KDD 2019
0 abstract
- 提出了一个深度学习模型,来表征运动员轨迹(play2vec)
- 关于noise很robust
- 只需要线性的时间来计算两个运动员之间的相似程度
1 Intro
- 相似比赛检索(similar play retrieval)是指从数据库中查找与查询Play相似的比赛过程
- 其中Play指的是比赛的片段,其持续时间从几秒钟到几分钟不等。
- 类似比赛检索的核心问题在于衡量两场比赛片段之间的相似性
- 这是一个不容易解决的问题,因为每个比赛都涉及到多条轨迹。
- 目前解决该问题的方案都采用了两步法:
- (1)将一场比赛中的轨迹与另一场比赛中的轨迹进行对齐;
- 在对齐步骤中,考虑了两种策略:
- 第一种是基于枚举的策略,(概念上)考虑了所有可能的对齐方式,并选择了具有最佳相似度得分的对齐方式。
- 在实践中,使用类似匈牙利算法的算法找到两组轨迹之间的最优匹配,其中一对轨迹之间的权重设置为它们之间的相似度
- 第二种是基于角色的策略,首先检测每个隐藏的球员的角色,然后对共享角色的两个球员的轨迹进行对齐
- 在这里,检测到的球员角色可能具有类似于足球比赛中的中锋、中场等语义,并且可能在比赛中随时发生变化。
- 第一种是基于枚举的策略,(概念上)考虑了所有可能的对齐方式,并选择了具有最佳相似度得分的对齐方式。
- 在对齐步骤中,考虑了两种策略:
- (2)使用一些轨迹相似度指标(如动态时间规整(DTW))计算已对齐的每一对轨迹之间的相似度,然后将所有相似度求和为两场比赛之间的总相似度。
- (1)将一场比赛中的轨迹与另一场比赛中的轨迹进行对齐;
- 现有方法的局限性:
- 有效性。
- 之前的方法依赖于这样一个假设:分别检查各个轨迹对,然后使用求和函数将轨迹相似性组合在一起
- 然而这些方法假设每一对轨迹对于两场比赛之间的最终相似度贡献相等,但更符合直觉的是给那些更接近球的轨迹对分配更多的权重。
- 效率
- 这些方法都涉及计算两个轨迹之间的相似度,对于那些众所周知的轨迹相似度度量方法(包括DTW方法),其时间复杂度至少为O(n^2),其中n是较长轨迹的长度。
- 然而相似比赛检索 通常需要计算查询比赛与数据库中许多比赛之间的相似度,而这在实际中是非常巨大的
- 例如,一场典型的足球比赛涉及约414万个采样位置,而英超联赛一个赛季的足球比赛涉及约15.7亿个采样位置
- ——>这个二次时间复杂度会对效率造成很大的挑战
- 鲁棒性
- 采样误差和测量误差
- 坐标上的微小变化可能会导致相似度明显变化
- 有效性。
- 论文使用深度学习在低维空间中表征比赛(play2vec)
- 低维空间中的(欧几里得)距离能更好地捕捉比赛之间的相似性
- 核心思想是将比赛视为一系列具有相同持续时间的play segment的序列,并设计一个去噪序列编码器-解码器(DSED)模型从序列中提取特征向量
- 将每个play segment嵌入为一个向量来实现这一点(视为一个单词或token)
- 将每个比赛视为自然语言上下文中的一句话
- play2vec可以很好地解决上述的三个问题
- 有效性:基于encoder-decoder,这种模型在从序列数据中提取特征方面被广泛认为表现良好。
- 效率:时间复杂度为O(n+d),n是最长轨迹的长度,d是学习到的特征向量的大小
- 鲁棒性:在encoder-decoder中,输入数据会加上噪声以提高鲁棒性;将play segment映射到token的过程中,本身也增加了一定的鲁棒性
2 related works
2.2 轨迹相似度
- DTW是第一次尝试解决计算轨迹相似性时的本地时间移位问题。
- Frechet距离是一种经典的相似性度量方法,将每个轨迹视为一个空间曲线,并考虑采样点的位置和顺序。
- ERP和EDR则是提出为了进一步提高捕捉轨迹空间语义能力的方法。
- ——>然而,这些方法主要是基于匹配采样点的对齐,因此它们对轨迹数据中常见的噪声和不同采样率非常敏感。
- 为解决这个问题,Su等人[26]提出了一种基于锚点的校准系统,将轨迹对齐到一组固定位置。
- Ranu等人[21]提出了一种鲁棒的距离函数称为EDwP,用于匹配具有不一致和可变采样率的轨迹。
- 这些相似性度量通常基于动态规划技术来确定最佳对齐,导致计算复杂度为O(n2),其中n是轨迹长度。
- 最近,Li等人[14]提出了以向量形式学习轨迹表示,然后将两个轨迹之间的相似度量作为它们对应向量之间的欧几里得距离,
- Yao等人[28]则采用深度度量学习来加速轨迹相似性计算。
- 论文与这些研究的区别是,论文的问题是针对比赛(对应于多个轨迹的集合),而这些现有方法是针对单个轨迹的。
- 另一项相关研究是由He等人[11]在道路网络上研究轨迹集相似性,其中利用了Earth Mover's Distance(EMD)的思想来捕捉轨迹的空间和时间特征。
3 问题定义
- 通过参与游戏的物体的移动来建模体育比赛
- 例如,在足球比赛中,这些物体包括来自两个团队的22名球员和一个球
- 物体的运动通常是通过采样其位置来捕捉的,采用了基于GPS设备的跟踪技术
- 因此,物体的运动对应于一系列时间戳位置的序列,称为轨迹
- 轨迹的形式为(x1,y1,t1),(x2,y2,t2),...,其中(xi,yi)是第i个位置,ti是第i个位置的时间戳
- 因此,物体的运动对应于一系列时间戳位置的序列,称为轨迹
- 一个比赛片段对应于多个轨迹的集合,我们称之为play
- 持续时间从几秒钟到几分钟不等,具体取决于用户的需求
- 给定play的数据库D,论文的目标是在d维空间中为每个play P ∈ D学习一个向量表示
,使得play之间的相似性在d维向量空间中被欧氏距离良好地捕捉
- 即对于任何两个play,如果它们相似,则它们向量之间的距离应该很小。

4 方法
- play2vec的核心思想是将每个play分成一系列长度相等的非重叠play段,并设计一个编码器-解码器模型从该序列中提取特征作为向量。
- 首先基于所有play segment构建一个语料库V(第4.1节)
- 然后采用Skip-Gram with Negative Sampling(SGNS)学习语料库V中token的表示(第4.2节)
- 最终使用去噪序列编码器解码器(DSED)模型将play中所有表示粘合在一起,得到一个向量表示v(第4.3节)
一个Play可以由很多段play segment 组成,每段play segment 我们首先将他们归类为一段一段的token,然后使用skip-gram学习这些token 的表征
学习到token的表征后,由于play segment不是等长的,所以使用Encoder-decoder,将encoder的输出作为play的vector表征
4.1 创建体育语料库
- 将球场划分为等大小的格子,得到一个称为“片段矩阵(segment matrix)”的矩阵
- 给定一个由一组轨迹组成的比赛片段,我们将那些被轨迹经过的相应单元格的条目设为1,其余条目设为0

- 由于每个片段矩阵只有二进制值,因此可能的片段矩阵数量有限。
- 一个简单的策略是为每个可能的片段矩阵创建一个唯一的令牌。
- 然而,使用此策略后得到的语料库可能很大,可能会影响后续的表示学习效果。
- 论文逐个扫描segment矩阵,对于每个segment矩阵,仅在其与已扫描的那些片段矩阵不太相似时创建一个新的token。
- 我们使用Jaccard指数来衡量两个片段矩阵M和M'之间的相似度。
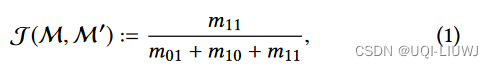
- m11表示M和M'都是1的attribute数量
- m10,m01表示一个是0一个是1的attribute数量

4.2 学习表征
(基本上就是带负采样的skip -gram)
- 将比赛片段(或其相应的token)嵌入为d′维实值向量的方法
- 采用Skip-Gram with Negative Sampling (SGNS) 模型来完成这项任务
- SGNS模型的有效性取决于如何对token的上下文进行建模
- 出现在相同上下文中的segment token往往具有类似的运动场景
- 使用一个token后面和前面的连续segment token作为该token的前瞻上下文和后瞻上下文
- 采用Skip-Gram with Negative Sampling (SGNS) 模型来完成这项任务
- 考虑一个比赛P,它包括了L段比赛片段
- 相当于一个有L个segment token组成的序列:
- 记时刻t的一个m大小的滑动窗口内容
,记作
是目标segment token,
中的其他token都是内容segment token
- 给定一个目标token
和一个内容token C,如果
,那么
是positive的;反之是negative的
- 由于一个segment token 有目标和内容两种角色,所以论文定义了两种向量
,分别表示目标和内容
- ——>我们的目标是学习这些向量,使得我们能够从目标分词中推断出上下文分词的最大概率。
- 相当于一个有L个segment token组成的序列:
- 训练数据
- 包括一系列训练样本
- 每一个训练样本包含一组positive的 token-context 对
是从segment token分布Q(T)中得到的
- Q(T)是一个如下的分布

- 其中α∈[0,1],f(T)是T这个token在语料库中出现的频率
- Q(T)是一个如下的分布
- 每一个训练样本包含一组positive的 token-context 对
- 包括一系列训练样本
- 损失函数

- 第一项(正样本的内积)越大越好;第二项(负样本的内积)越小越好
- 算法流程

4.3 表征粘合
- 将token segment 的表征粘合在一起,以得到对比赛的全面表征
- 提出了一个新的算法框架,称为去噪序列编码器-解码器(Denoising Sequential Encoder-Decoder,DSED)
- 最大化从损坏的初始输入中恢复最可能的真实(或干净)token的概率
- 对于给定的Play 和其对应的token T,生成被损坏的token
- 逐个时间戳扫描比赛中的轨迹的位置,在每个时间戳处保留具有预设概率的位置(舍弃概率为1减去概率的位置,并继续到下一个时间戳)
- 在保留位置的情况下,为每个位置采样一个遵循正态分布N(0,1)的噪声并将噪声添加到位置中
- 基于损坏的轨迹获取一组新的token

【这里使用target 的segment token】
5 实验
5.1 实验配置
5.1.1 实验数据集
- 实验是在真实的足球球员跟踪数据上进行的。
- 该数据包含7500个序列,每个序列包含一个跟踪数据段,对应于最近一个职业足球联赛的实际比赛
- 总计约45场比赛的比赛时间和超过3000万个数据点,已删除冗余和“死亡”情况。
- 每个段落包含三个部分的跟踪数据:11名防守球员,11名进攻球员和一个球。
- 每个部分包含以10Hz的采样频率获得的(x,y)坐标。
- 该数据包含7500个序列,每个序列包含一个跟踪数据段,对应于最近一个职业足球联赛的实际比赛

