先上链接:
论文:Light-Head R-CNN: In Defense of Two-Stage Object Detector
链接:https://arxiv.org/abs/1711.07264
代码: TF链接
introduction
本篇文章介绍的算法是是旷视和清华大学在COCO 2017比赛拿到冠军的算法。目前常用的object detection框架有两种:一种是基于single-stage的SSD和YOLO,特点是速度快,但是精度有待提升;另一种是基于two-stage的Faster R-CNN、R-FCN和Mask R-CNN等,特点是精度高,但是速度慢。在文中,作者分析了two-stage算法主要有两部分组成:第一步是生成proposal(或说ROI)的过程(作者称之为body),第二步是基于proposal(ROI)的recognition过程(作者称之为head)。为了实现best accurcy,head一般都设计的很“重”,且head部分有一些层(例如:fc层)计算量大并耗时,故导致检测速度很慢。本文提出的light head RCNN则是主要通过对head部分的修改减少了较多计算量,故称之为light head。
网络结构包括两部分:ROI warping和 R-CNN subnet。
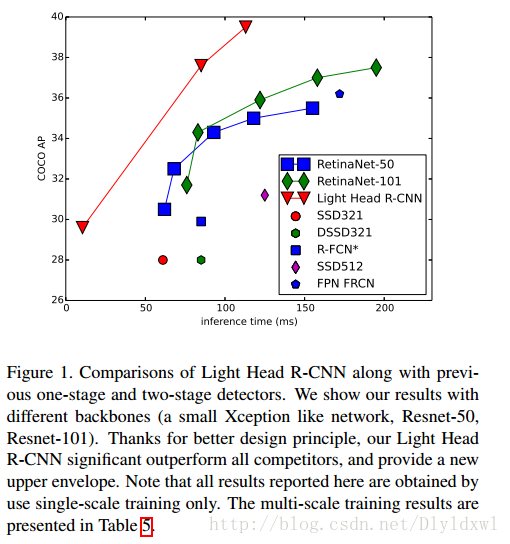
先上一张图直观感受一下本文算法对比其他object detection算法的效果。
Approach
下图介绍的是Faster R-CNN、R-FCN和light head RCNN在结构上的对比。可以看出two-stage网络大都可以分为两部分:ROI warping和 R-CNN subnet。图中虚线框起来的部分是各网络的R-CNN subnet部分。这类算法的基本流程是这样的:通过base feature extractor(即特征提取网络)中某一层输出的feature map作为ROI warping的输入从而生成ROI,接着将ROI和feature map共同作为R-CNN subnet的输入完成 image classification和 object regression。
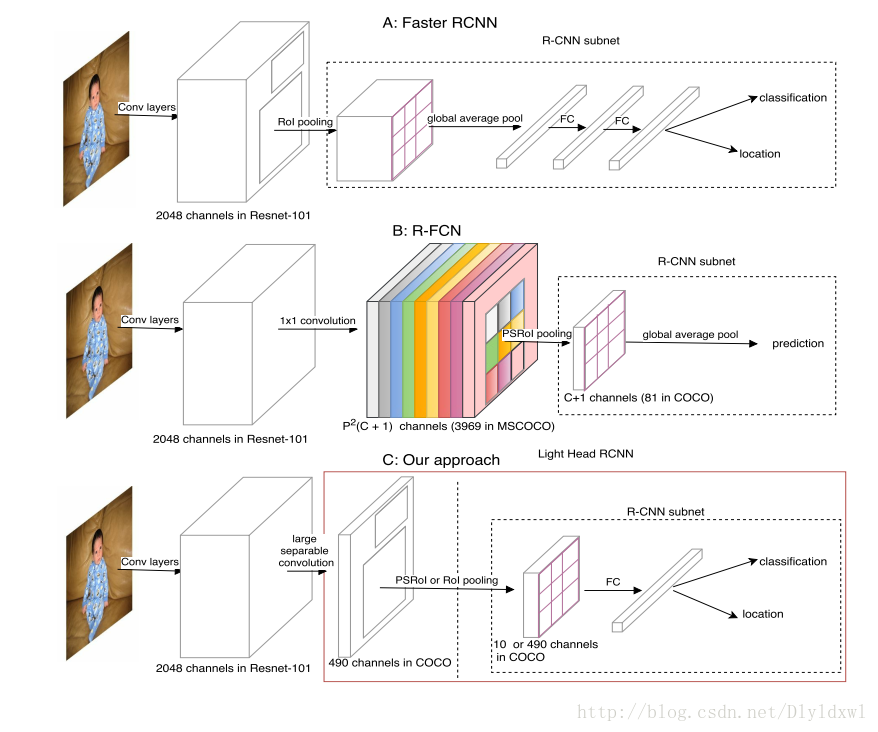
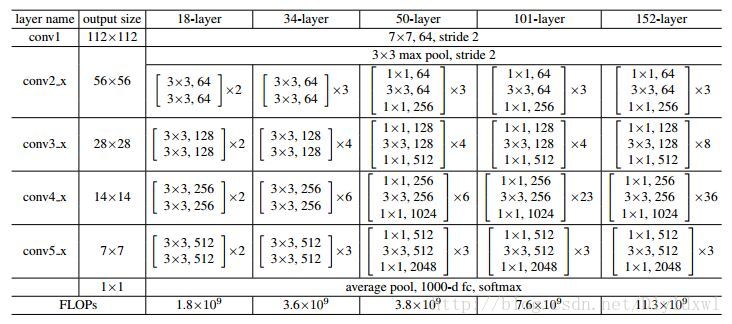
以下将Faster R-CNN网络简称为F,R-FCN网络简称为R。因为图中使用的特征提取网络均为Resnet-101,以下贴出Resnet的网络结构图。Resnet-101的conv5_x的输出是2048维。
F网络中,通过Resnet-101获得2048维特征图,接着是一个ROI pooling层,该层的输入包括2048维特征图和RPN中生成的ROI,输出是size统一的特征图(关于ROI pooling有不清楚的小伙伴,可以移步看一下SPP Net 和ROI pooling的源码解析。),再通过global average pool后接入两个全连接层,最后通过两个分支进行classification和location。在精度上,F为了减少全连接层的计算量,使用了global average pool, 这会导致在一定程度上丢失位置信息;在速度上,F的每一个ROI都要通过R-CNN subnet做计算,这必将引起计算量过大,导致检测速度慢。
R网络在实际使用中,conv5_x的2048维输出要接一个1024维1*1的filter用于降低“厚度”,接着用p*p*(c+1)维1*1的filter去卷积生成position-sensitive score map,也就是图中的彩色部分(从图中看p=9,但是在coco数据集上应用时p=7,所以p*p*(c+1)=3969,这也是本文的一个小漏洞吧),同时将conv4_x的feature map作为RPN的输入,生成ROI,将ROI 和position-sensitive score map共同作为输入,通过PSROI pooling层,得到c+1维p*p的特征图。最后经过一个global average pool层得到c+1维1*1的特征图,这C+1维就是对应该ROI的类别概率信息。相较于F网络,R解决了每个ROI都要通过R-CNN subnet导致重复计算的问题。在精度上,R也使用了global average pool;在速度上,R的head虽然不用计算每一个ROI,但是其需要一个维度非常大的score map,这在一定程度上也会降低检测速度。
关于Faster R-CNN网络和R-FCN网络有不了解的同学,可以移步这里和这里。
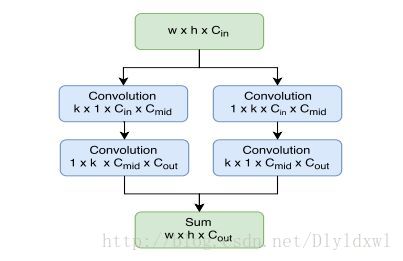
light head RCNN主体和R-FCN差不多。针对R-FCN的score map维度过大的问题,作者用10代替了class,也就是说score map维度变成了10*p*p=490(作者称之为thinner feature map),因此降低了PSROI pooling和fc层的计算量;此外作者使用了large separable convolution代替1*1convolution,示意图如下图所示,可以看出作者借鉴了Inception V3 的思想,将k*k的卷积转化为1*k和k*1,同时采用图中左右两边的方法,最后通过padding融合feature map,得到size不变的特征图。将490维特征图和ROI作为PSROI 的输入则得到10维p*p的特征图,如果将490维特征图和ROI 作为ROI pooling的输入,则得到490维特征图,所以图中写了10 or 490。因为class更改为了10,所以没办法直接进行分类,所以接了个fc层做channel变换,再进行分类和回归。
在本文中,整个网络的架构如下:
特征提取网络使用了L(Resnet-101)和S(Xception)两种类型的网络。RPN网络的输入是conv 4_x,定义了3个aspect ratios{1:2,1:1,2:1}和5个scales{32^2,64^2,128^2,256^2,512^2}(不同与F中3个aspect ratios和3个scales),此外还使用了NMS来降低overlapping,最后得到ROI。conv5_x输出的feature map通过large separable convolution来得到thinner feature map。k设为15,对于L网络cmid=256,对于S网络cmid=64,Cout=10*p*p=490,整个计算的复杂度可以通过Cmid和Cout来控制。将ROI和thinner feature map共同作为PSROI 或ROI pooling的输入,得到10 or 490channels的feature map。R-CNN subnet部分使用了一个channel为2048的fc层来改变前一层的feature map的通道数,最后通过两个fc实现分类和回归。
Experiments
作者的实验主要是基于COCO数据集进行的,object class为80,训练集有80K,验证集有35K,测试集有5K。作者用训练加验证共115K的数据训练,然后用5K的测试集做验证。
baselines
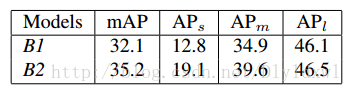
先做了一组R-FCN的实验用于对比,标准的R-FCN记为B1;对R-FCN做一些“增强”:1. image短边resize为800,长边resize为1200,并在RPN部分设置5个scales{32^2,64^2,128^2,256^2,512^2} 2.在RCNN部分回归的loss总是小于分类的,所以将回归的loss翻倍 3. 根据loss排序选取loss最大的256个samples用于反向传播。做了“增强”的R-FCN记为B2,实验结果如下表所示,B2高于B1约3个百分点。
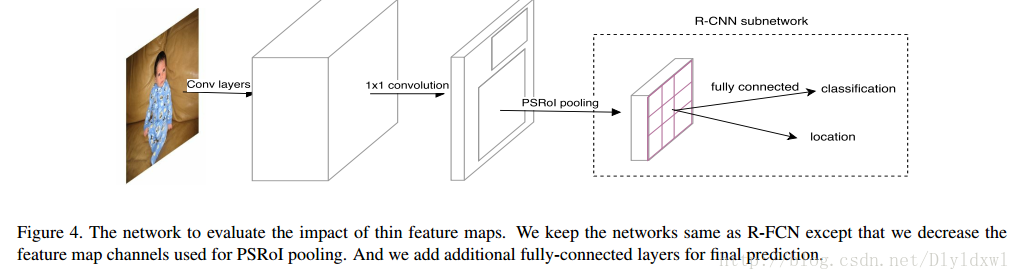
Thinner feature maps for RoI warping
该部分主要用来验证thinner feature map和large separable convolution的作用。
先看thinner feature map。相较于原来的R-FCN,作者使用了如图4的网络,与R-FCN不同的是,该网络的thinner feature map channels为10*p*p=490,R-FCN中score map channels为81*p*p=3969。接着接入同样的PSROI层,因为图4中channel的改变,所以使用了fc层来改变channels以便后续的分类和回归。注意该网络没有使用large separable convolution层,因为要做到“控制变量”,所以两网络只有“score map”的channel的不同。
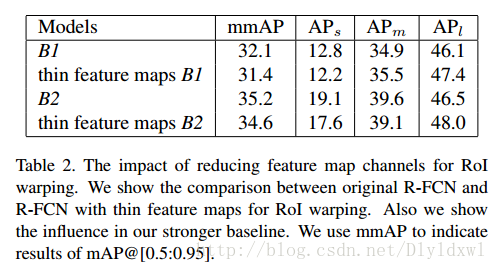
实验结果如下表所示:从表中可以看出,channel数大大降低后精度并没有减小多少,有关速度的提升表中没有说明,但是可想而知。此外,作者在文中强调了light head rcnn的 reduce channel操作让该网络可以和FPN结合,如果使用原来的R-FCN,要和FPN结合(就是对不同scale的层做position-sensitive pooling)其计算量过大会导致内存使用量过大的。
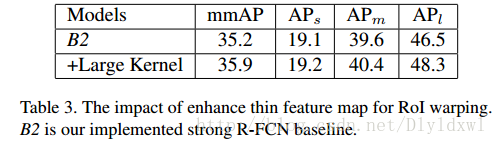
再用large separable convolution代替1*1convolution,实验结果如下表所示,精度略有提升,速度仍然没有写出,但是明显会有较大的提升。
light head R-CNN
将RoI warping和R-CNN subnet结合到一起,也就是light head R-CNN, 对比其和B2、Faster R-CNN(这里的F是作者改进过的网络),如下表所示,最后一行表示light head R-CNN,可以看出map有了一定的提升(这些都是在L网络上实验的)。

在此解释一下,该表格最后两行的区别。有同学会说Thin feature map+large kernal就是整个light head rcnn呀!其实不然,+large kernal是在Table3中出现的,也就是说是以figure4 为基础做出来的,而figure 4 中的 RCNN subnet部分直接将10*7*7的feature map接个81channel的fc作为分类结果(对于cls任务来说)。但是Light head rcnn的RCNN subnet部分却是先使用了一个2048channel的fc,再接81channel的fc用于分类(对于分类层来说),从结果中可以看到提升较为明显。
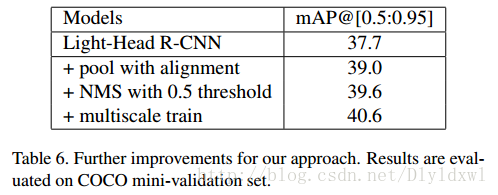
此外作者还做了一组improvements的实验,分别加了pool with alignment、ms train和0.5阈值的NMS,结果如下表所示。
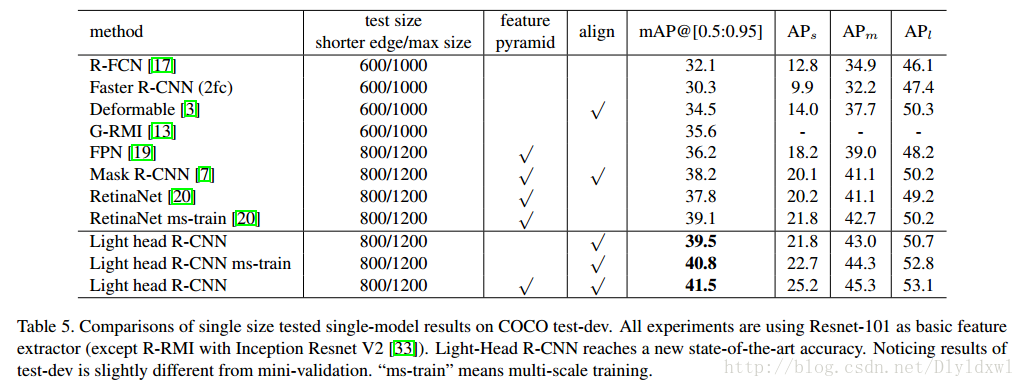
再将light head rcnn与当前主流的检测算法在coco数据集上进行比较,backbone基本都是Resnet-101,结果如下表所示。
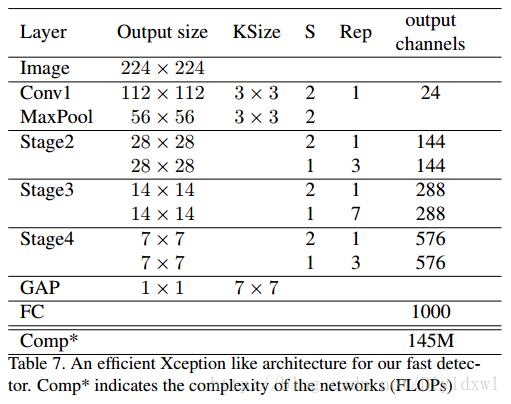
为了突出light head rcnn的速度优势,作者使用了类似与Xception的一个小网络作为backbone,具体结构如表7所示,这里有些细节博主暂时没弄清楚。
接着将小网络的light head rcnn与其他网络进行速度上的对比,如表8所示。
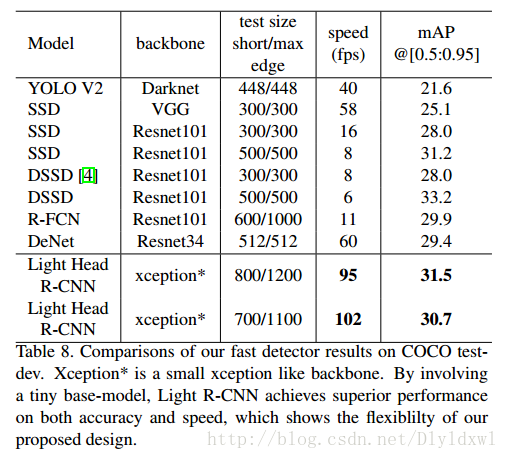
可以看出,light head rcnn要速度有速度,要精度有精度,坐等源码公开了。