
- 这是北京大学深圳研究生院和鹏城实验室的一篇用隐式神经表示做多模态无监督暗图增强的论文,声称被ICCV 2023接受了
- 模型框架如下图所示,由几个模块组成,分别是Mask Extractor,NRN,TAD模块以及类似于cycleGAN的degrade module和enhance module。
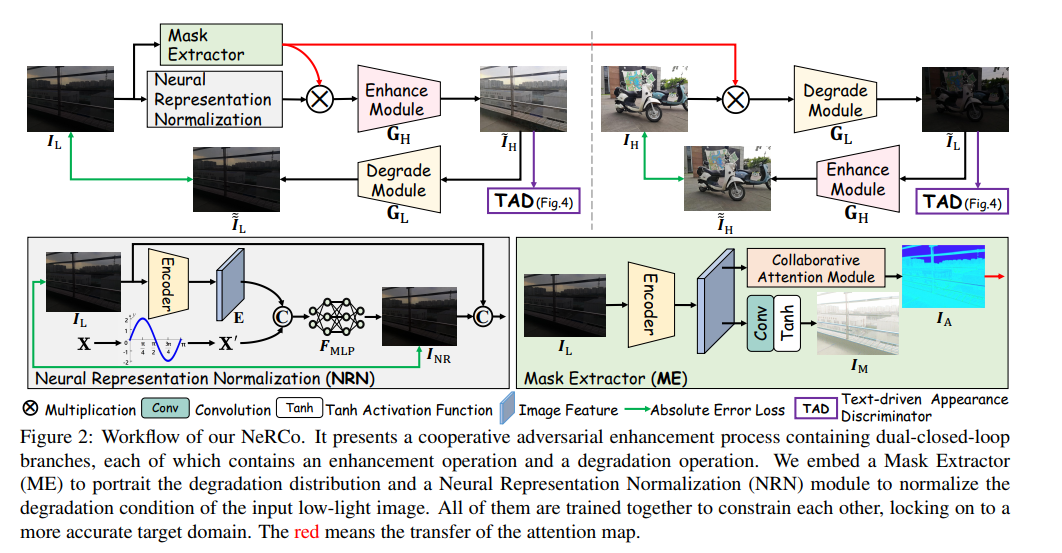
- 说实话我并不理解NRN模块有什么意义。文章认为,concatenate上正弦编码的坐标后,1x1的卷积能够输出一张normaliza后的图片,能够消除一些degradation,并且产生的图片的亮度是数据集的平均亮度。这一过程用 I N R I_{NR} INR和 I L I_L IL之间的L1损失即可监督。可是,这里由没有下采样,那只要我的encoder保持图片内容不变,我的1x1卷积完全不考虑位置编码而直接复刻前面几个通道的输入,我就能完美还原出原图,损失是最小化的,我真不知道这样做有什么意义,文章的解释是说卷积神经网络是个低通滤波器,这点我认可,但并不是低通滤波器就能保证这样的啊,很奇怪,隐式神经表示也不是这样用的吧。
