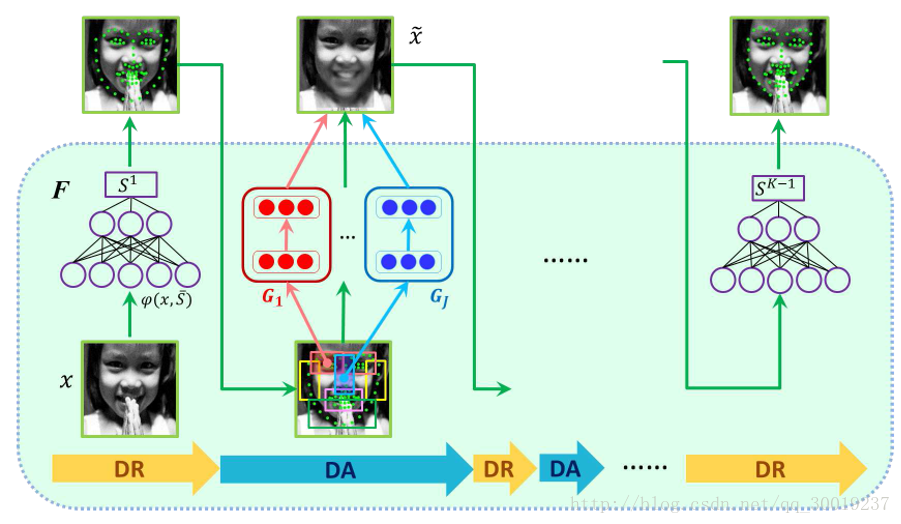
论文方法整体框架图
基本方法流程
- 使用深度回归网络(DR)预测人脸形状 一共三层,前面两层是非线性隐藏层,最后一层是线性回归层。
- 使用去遮挡自编码网络(DA)对当前形状进行遮挡区域恢复(去除遮挡物。
- 恢复后人脸再次作为深度回归网络的输入进行下一轮的预测,反复迭代。
phi 是特征提取函数,基于形状索引的sift特征
Si实际形状 S是初始形状,通过普通人脸检测获得
基本思想:损坏的部分可以从冗余的图像的部分中恢复。
深度回归网络预测人脸形状

目的:特殊化人脸到形状的非线性映射
训练以确定wm和bm参数
fm是第m层的非线性函数
aq是隐藏层q的响应
- 自编码网络恢复遮挡区域
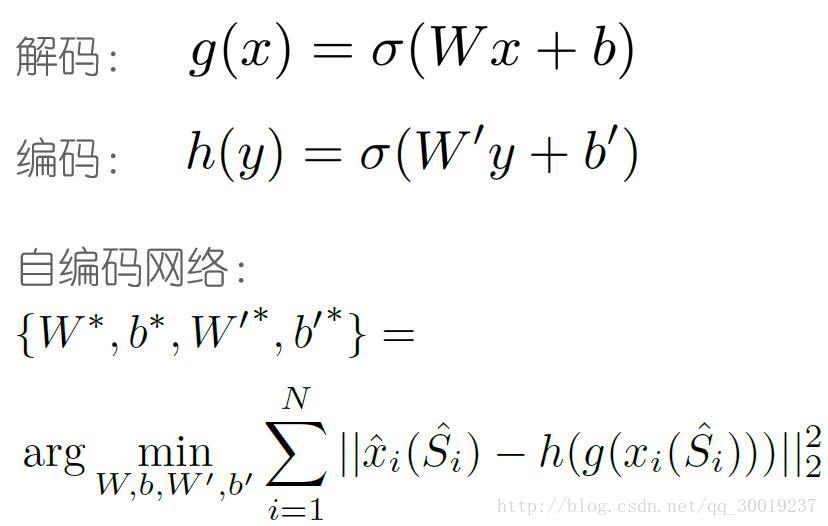
将68个人脸坐标点划分为7个组成部分,针对每一部分设计自编码网络
g:将输入人脸x映射到隐藏表示y
h:将隐藏表示y映射回输入人脸x
将恢复图片gx与被遮挡图片(原图)比较,像素之间差异大于阈值的被看作是遮挡像素,超过30%为遮挡像素的区域被看作是遮挡区域
- 级联深度回归网络与自编码网络

重复三次1 2 两个步骤,形成级联结构,联合每一段的输出,得到最终的人脸形状。
在每次级联之后得到恢复人脸,后再用f*来预测形状增量,累加增量得到最终形状。