摘要
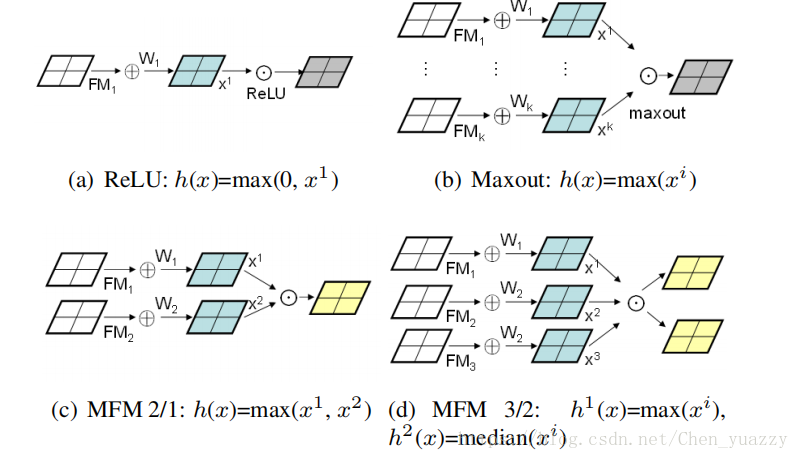
第一,提出了对于CNN每一层的maxout activation,得到了Max-Feature-Map(MFM)。MFM区别于ReLU,ReLU通过设置下限封锁神经元,MFM通过竞争关系封锁神经元。MFM不仅能分离噪声信号和信息信号,也可以在特征选取中扮演重要的角色。
第二,为了减少参数的数量和改善表现,提出了有5个卷积层和4个NIN层的网络。
第三,设计了语义引导方法(semantic bootstrapping),使得模型预测在噪声标签上连续性更好。
简介:
这篇论文的主要贡献如下:
第一,提出了MFM操作,一种特殊的Maxout来学习light CNN,light CNN有较小数量的参数。相较于ReLU,MFM应用了一个竞争关系,因此有更加广泛的能力,且适用于不同的数据。
第二,基于MFM的light CNN被设计用来学习普遍的面部特征。小核卷积过滤器和NIN用来减少参数space。这种配置在速度和空间上取得了更好的表现。
第三,提出了经过预训练的深度网络的语义引导方法,解决大尺寸数据集的噪声标签图像问题,不连续的标签能被有效的探测出来,通过预测的概率,然后重新标记或者移除。
第四,提出的256维特征的简单模型在五个数据集上获得了最佳结果。模型大约有5556K参数,抽取脸部特征大约用时67ms.
结构:
3.1 MFM操作
每一个卷积层的激活函数必须如下特征:
1)大尺寸的数据集包含着多种噪声,我们期望噪声信号和信息信号分离
2)当图像里有水平边缘或者线的时候,神经元对水平信息的应答受制于神经元对垂直信息的抑制。
3)一个神经元是否受抑制是parameter free(?)的,因此它不取决于训练数据。
我们提出了Max-Feature-Map(MFM)操作,是Maxout激活的扩展,Maxout激活使用了足够多的隐藏神经元,去无限接近于一个凸函数。MFM抑制少量的神经元,使得CNN模型轻量并更加鲁棒。我们定义2个MFM操作获得竞争特征映射。
输入卷积层xn∈RHXW啊,n={1,…,2N},W和H代表特征映射的空间宽度和高度。
MFM2/1操作组合了两个特征映射,输出element-wise的最大值。式子如下:
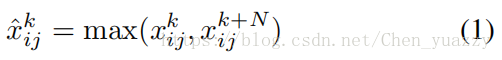
卷积层输入信道数量为2N。1<=k<=N,1<=i<=H,1<=j<=W.如上式,输入x经过MFM操作后属于RHXWXN范围内。
梯度如同下式所示:
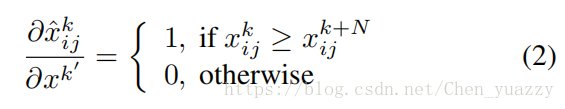
1<=k’<=2N且,
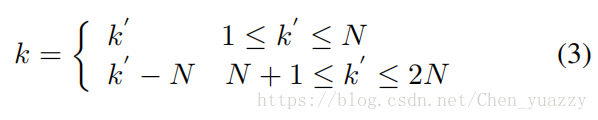
考虑到MFM2/1,我们主要获取了来自输入特征映射50%的信息神经元,通过特征信道的element-wise 最大化操作。
更进一步的,我们获取更多可操作的特征映射,MFM3/2操作,输入三个特征映射,移除element-wise最小的那个,可以写成如下形式:
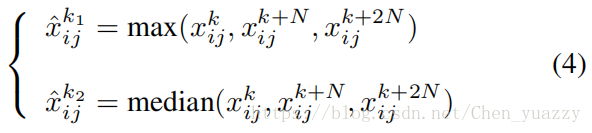
x∈R,1<=n<=3N,1<=k<=N,median()是输入特征映射的中值。MFM3/2的梯度和(3)式很相似,当x激活时,梯度的值为1。这样,我们选择和保留了2/3输入特征映射的信息。
3.2 Light CNN框架
MFM操作引入CNN后,它有着和生物统计学中的局部特征相似的特征选取作用。它用不同的过滤器选取了相同位置的最佳特征。它产生了二值梯度(0或1),在反向传播时来激发或者抑制神经元。
由于稀疏梯度,在一方面,训练时CNN反向传播时,SGD过程只在神经元的应答变量起作用。另一方面,测试时抽取特征时,MFM可以通过激活两个特征映射从先前的卷积层获取更多竞争结点。因此MFM能够起到特征选取和稀疏连接的作用。
此外,因为NIN能够做卷积层和卷积核之间的特征选择,所以能够减少模型的参数数量。最终,提出的light CNN包括了5个卷积层,4个NIN层,MFM层,4个Max-pooling层和2个全连接层。
3.3 噪声标签的semantic bootstrapping
Bootstrapping,又称自训练,是一个样本估计的简单的方法。由于其简易型和有效性广泛应用于估计样本分布。基本思想是:训练样本的预测结果能被重新标记,通过re-sampling和从原始标记样本的推断结果表现。它能估计复杂数据分布的标准差和置信度区间,也可以控制估计的稳定性。
使x∈X和t分别为数据和他们的标签。预测可以被写成条件概率的形式:p(t|f(x))。p的最大值决定了预测的标签,尤其是对于大量对象。首先,我们在原始噪声标签数据集上训练light CNN模型。MFM操作导致了训练的知觉连续性的概率鲁棒性。因为MFM的梯度是稀疏的。因此就算数据集中有大量的噪声数据,Light CNN模型也能趋于稳定。第二,我们使用训练过的模型预测噪声标记过的标签。并根据条件概率p(ti|f(x))设置下限决定是否接收或拒绝这个预测。最后,我们在重新标记过的数据集上重新训练light CNN模型。