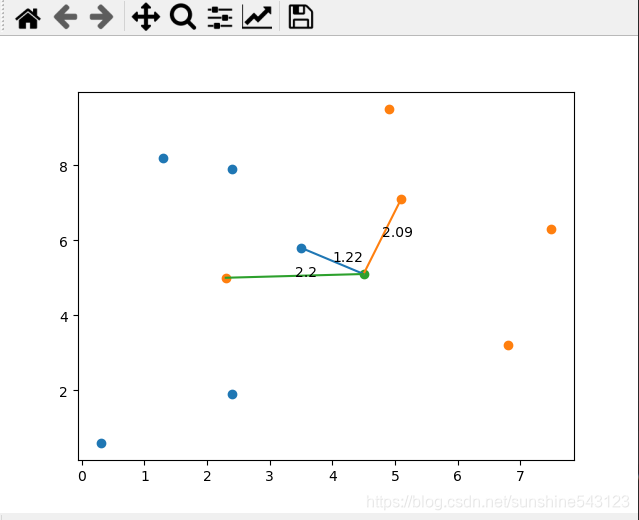
#绘制最短的三个距离
topk=near[:k_value]
for i in range(k_value):
plt.plot([data_test[0], data_train[topk[i]][0]], [data_test[1], data_train[topk[i]][1]])
plt.text((data_test[0]+data_train[topk[i]][0])/2,
(data_test[1]+data_train[topk[i]][1])/2, "%s" % round(distance[topk[i]],2))
plt.show()
pass
predict_math(user_test,user_train,user_lable)
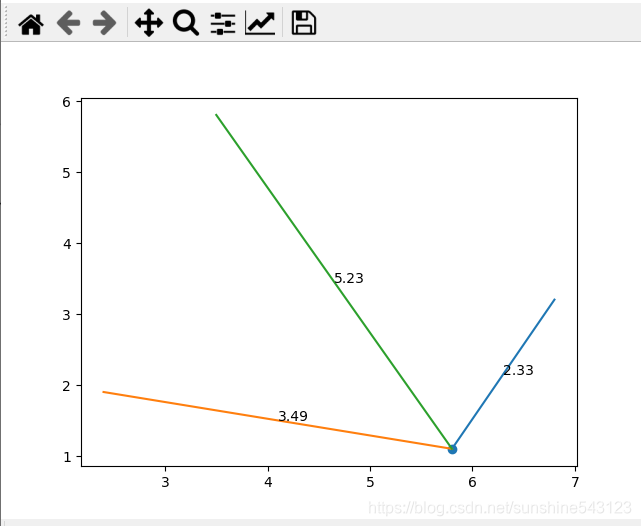
user_test2=np.array([5.8, 1.1])
plt.scatter(user_test2[0], user_test2[1])
predict_math(user_test2,user_train,user_lable)运行结果: