本文是词法分析的第三篇文章。之前的第一篇文章介绍了词法单元、模式和词素的三者间的关系,以及正则表达式;第二篇文章介绍了有穷自动机,以及如何把NFA转换成等价的DFA。本文首先将介绍如何把一个正则表达式转换成一个有穷自动机,接着会给出一个最小化DFA状态数的算法,最后会回顾整个词法分析过程。
从正则表达式到有穷自动机
对我们来说,用正则表达式描述一种语言是十分方便的。比如说[a-zA-Z]可以表示所有大小写字母,[abc]owo[xyz]可以表示所有长度为5,以a、b、c中的一个字母开头,接着owo三个字母,并以x、y、z中的一个字母结尾的字符串。但是,机器没办法直接识别一个抽象的正则表达式。为此,我们需要把正则表达式转换成一个有穷自动机。
如何把一个正则表达式转换成有穷自动机,其实有三种选择:
- 直接转换成一个NFA;
- 直接转换成一个DFA;
- 先转换成一个NFA,再把这个NFA转换成DFA。
由于把NFA转换成DFA已经介绍过了,因此我们把重点放在前两种方式上。
把正则表达式转换成NFA
我们先来回顾一下正则表达式的递归构建规则:
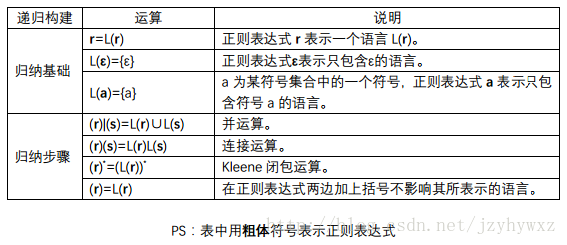
为了把正则表达式转换成NFA,我们需要把正则表达式的递归构建规则用相应的流图表示:
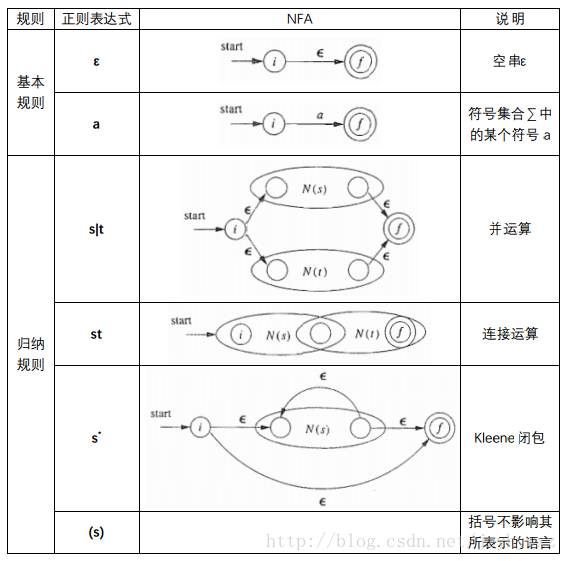
注意到,在每个NFA中,都会引入两个新状态——初始状态和终止状态。下面给出将正则表达式转换成一个NFA的McMaughton-Yamada-Thompson算法:
- 输入:符号集合∑上的一个正则表达式r;
- 输出:一个接受L(r)的NFA N;
- 方法:首先分解出r的每个子表达式,接着按照正则表达式-NFA转换表对每个子表达式得到对应的子NFA,最后合并所有的子NFA得到N。
现在我们可以利用McMaughton-Yamada-Thompson算法将正则表达式r=(a|b)*a转换成一个NFA:
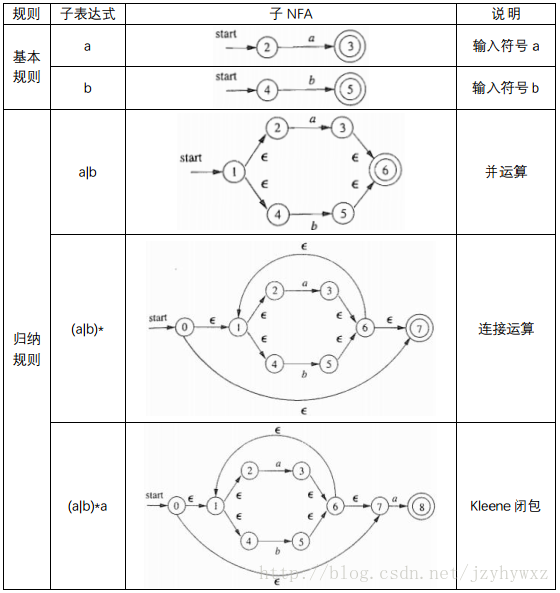
把正则表达式转换成DFA
现在我们已经知道了如何把一个正则表达式转换成一个NFA,但是得到的NFA中可能有多余的转换,一个典型的例子就是ε转换,换言之,NFA中可能有多余的状态,因此我们需要判断NFA的某个状态是否是必须的。