- TAD模块如下图所示,用了CLIP的算法,用low-light image和high-light image这两句话分别作为两个prompt送进CLIP的text encoder产生文本特征,然后算enhance image和degrade image的图像特征与这两个文本特征的cosine similarity作为对比损失,如下。此外还用了discirminator来算GAN的对抗损失,这里用了两个支路,一个是图片送进discriminator,一个是先用高通滤波器提取边缘图再送进discriminator,两个discriminator。对抗损失采用的是cycleGAN的方式,既算增强结果的对抗损失(训练enhancer)和真实亮图的对抗损失(训练discriminator),也算增强后degrade的结果与暗图之间的L1损失(consistency loss),然后另一个方向也是同样的方式算三个损失。
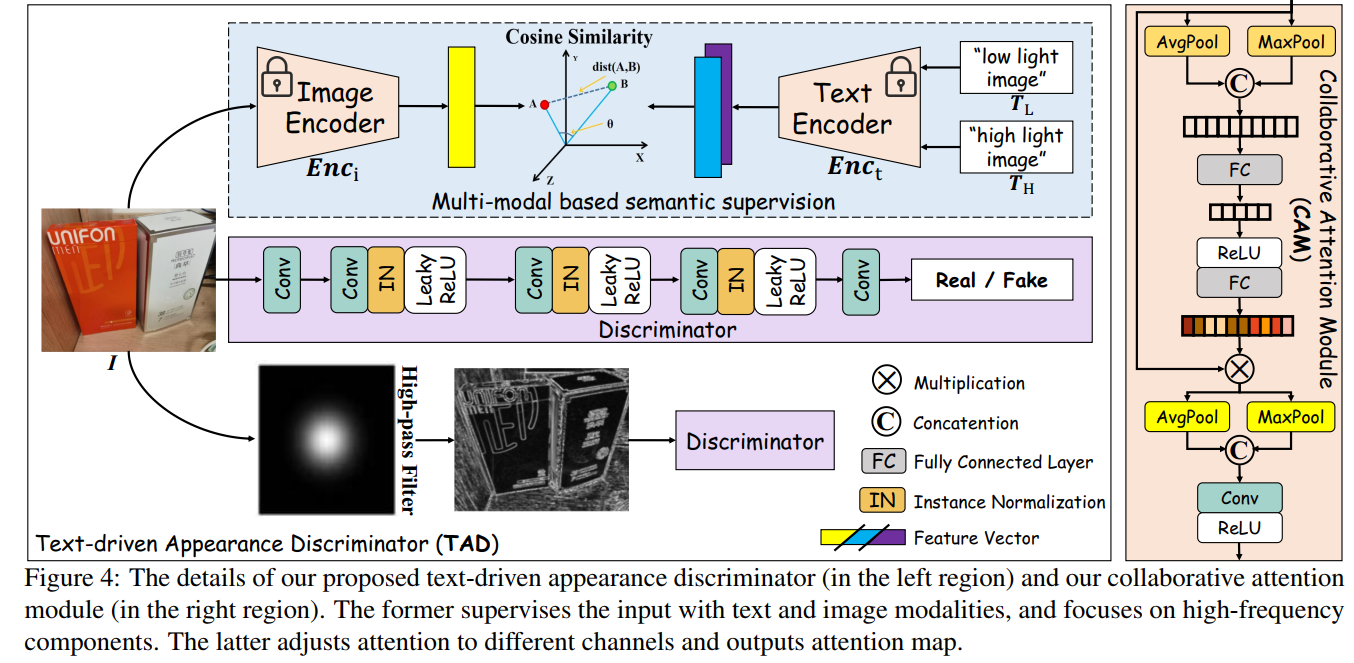
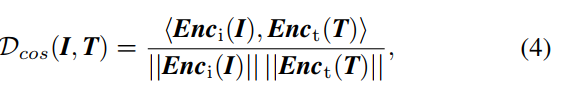
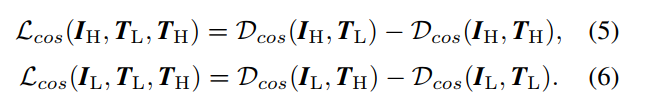
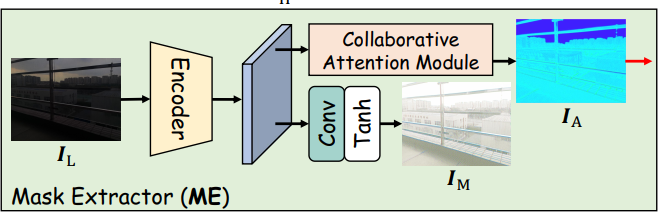
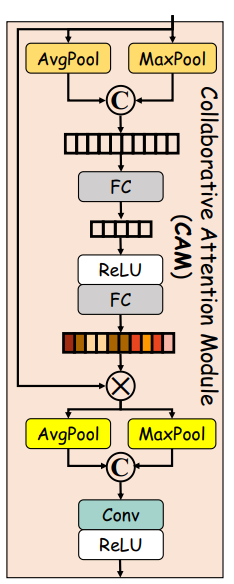
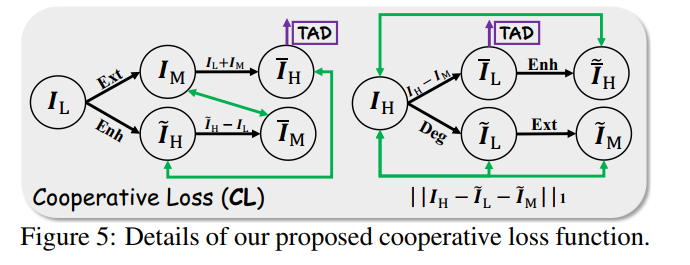
- Mask Extractor模块如下图所示,是因为本文模块过多,为了使得模块能联合训练得很好,引进了一个约束,首先用CAM模块提取了一个attention map I A I_A IA,用来对enhance和degrade之前的图片做注意力,为了监督这个attention map,还提取了一个 I M I_M IM,然后是一些看起来毫无意义的损失函数,实在看不下去了:
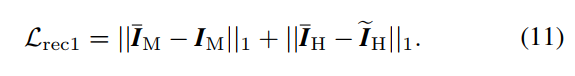
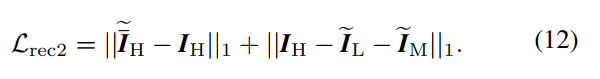
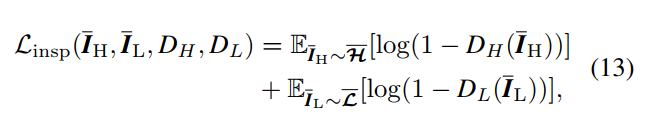
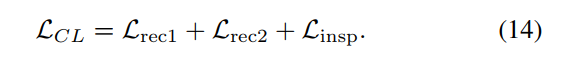
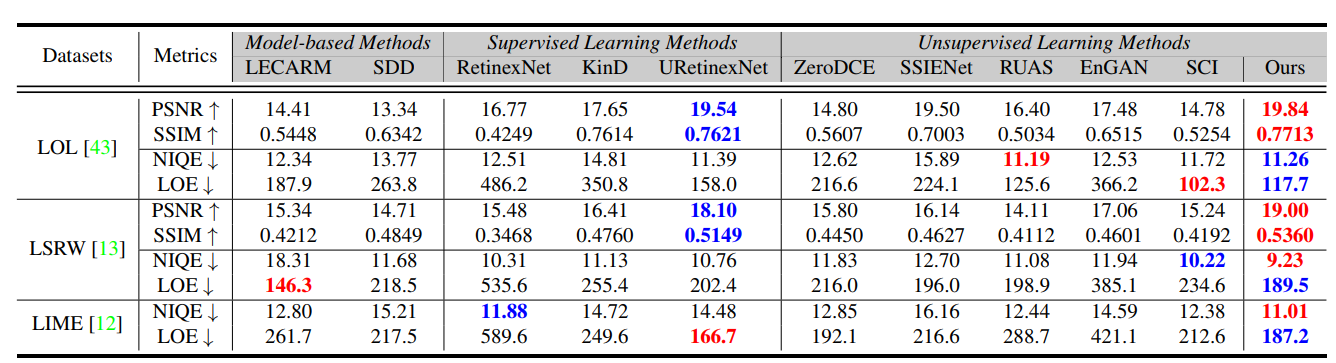
- 实验结果如下图所示,确实是指标上SOTA,可视化效果不错:

- 但是,又是用CLIP,又是NeRV(我强烈质疑NeRV的使用),又是cycleGAN,又是CAM,一堆乱七八糟的东西叠起来,也没看出核心是为了干什么以及用这些有什么意义,损失函数也乱七八糟。