【论文笔记】Semi-supervised Multi-view Deep Discriminant Representation Learning
1. 概念
多视图学习(Multiview Learning)
数据的采集越来越呈现出多源异构特性,在越来越多的实际问题中存在着大量对应着多组数据源的样本,即多视图数据。如果使用单视图(即用所有特征组成一个特征向量),将无法选择一种既适合所有数据类型的普适学习方法,在这种情况下,使用多视图的表示法较为适合,即把数据表示成多个特征集,然后在每个特征集上可以用不同的学习方法进行学习。
深度度量学习(Deep metric learning)
对比损失(Contrastive loss)
在caffe的孪生神经网络(siamese network)中,其采用的损失函数是contrastive loss,这种损失函数可以有效的处理孪生神经网络中的paired data的关系。
F范数(Frobenius norm)
矩阵A的Frobenius范数定义为矩阵A各项元素的绝对值平方的总和开根。
对抗训练(Adversarial training)
在对图像算法研究的过程中发现,一些机器学习方法(包括深度学习)对对抗样本非常敏感,这些对抗样本和非对抗样本非常相似,但是模型(已经在非对抗样本中训练好的模型)却会错分这些样本。为了能更好的分类该类样本,提出了对抗训练的概念。
训练过程使用对抗样本训练,可以使得网络具有防攻击性。
线性模型学习不到阶跃函数,所以对抗训练没有用,只是具有了weight decay效果。
knn 使用对抗训练会过拟合。
神经网络并不脆弱,对抗训练过的神经网络是所有机器学习算法中最能抵抗对抗攻击的。
孪生网络(Siamese network)
Siamese网络分成前半部分、后半部分。前半部分用于特征提取,我们可以让两张图片,分别输入我们这个网络的前半部分,然后分别得到一个输出特征向量Gw(x1)、Gw(x2),接着我们构造两个特征向量距离度量,作为两张图片的相似度计算函数。
伪标签学习(Pseudo-Labelling)
伪标签学习的主旨思想其实很简单。首先,在标签数据上训练模型,然后使用经过训练的模型来预测无标签数据的标签,从而创建伪标签。此外,将标签数据和新生成的伪标签数据结合起来作为新的训练数据。
2. 方法
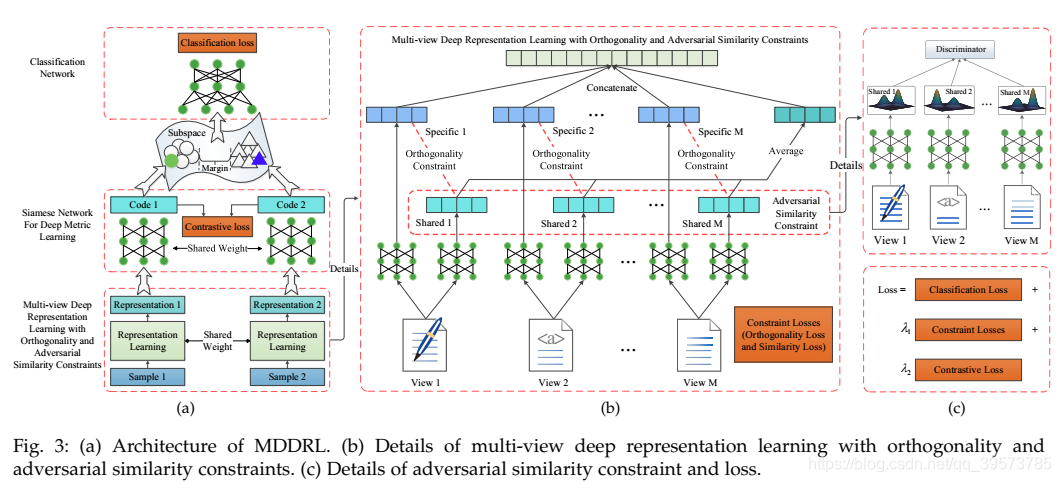
共享和特定表示学习(Shared and Specific Representation Learning)
共享和特定表示学习旨在分别处理视图间共享和视图内特定信息,并为每个视图使用多个特征提取器。
设训练数据为 X = { x i ∈ R d } i = 1 N X=\{x_i\in\mathcal{R}^d\}_{i=1}^N X={
xi∈Rd}i=1N,每一个实例有M个视图,第k个视图为 X k = { x i k ∈ R d k } i = 1 N X^k=\{x_i^k\in\mathcal{R}^{d_k}\}_{i=1}^N Xk={
xik∈Rdk}i=1N,且 d = ∑ k = 1 M d k d=\sum\limits_{k=1}^Md_k d=k=1∑Mdk,对每一个 x i k x_i^k xik我们用两个网络分别将其投影到共享信息子空间和特有信息子空间,共享信息和特有信息分别为 h c , i k = W c k x i k , h s , i k = W s k x i k h_{c,i}^k=W_c^kx_i^k,h_{s,i}^k=W_s^kx_i^k hc,ik=Wckxik,hs,ik=Wskxik。这样 x i k x_i^k xik的表示可以写为:
h i k = ( h c , i k h s , i k ) = ( W c k W s k ) ⋅ x i k h_i^k= \begin{pmatrix}h_{c,i}^k\\h_{s,i}^k\end{pmatrix}=\begin{pmatrix}W_c^k\\W_s^k\end{pmatrix}\cdot x_i^k hik=(hc,ikhs,ik)=(WckWsk)⋅xik
由于不同视图的共享信息几乎相同,所以我们可以对共享表示取平均值:
h c , i = 1 M ∑ l = 1 M h c , i l h_{c,i}=\frac{1}{M}\sum\limits_{l=1}^Mh_{c,i}^l hc,i=M1l=1∑Mhc,il
最后把所有视图的表示综合起来:
h i = [ h c , i T , h s , i 1 T , h s , i 2 T , ⋯ , h s , i k T , ⋯ , h s , i M T ] T h_i=[{h_{c,i}}^T,{h_{s,i}^1}^T,{h_{s,i}^2}^T,\cdots,{h_{s,i}^k}^T,\cdots,{h_{s,i}^M}^T]^T hi=[hc,iT,hs,i1T,hs,i2T,⋯,hs,ikT,⋯,hs,iMT]T
在将多视图示例表示为一个子空间后,我们使用多层网络对其进行分类,并同时训练该分类器和表示学习网络。 交叉熵损失用于分类。
正交约束和对抗相似性约束(Orthogonality and Adversarial Similarity Constraint)