NFA的重要状态是有一个标号不为ε的转换(出边)的状态。因此,以输入符号作为转换标记的状态都是重要状态。另外,NFA的终止状态也应该是一个重要状态,但是它并没有一个离开转换,因此,可以扩展正则表达式r,在其后加上一个特殊的终止符号#,形成一个扩展的正则表达式(r)#,这样NFA的终止状态也成为了一个重要状态。
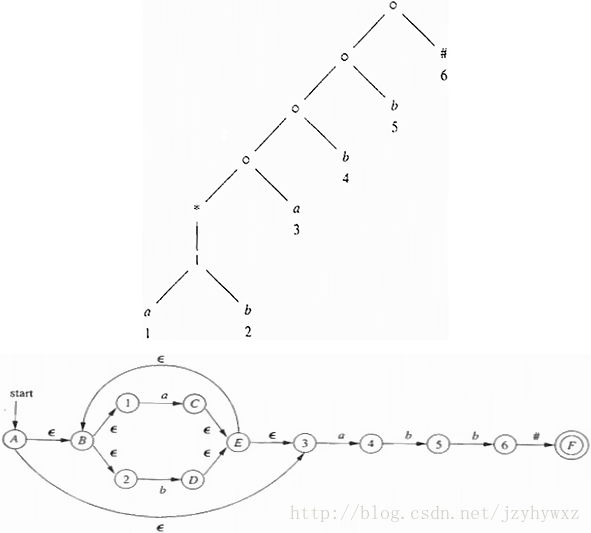
为了说明重要状态对构建DFA的作用,先把正则表达式转换成抽象语法树。一棵抽象语法树包括:
- 叶子结点:表示字符集合中的符号,包括扩展的#结尾符号;
- 内部结点:表示正则表达式中的运算符,并、连接、闭包运算分别称为cat、or、star结点,并分别用○、|、*表示;
- 结点位置:对每个标号不为ε的叶子结点,自底向上、从左到右的自1开始顺序编号。被编号的结点对应于NFA中的重要状态,编号的号码代表重要状态在NFA中的位置。
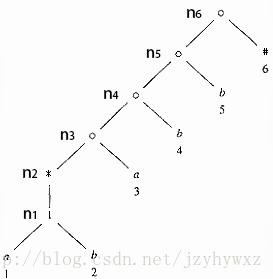
对于正则表达式(a|b)*abb,它的抽象语法树和其对应的NFA如下,其中的重要状态用结点位置编号,非重要状态用大写字母编号:
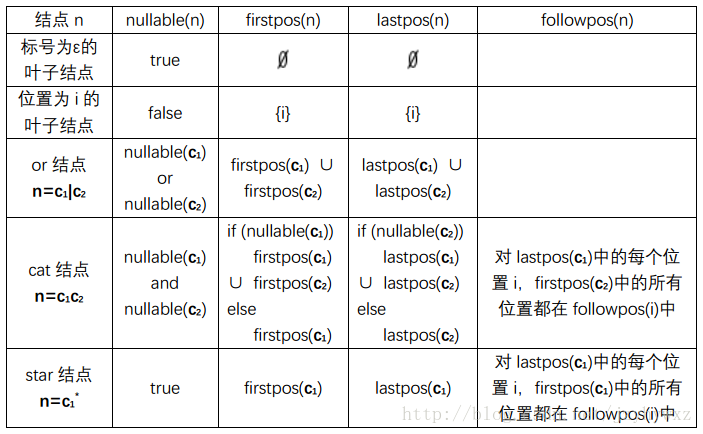
有了抽象语法树以后,需要对每个结点计算四个函数,定义Rn是以结点n为根的子树,L(Rn)是Rn对应的表达式能够描述的语言:
nullable(n):如果L(Rn)中包括空串ε,返回true,否则返回false;firstpos(n):返回一个位置集合,这些位置是L(Rn)中的某个串的第一个符号的位置;lastpos(n):返回一个位置集合,这些位置是L(Rn)中的某个串的最后一个符号的位置;followpos(n):返回一个位置集合,这些位置是跟在L(Rn)中的某个串之后的符号的位置。
上述四个函数的计算规则可以总结为下表:
仍以正则表达式(a|b)*abb为例,计算这四个函数,为了方便指明是哪个结点,我们在其抽象语法树中用n1-n6标注内部结点:
以自底向上、从左到右的顺序计算其四个函数,结果如下:
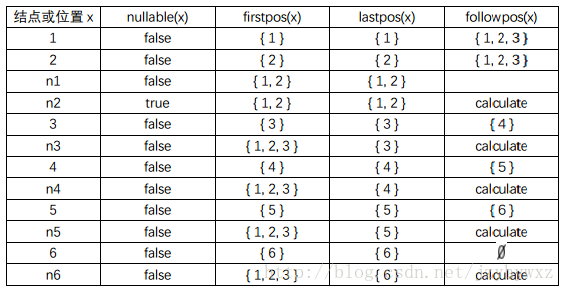
注意到,只有n2的nullable函数返回true,因为n2是一个star结点;另外,followpos函数只会在cat结点和star结点处计算,并把结果赋给叶子结点,表项为calculate表示计算followpos函数。