5.1.2 Baseline
- DTW & Frechet
- 时间序列分析中最广泛采用的两种轨迹相似度度量方法。
- Frechet 是一种基于度量的距离,即距离是对称的并满足三角不等式。
- DTW 距离不是度量,因为它不满足三角不等式。
- 为了衡量两个比赛之间的相似度,采用基于AGENT之间轨迹比较的方法。
- 首先分别基于 DTW 和 Frechet 距离计算两个比赛之间轨迹的代价矩阵
- 然后使用匈牙利算法 计算最优分配方案。
- Chalkboard
- 目前的SOTA
- 通过使用基于角色的表示来克服了agent之间详尽比较的问题,从而实现了轨迹的快速对齐。
- 此外,该方法还采用了有效的模板化和哈希技术来支持用户的交互速度查询。
- EMDT
- 用于研究道路网络上轨迹集的相似性
- 借鉴了地球移动距离的思想,定义了一种新的相似度度量方法。
- 然而,它们的问题场景是在道路网络上,EMDT 的实现部分需要采用地图匹配算法。
- 论文将这种方法调整为将每个单元格的中心点视为道路网络上的节点,并将所有轨迹的采样点映射到其最近的中心点。
5.1.3 参数设置
- 切分segment矩阵的默认大小:3m
- 轨迹的duration时长为1s
- 使用Jaccard指数(阈值为0.3)构建一个体育语料库后,我们获得了50,465个token
- context大小为5
- α=3/4(和skip-gram的负采样对齐)
- 使用2层LSTM作为编码器的计算单元
- token和play的表征维度为20和50
5.2 效果评估
- 缺乏ground-truth使得评估准确性成为一个具有挑战性的问题。
- 为了克服这个问题,论文遵循最近的研究,提出用自相似性,交叉相似性和KNN相似性比较来量化轨迹相似性的准确性。
- 有两个常用的参数:噪声率(半径设置为1米)和采样率(其值从0.2到0.6不等)。
- 这两个参数用于衡量在播放过程中每个轨迹中添加噪声或丢弃采样点的概率。
5.2.1 自相似性比较
- 从数据集中随机选择了50个play作为查询集合(表示为Q),并从数据集中选择了1000个play作为目标数据库(表示为D)
- 对于每个查询集合中的play P ∈ Q,通过随机采样每个轨迹中的20%点,创建了两个子play,分别表示为Pa和Pb
- 使用他们创建了两个子查询数据集Qa = {Pa}和Qb = {Pb}
- 同样,我们从目标数据库D中得到了Da和Db
- 然后,对于每个查询Pa ∈ Qa,我们使用不同的方法计算Pb在数据库Qb∪Db中的排名。
- 理想情况下,Pb应该排在顶部(也即Pb和Pa最像),因为Pa和Pb都来自同一play。

- 为了衡量不同算法对噪声的鲁棒程度,论文对Qa和Qb∪Db 引入了两种不同的噪声
- 1)随机采样一部分点(取决于噪声比例r1),对这些点的坐标加上标准正态分布的噪声
- 2)随机丢弃一定的点(取决于丢弃比例)
- 下面的两个表反应了Pb在Qb∪Db中的平均ranking
- 计算方式为
- 计算方式为


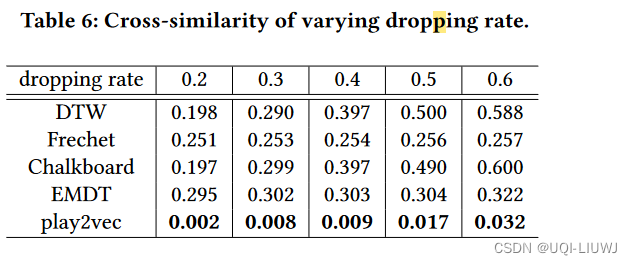
5.2.2 交叉相似性比较
- 好的相似度衡量方式需要保持两个play的距离,不论噪声比例or丢弃比例是多少

- Pa,Pb是原始play,
是有扰动后的play(无论是丢弃点,还是添加噪声)
- 这里随机选取了1000个(Pa,Pb)对

5.2.3 KNN相似性比较
-
首先随机选择了20个play作为查询集,500个plays作为目标数据库
-
针对每个查询使用每种方法找到其Top-K plays作为每种方法的ground-truth
-
然后通过随机删除点或添加噪声来破坏目标数据库中的每个play,并从破坏后的数据库中检索Top-K plays
-
最后将检索到的Top-K plays与ground-truth进行比较,计算精度,即在检索到的Top-K plays中真正的Top-K plays的比例。

5.3 case study

两种方法检索出的top5