共享和特定方法旨在分别处理视图间共享和视图内特定信息。 但是,这两种信息不会自动分离。 为了分离共享信息和特定信息并减少它们之间的冗余,我们设计了正交性约束和对抗性相似性约束。 正交约束可以解开共享的和特定的信息,并防止它们相互污染。 对抗性相似性约束条件依靠对抗性训练,可以确保共享信息的相似性。
正交损失
为了分离共享信息和特有信息,同个实例同个视图的共享信息和特有信息是不同的,故它的共享表示和特有表示应该是尽可能正交的,设Sk和Hk分别为第k个视图的共享表示和特有表示,则正交损失为:
L d i f f = ∣ ∣ S k T H k ∣ ∣ F 2 L_{diff}=||{S^k}^TH^k||_F^2 Ldiff=∣∣SkTHk∣∣F2
对抗损失
生成共享信息的表示学习网络的任务,是要确保共享信息的相似性,为了使得M个视图得到共享信息高度相似,我们可以将这个网络作为生成器,再引入一个M类分类器作为判别器,进行对抗训练,始得在判别器尽可能正确判别,而生成器尽可能混淆判别,即解约束问题:
L A d v = min θ G max θ D ( ∑ i = 1 N ∑ k = 1 M l i k log D ( G k ( x i k ) ) ) L_{Adv}=\min\limits_{\theta_G}\max\limits_{\theta_D}(\sum\limits_{i=1}^N\sum\limits_{k=1}^Ml_i^k\log{D(G_k(x_i^k))}) LAdv=θGminθDmax(i=1∑Nk=1∑MliklogD(Gk(xik)))
其中 l i k l_i^k lik为 x i k x_i^k xik的真实标签,该问题的解LAdv即为对抗损失。我们同时训练判别器和生成器,直到判别器无法区分从不同视图生成的共享信息之间的差异(此时全部误判,对抗损失为0)。 换句话说,不同视图的共享信息足够相似。
孪生深度度量学习网络(Siamese Network for Deep Metric Learning)
为了增强学习表示的可分辨性,我们在表示学习网络后,加入深度度量学习网络,并通过孪生网络对其进行实现。孪生网络将成对的样本作为输入,如果这对样本类别相同,则孪生网络将其拉近,否则孪生网络会它们推远。具体来说,就是对一对样本xi和xj的表示hi和hj,孪生网络将他们投影为codei和codej,在这个空间中,两个样本的距离为:
d ( x i , x j ) = ∣ ∣ c o d e i − c o d e j ∣ ∣ 2 d(x_i,x_j)=||code_i-code_j||^2 d(xi,xj)=∣∣codei−codej∣∣2
孪生网络的损失函数为对比损失:
L = 1 2 N ∑ n = 1 N [ y n d n 2 + ( 1 − y n ) m a x 2 ( M a r g i n − d n , 0 ) ] L=\frac{1}{2N}\sum\limits_{n=1}^N[y_nd_n^2+(1-y_n)max^2(Margin-d_n,0)] L=2N1n=1∑N[yndn2+(1−yn)max2(Margin−dn,0)]
传统的孪生网络在选择输入对上是随机的,这样会导致对比损失波动很大,不仅增加了获得稳定结果的难度,还会影响性能。为此,我们对每次迭代,随机选取样本数量为m的一批数据,使用每个样本关于类中心的距离来计算损失,即:
L C o n = 1 2 m ∑ i = 1 m { ( x i − μ s a m e ) 2 + m a x 2 [ M a r g i n − ( x i − μ d i f f ) , 0 ] } L_{Con}=\frac{1}{2m}\sum\limits_{i=1}^m\{(x_i-\mu_{same})^2+max^2[Margin-(x_i-\mu_{diff}),0]\} LCon=2m1i=1∑m{
(xi−μsame)2+max2[Margin−(xi−μdiff),0]}
其中 μ s a m e \mu_{same} μsame是这批数据中与xi同类样本的样本中心, μ d i f f \mu_{diff} μdiff是不同类。
这样改进收敛速度快于传统方法,原因是:
- 一批样本的平均值比随机选择的样本更稳定。
- 在欧氏空间中,每个类别的类中心收敛于样本平均值。当每个样本都有稳定目标时,损失收敛更快。
3. 流程
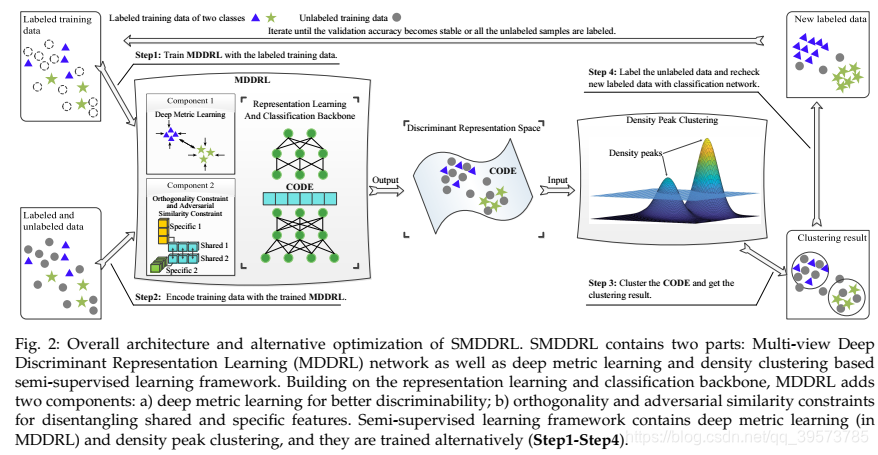
如图二所示,整个程序的主要由两部分构成:
- 由多视图表示学习网络和深度度量学习网络以及分类网络组成的多视图深度判别表示学习(MDDRL)网络
- 基于半监督学习框架的密度聚类
对模型的训练主要包括四个基本步骤:
- 使用标记数据训练MDRRL模型,并计算分类准确率
- 使用训练好的MDDRL模型,对标记数据和未标记数据进行编码,获得表示CODE
- 使用密度聚类对CODE进行聚类
- 使用聚类的结果,对标记未标记数据
为了提高准确率,我们对新的(伪)标记数据,我们使用MDDRL中分类网络对其进行检查,且只保留那些分类和标记一致的样本,之后把保留的样本和原有的标记样本放在一起。重复以上步骤,直到分类准确率不再提高或者所有的未标记数据都被标记了。


4. 使用LSTM尝试网页分类
数据来源:http://www.cs.cmu.edu/afs/cs/project/theo-11/www/wwkb/