现在可以根据上表构建出一个DFA了。对于这个DFA D,需要计算它的状态集Dstates和转换函数Dtran(转换表)。D的初始状态是firstpos(n6)(n6是根结点),然后用下面的方法计算其Dstates和Dtran:

D的初始状态是firstpos(n6)={ 1, 2, 3 },称其为状态A,我们需要计算Dtran[A, a]和Dtran[A, b]。在{ 1, 2, 3 }中,位置1和3处的标号为a,位置2处的标号为b,Dtran[A, a]=followpos(1)∪followpos(3)={ 1, 2, 3, 4 },Dtran[A, b]=followpos(2)={ 1, 2, 3 }。由于Dtran[A, a]产生了一个新状态,称其为状态B,因此需要继续计算,而Dtran[A, b]与状态A相同,就不用再计算了。最后的结果见下表:
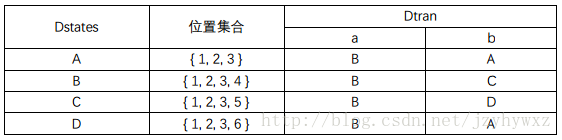
这样就从正则表达式(a|b)*abb构建得到了一个DFA:

现在我们正式给出由一个正则表达式构建DFA的算法:
- 输入:一个正则表达式r;
- 输出:一个识别L(r)的DFA D;
- 方法:首先根据扩展的正则表达式(r)#构建一棵抽象语法树T,接着计算T的nullable、firstpos、lastpos和followpos函数,最后根据这四个函数的结果构造D的状态集Dstates和转换函数Dtran。
最小化DFA的状态数
对同一个语言来说,可能存在多个识别此语言的DFA。例如对正则表达式(a|b)*abb,下面两个DFA都能识别它:
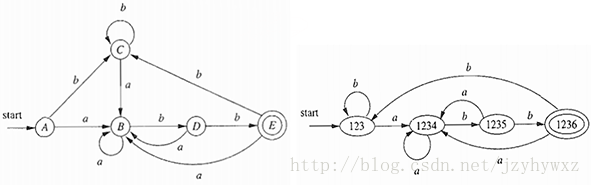
这两个DFA不仅每个状态的名字不同,而且连状态数也不一样。实际上,任何正则语言都有一个唯一的状态数目最少的DFA,本节就将介绍如何把一个DFA的状态数最小化。
在一个DFA中,如果有这样两个状态:
- 都不是终止状态;
- 对任意输入总是转移到同一个状态。
那么这两个状态是等价的。例如在上面提到的正则表达式(a|b)*abb的左边的DFA中,状态A和C是等价的,因为它们都不是终止状态,并且对输入a都转移到状态B,对输入b都转移到状态C。
这就给出了一个最小化DFA状态数的思路——把等价的状态合并。因此我们有下面的算法:
- 输入:一个DFA D1,其状态集合是S,输入符号集合为∑,初始状态为s0,终止状态集合为F;
