概述
准备Python导入数据
from numpy import *
import operator
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
查看
import kNN
group,labels = kNN.createDataSet()
print(group)
print(labels)实施kNN分类算法
from numpy import *
import operator
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]#行数
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)#行相加
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
if __name__ == '__main__':
group, labels = createDataSet()
print(group)
print(labels)
print(classify0([0,0],group,labels,3))
示例:使用kMM算法改进约会网站的配对效果
准备数据:从文本中解析数据
文件所在地址->
import kNN
def file2matrix(filename):
fr = open(filename)
arrayOLines = fr.readlines()
numberOfLines = len(arrayOLines) # 得到文件的行数
returnMat = kNN.zeros((numberOfLines, 3)) # 创建返回的矩阵--行列
classLabelVector = [] # 分类标签向量
index = 0
for line in arrayOLines:
line = line.strip() # 去掉回车符
listFromLine = line.split('\t') # 根据'\t'进行分割,成元素列表
returnMat[index,:] = listFromLine[0:3] # 前三个元素存入矩阵
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat, classLabelVector
if __name__ == '__main__':
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
print(datingDataMat)
print(datingLabels)分析数据:使用Matplotlib创建散点图
PyCharm不能直接安装MAtplotlib,可以用终端在Scripts位置pip install matplotlib安装。
import kNN
import matplotlib
import matplotlib.pyplot as plt
def file2matrix(filename):
fr = open(filename)
arrayOLines = fr.readlines()
numberOfLines = len(arrayOLines) # 得到文件的行数
returnMat = kNN.zeros((numberOfLines, 3)) # 创建返回的矩阵--行列
classLabelVector = [] # 分类标签向量
index = 0
for line in arrayOLines:
line = line.strip() # 去掉回车符
listFromLine = line.split('\t') # 根据'\t'进行分割,成元素列表
returnMat[index,:] = listFromLine[0:3] # 前三个元素存入矩阵
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat, classLabelVector
if __name__ == '__main__':
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
print(datingDataMat)
print(datingLabels)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:, 1], datingDataMat[:, 2])
plt.show()结果如下图所示(第二、第三行数据):
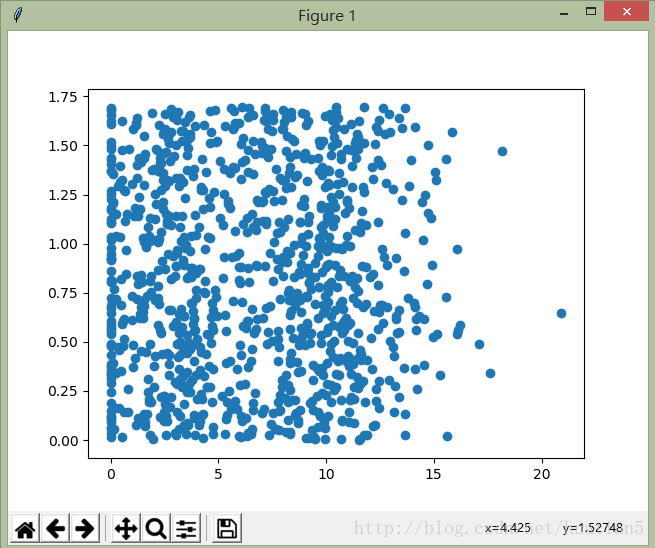
使用参数ax.scatter(datingDataMat[:,1], datingDataMat[:,2], 15.0*kNN.array(datingLabels), 15.0*kNN.array(datingLabels))
结果如下图所示(第二、第三行数据):
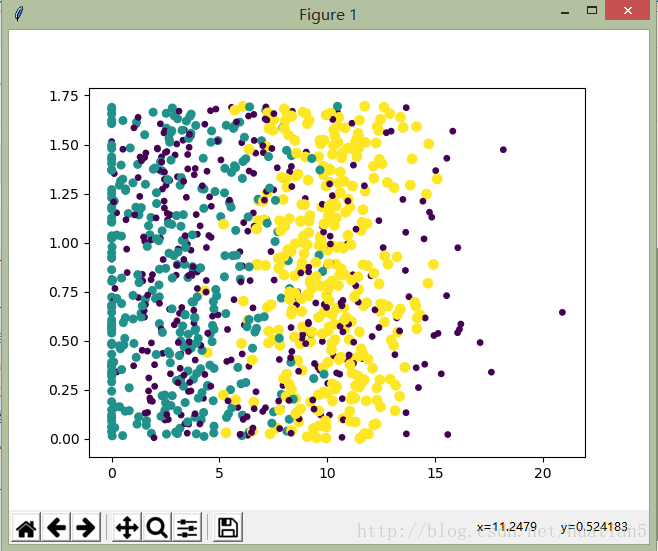
结果如下图所示(第一、第二行数据):
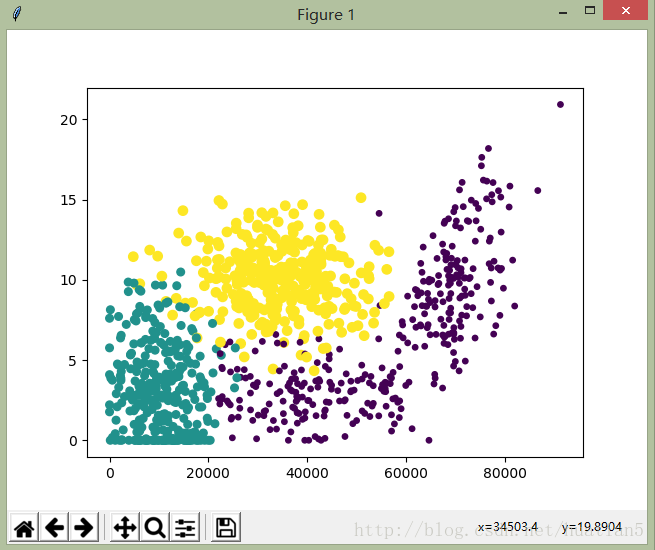