import os, nltk, csv, re, pandas, numpy
from bs4 import BeautifulSoup
from sklearn.model_selection import train_test_split
import seaborn as sns
from sklearn import metrics
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from keras.models import Model
from keras.layers import LSTM, Activation, Dense, Dropout, Input, Embedding
from keras.optimizers import RMSprop
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras.callbacks import EarlyStopping
from matplotlib.font_manager import FontProperties
import pickle
from keras.models import load_model
# python -m nltk.downloader punkt
course = os.listdir("../data/002_course-cotrain-data/fulltext/course/")
non_course = os.listdir("../data/002_course-cotrain-data/fulltext/non-course/")
1. 提取数据
- 读取网页文件
- 提取网页中的名词
- 将结果保存到csv文件
参考链接:nltk 英文词性分析
def write_fulltext_inlink(label,prefix,urls,output,mod="w"):
## Python2
# writer = open(output,"w")
# Python3
with open(output,mod,newline='',encoding="utf-8") as csv_file:
writer = csv.writer(csv_file)
if mod == "w":
writer.writerow(["label","url","cutword","cutwordnum","inlink_cutword","inlink_cutwordnum"])
for url in urls:
fulltext = BeautifulSoup(open(os.path.join(os.path.abspath(prefix),"fulltext",label,url),"rb"),features='html.parser')
msg = fulltext.get_text()
tokens=nltk.word_tokenize(msg)
pos_tags = nltk.pos_tag(tokens)
word_list = ""
cutwordnum = 0
for word,pos in pos_tags:
if (pos in ['NN','NNP','NNS','NNPS']):
if len(word) > 1:
word_list += word+" "
cutwordnum += 1
inlink = BeautifulSoup(open(os.path.join(os.path.abspath(prefix),"inlinks",label,url),"rb"),features='html.parser')
msg = inlink.get_text()
tokens=nltk.word_tokenize(msg)
pos_tags = nltk.pos_tag(tokens)
inlink_word_list = ""
inlink_cutwordnum = 0
for word,pos in pos_tags:
if (pos in ['NN','NNP','NNS','NNPS']):
if len(word) > 1:
inlink_word_list += word+" "
inlink_cutwordnum += 1
writer.writerow([label,url,word_list,cutwordnum,inlink_word_list,inlink_cutwordnum])
write_fulltext_inlink("course","../data/002_course-cotrain-data/",course,"../output/002_fulltext_inlink.csv")
write_fulltext_inlink("non-course","../data/002_course-cotrain-data/",non_course,"../output/002_fulltext_inlink.csv",mod="a")
2. 准备数据
- 通过pandas读取数据
- 去掉单词数少于10的数据
- 使用sklearn将数据拆分
- 数据编码
- 保存编码
参考链接:dataframe 按条件筛选行;基于sklearn和keras的数据切分与交叉验证;数据编码
fulltext = pandas.read_csv("../output/002_fulltext_inlink.csv")
data = fulltext.loc[fulltext['cutwordnum']>=1]
seed = numpy.random.seed()
X_train, X_test, y_train, y_test = train_test_split(data["cutword"], data["label"], test_size=0.5, random_state=seed)
## 对数据集的标签数据进行编码
le = LabelEncoder()
y_train = le.fit_transform(y_train).reshape(-1,1)
y_test = le.transform(y_test).reshape(-1,1)
## 对数据集的标签数据进行one-hot编码
ohe = OneHotEncoder()
y_train = ohe.fit_transform(y_train).toarray()
y_test = ohe.transform(y_test).toarray()
## 使用Tokenizer对词组进行编码
## 当我们创建了一个Tokenizer对象后,使用该对象的fit_on_texts()函数,以空格去识别每个词,
## 可以将输入的文本中的每个词编号,编号是根据词频的,词频越大,编号越小。
max_words = 5000
max_len = 500
if os.path.isfile("../output/002_tok.pickle"):
# loading
with open('../output/002_tok.pickle', 'rb') as handle:
tok = pickle.load(handle,encoding="utf-8")
else:
tok = Tokenizer(num_words=max_words) ## 使用的最大词语数为5000
tok.fit_on_texts(X_train)
## 对每个词编码之后,每句新闻中的每个词就可以用对应的编码表示,即每条新闻可以转变成一个向量了:
X_train_seq = tok.texts_to_sequences(X_train)
X_test_seq = tok.texts_to_sequences(X_test)
## 将每个序列调整为相同的长度
X_train_seq_mat = sequence.pad_sequences(X_train_seq,maxlen=max_len)
X_test_seq_mat = sequence.pad_sequences(X_test_seq,maxlen=max_len)
if not os.path.isfile("../output/002_tok.pickle"):
with open('../output/002_tok.pickle', 'wb') as handle:
pickle.dump(tok, handle, protocol=pickle.HIGHEST_PROTOCOL)
else:
pass
3. 训练神经网络
- 定义LSMT模型
- 模型训练
- 保存模型
参考链接:LSMT文本分类
if not os.path.isfile("../output/002_lstm_web_classify.h5"):
## 定义LSTM模型
inputs = Input(name='inputs',shape=[max_len])
## Embedding(词汇表大小,batch大小,每个新闻的词长)
layer = Embedding(max_words+1,128,input_length=max_len)(inputs)
layer = LSTM(128)(layer)
layer = Dense(128,activation="relu",name="FC1")(layer)
layer = Dropout(0.5)(layer)
layer = Dense(2,activation="softmax",name="FC2")(layer)
model = Model(inputs=inputs,outputs=layer)
model.summary()
model.compile(loss="categorical_crossentropy",optimizer=RMSprop(),metrics=["accuracy"])
## 模型训练
model_fit = model.fit(X_train_seq_mat,y_train,batch_size=128,epochs=10,
validation_data=(X_test_seq_mat,y_test),
callbacks=[EarlyStopping(monitor='val_loss',min_delta=0.0001)] ## 当val-loss不再提升时停止训练
)
model.save("../output/002_lstm_web_classify.h5")
else:
model = load_model("../output/002_lstm_web_classify.h5")
Model: "model_8"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
inputs (InputLayer) (None, 500) 0
_________________________________________________________________
embedding_8 (Embedding) (None, 500, 128) 640128
_________________________________________________________________
lstm_8 (LSTM) (None, 128) 131584
_________________________________________________________________
FC1 (Dense) (None, 128) 16512
_________________________________________________________________
dropout_8 (Dropout) (None, 128) 0
_________________________________________________________________
FC2 (Dense) (None, 2) 258
=================================================================
Total params: 788,482
Trainable params: 788,482
Non-trainable params: 0
_________________________________________________________________
Train on 525 samples, validate on 525 samples
Epoch 1/10
525/525 [==============================] - 12s 23ms/step - loss: 0.7011 - accuracy: 0.7390 - val_loss: 0.7490 - val_accuracy: 0.7695
Epoch 2/10
525/525 [==============================] - 11s 20ms/step - loss: 0.5692 - accuracy: 0.7924 - val_loss: 0.4819 - val_accuracy: 0.7695
Epoch 3/10
525/525 [==============================] - 12s 23ms/step - loss: 0.3839 - accuracy: 0.7981 - val_loss: 0.4397 - val_accuracy: 0.7848
Epoch 4/10
525/525 [==============================] - 11s 22ms/step - loss: 0.2587 - accuracy: 0.8667 - val_loss: 0.3248 - val_accuracy: 0.8610
Epoch 5/10
525/525 [==============================] - 12s 23ms/step - loss: 0.1236 - accuracy: 0.9695 - val_loss: 0.3096 - val_accuracy: 0.9105
Epoch 6/10
525/525 [==============================] - 12s 22ms/step - loss: 0.0504 - accuracy: 0.9886 - val_loss: 0.1998 - val_accuracy: 0.9333
Epoch 7/10
525/525 [==============================] - 12s 23ms/step - loss: 0.0290 - accuracy: 0.9943 - val_loss: 0.2182 - val_accuracy: 0.9257
4. 模型测试
使用metrics.classification_report对模型进行评估
y_pre = model.predict(X_test_seq_mat)
res = metrics.classification_report(numpy.argmax(y_pre,axis=1),numpy.argmax(y_test,axis=1))
print(res)
regex = re.compile('\s\s+')
w_f1 = regex.split(res)[-2]
print("weighted f1-score: %s"%w_f1)
precision recall f1-score support
0 0.83 0.84 0.84 120
1 0.95 0.95 0.95 405
accuracy 0.93 525
macro avg 0.89 0.90 0.89 525
weighted avg 0.93 0.93 0.93 525
weighted f1-score: 0.93