- 输出:一个DFA D2,它和D1接受相同的语言,且状态数最少;
方法:
- 构造包含两个组F和S-F的初始划分∏,这两个组分别是D1的终止状态组和非终止状态组;
- 应用下图中的方法构造新的分划∏new:
- 如果∏new=∏,令∏final=∏并跳到步骤4,否则重复步骤2;
- 在分划∏final的每个组中选一个状态作为该组的代表,这些代表构成了D2的状态集。D2的初始状态是包含D的初始状态组的代表,D2的终止状态是包含D的终止状态组的代表。令s是∏final中某个组的代表,在D1中从s经输入a到达状态t,令r是t所在组的代表,则在D2中有一个从s经输入a到达r的转换。

对于上面给出的正则表达式(a|b)*abb左边的DFA,最小化其状态数的过程如下:
- 初始分划∏为{ A, B, C, D }和{ E }两个组,分别是非终止状态组和终止状态组;
- 在∏中,{ E }无法再分,需要对{ A, B, C, D }进行划分。对输入a,A、B、C、D都转移到B;对输入b,A和C转移到C,B转移到D,D转移到E,由于A、B、C对输入b都转移到同一个组{ A, B, C, D }中的状态,而D对输入b转移到另一个组{ E }中的状态,因此把{ A, B, C, D }划分成{ A, B, C }和{ D }。此时∏new为{ A, B, C }、{ D }和{ E };
- 在∏new中,需要对{ A, B, C }进行划分。对输入a,A、B、C都转移到B;对输入b,A和C转移到C,B转移到D,因此把{ A, B, C }划分成{ A, C }和{ B }。此时∏new为{ A, C }、{ B }、{ D }和{ E };
- 在∏new中,此时所有组都不能再分,因此此时的∏new就是∏final。合并状态A和C后得到的状态数最少的DFA就是右边的DFA。
词法分析过程
到此,我们已经介绍了和词法分析相关的大部分内容,包括基本的词法单元、模式和词素,到正则表达式,再到有穷自动机,最后是从正则表达式转换到有穷自动机,现在简单回顾一下整个词法分析的过程:
- 首先,对某个正则语言L,构造能够描述其的正则表达式r;
- 然后,需要将r转换成一个有穷自动机。这里有三种方法,一是直接转换成NFA,而是直接转换成DFA,三是先转换成NFA,再把NFA转换成DFA;
- 最后,如果将r转换成了一个DFA,需要将此DFA的状态数最小化。

欢迎关注微信公众号fightingZh(*๓´╰╯`๓)