准备数据:归一化数值
from numpy import *
import date
def autoNorm(dataSet):
minVals = dataSet.min(0)#0代表从列中取值
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1))
return normDataSet, ranges, minVals
if __name__ == '__main__':
datingDataMat, datingLabels = date.file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
print(normMat)
print(ranges)
print(minVals)测试算法:作为完整程序验证分类器
(不在编写独立文件了太麻烦)
def datingClassTest():
hoRatio = 0.10
datingDataMat,datingLabels = file2matrix('datingTestSet.txt')
normMat, ranges ,minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print("the ckassifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]))
if(classifierResult != datingLabels[i]):
errorCount += 1.0
print("the total error rate is: %f" % (errorCount/float(numTestVecs)))使用算法:构建完整可用系统
def classifyPerson():
resultList = ['not at all', 'in small doses', 'in large doses']
percenTats = float(input("percentage of time spent playing video games?"))
ffMiles = float(input("frequent fliter miles earned per year?"))
iceCream = float(input("liter of ice cream consumed per year?"))
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges , minVals = autoNorm(datingDataMat)
inArr = array([ffMiles, percenTats, iceCream])
classifierResult = classify0((inArr-minVals)/ranges,normMat,datingLabels,3)
print("You will probably like this person:",resultList[classifierResult - 1])使用K-近邻算法识别手写数字
from numpy import *
from os import listdir
import operator
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]#行数
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis=1)#行相加
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits')#listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。
m = len(trainingFileList)#数目
trainingMat = zeros((m,1024))#创建训练集矩阵
for i in range(m):
#获取文件名
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
#将数据加入训练集
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print("the classifier came back with : %d,the real answer is: %d" % (classifierResult,classNumStr))
if(classifierResult != classNumStr):
errorCount += 1.0
print("\nthe total number of errors is: %d" % errorCount)
print("\nthe total error rate is: %f" % (errorCount/float(mTest)))
if __name__ == '__main__':
handwritingClassTest()